Apache kylin是一个开源分布式引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据。而superset是airbnb开源的一款数据可视化工具。
kylin在超大数据规模下仍然可以提供秒级甚至毫秒级sql响应的OLAP多维分析查询服务。而且对服务器内存的要求也不像spark sql那么高,经过多方面的优化,数据膨胀率甚至可以控制在100%以内。它利用hive做预计算,然后建立多维的数据立方体,并存在hbase中,从而提供了实时查询的能力。
superset也就是早先的caravel,提供了丰富的图表供用户配置。只要连上数据源,勾几个简单的配置,或者写点sql。用户就可以轻易的构建基于d3、nvd3、mapbox-gl等的炫酷图表。
我厂也是选择了kylin和superset,遗憾的是superset支持多种数据源,包括druid、hive、impala、sparkSQL、presto以及多种主流关系型数据库,但是并不支持kylin。于是我们对其进行了改进。
首先观察superset的源码,它后台使用Flask App Builder搭建的,数据访问层用sqlalchemy实现。也就是说,它本质上可以支持所有数据源,只要实现一套kylin的dialect即可。而同时github上有一个pykylin项目,就是实现的这个dialect。这极大增强了我解决这个问题的信心。
正好前几周,superset出了一个新的prod版本airbnb_prod.0.15.5.0。装好它和pykylin之后,导入kylin数据源,成功!
但是点开sqllab想敲点sql验证一下时,却出了异常。

Debug了pykylin代码,发现get_table_names方法的入参connection实际已经是sqlalchemy的Engine对象了,这可能是最新sqlalchemy的版本升级造成的。总之,将原来的代码:
- def get_table_names(self, connection, schema=None, **kw):
- return connection.connection.list_tables()
改成:
- def get_table_names(self, engine, schema=None, **kw):
- connection = engine.contextual_connect()
- return connection.connection.list_tables()
即可。
顺便我们看到这里它扩展了sqlalchemy的list_tables方法,sqllab左上方的table选择区还有列出所有schema的下拉框,于是我们顺带把list_schama方法也实现。connection.py添加:
- def list_schemas(self):
- route = 'tables_and_columns'
- params = {'project': self.project}
- tables = self.proxy.get(route, params=params)
- return [t['table_SCHEM'] for t in tables]
dialect.py添加:
- def get_schema_names(self, engine, schema=None, **kw):
- connection = engine.contextual_connect()
- return connection.connection.list_schemas()
之后执行sql还是有错:
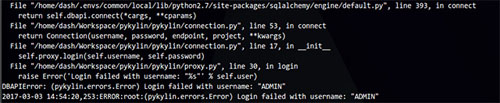
pykylin在每次调用kylin的api时会首先登录,以获得JSESSIONID,并存入cookie中,这里是登录失败,检查代码,发现这里问题还挺多的,首先proxy.py中的login方法作者写的是self.password = user应改成password。dialect.py中create_connect_args方法改为:
- def create_connect_args(self, url):
- opts = url.translate_connect_args()
- api_prefix = 'kylin/api/'
- args = {
- 'username': opts['username'],
- 'password': opts['password'],
- 'endpoint': 'http://%s:%s/%s' % (opts['host'], opts['port'], api_prefix)
- }
- args.update(url.query)
- return [], args
这样大部分sql查询没有问题,但是有的查询结果有部分值是null,这样也会出错。修改cursor.py的_type_mapped方法:
- def _type_mapped(self, result):
- meta = self.description
- size = len(meta)
- for i in range(0, size):
- column = meta[i]
- tpe = column[1]
- val = result[i]
- if val is None:
- pass
- elif tpe == 'DATE':
- val = parser.parse(val)
- elif tpe == 'BIGINT' or tpe == 'INT' or tpe == 'TINYINT':
- val = int(val)
- elif tpe == 'DOUBLE' or tpe == 'FLOAT':
- val = float(val)
- elif tpe == 'BOOLEAN':
- val = (val == 'true')
- result[i] = val
- return result
这样在sqllab中执行sql基本没问题了。
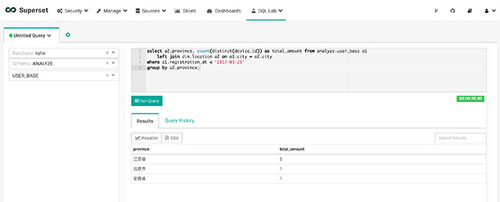
下一步开始自定义slice,定制自己的可视化dashboard。
在这里再次遇到问题,superset会自动把count函数计算的列设置别名叫count,而count是kylin的关键字,因此导致查找失败。修改superset的models.py的sqla_col方法:
- @property
- def sqla_col(self):
- name = self.metric_name
- if name == 'count':
- name = 'total_count'
- return literal_column(self.expression).label(name)
另外在slice中还经常会遇到pandas抛出的KeyError异常。这是因为在superset里面所有的关键字都是小写,然而kylin返回的所有的数据metadata全是大写,导致superset在kylin的返回结果中查询关键字的时候出现找不到关键字的错误。
修改pykylin的cursor.py的execute方法。
- def execute(self, operation, parameters={}, acceptPartial=True, limit=None, offset=0):
- sql = operation % parameters
- data = {
- 'sql': sql,
- 'offset': offset,
- 'limit': limit or self.connection.limit,
- 'acceptPartial': acceptPartial,
- 'project': self.connection.project
- }
- logger.debug("QUERY KYLIN: %s" % sql)
- resp = self.connection.proxy.post('query', json=data)
- column_metas = resp['columnMetas']
- for c in column_metas:
- c['label'] = str(c['label']).lower()
- c['name'] = str(c['name']).lower()
- self.description = [
- [c['label'], c['columnTypeName'],
- c['displaySize'], 0,
- c['precision'], c['scale'], c['isNullable']]
- for c in column_metas
- ]
- self.results = [self._type_mapped(r) for r in resp['results']]
- self.rowcount = len(self.results)
- self.fetched_rows = 0
- return self.rowcount
最后,我发现在查找的字段包含kylin中的date类型时也会出错。点击slice页面右上角的query按钮,可以查看superset最终发送的sql。
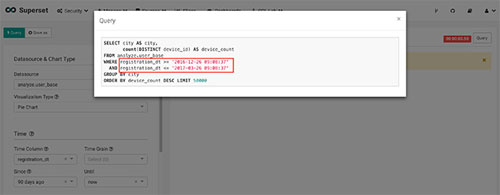
将它直接拷贝到kylin的insight页面去执行,发现报错。原来kylin的date类型只支持年月日,而superset在添加日期搜索条件时为了实现定时刷新图表而在sql的日期条件中都精确到了时分秒。关于这个我原先是在superset中做了修改。
在superset的models.py的get_query_str方法中:
- time_filter = dttm_col.get_time_filter(from_dttm, to_dttm)
改为
- if engine.name == 'kylin':
- time_filter = dttm_col.get_date_filter(from_dttm, to_dttm)
- else:
- time_filter = dttm_col.get_time_filter(from_dttm, to_dttm)
添加get_date_filter,dt_sql_literal函数:
- def get_date_filter(self, start_dttm, end_dttm):
- col = self.sqla_col.label('__time')
- return and_(
- col >= text(self.dt_sql_literal(start_dttm)),
- col <= text(self.dt_sql_literal(end_dttm)),
- )
- def dt_sql_literal(self, dttm):
- return "'{}'".format(dttm.strftime('%Y-%m-%d'))
这样对于所有kylin数据源的查找时间范围条件都将转为年月日的格式。
不过我一直感觉这个改动不是很完美,是一种典型的打补丁的做法。后来我发现superset支持在列的设置页面为一个日期列添加自定义的格式转换函数
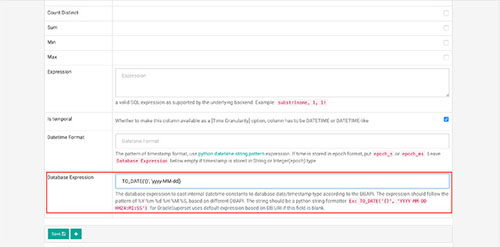
于是我在这里设置日期列格式
- TO_DATE(‘{}’, ‘yyyy-MM-dd’)
然后可以看到slice这里sql中的该列都变成了to_date函数形式

最后的工作就是修改kylin源码,添加对日期函数的支持。hive sql是支持to_date等日期格式转换函数的,kylin凭什么不支持?
大致debug了一下kylin的源码,kylin处理sql的入口在server-base模块下的QueryController.java的query方法中。我发现在最终调用jdbc驱动执行sql之前,kylin会调QueryUtil类的massageSql方法来优化sql。主要是加上limit和offset参数。最后调内部类DefaultQueryTransformer的transform方法改掉sql中的一些通病,比如SUM(1)改成count(1)等。日期转换函数的处理放在这后面我觉得是最合适的。
添加正则表达式,以匹配日期函数:
- private static final String TO_DATE = "(to_date|TO_DATE)\\(['|\"]([^'|\"]*)['|\"],\\s?['|\"]([^'|\"]*)['|\"]\\)";
- private static final Pattern FN_TO_DATE = Pattern.compile(TO_DATE);
添加日期转行函数解析:
- private String executeFN(String sql) {
- Matcher m;
- while (true) {
- m = FN_TO_DATE.matcher(sql);
- if (!m.find())
- break;
- String dateTime = m.group(2);
- String format = m.group(3);
- SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
- Date dt = null;
- try {
- dt = sdf.parse(dateTime);
- } catch (ParseException e) {
- logger.error("Parse date error", e);
- }
- sdf = new SimpleDateFormat(format);
- String date = sdf.format(dt);
- String begin = sql.substring(0, m.start());
- String end = sql.substring(m.end(), sql.length());
- sql = begin + "'" + date + "'" + end;
- }
- return sql;
- }
然后kylin就可以支持上面sql的执行了
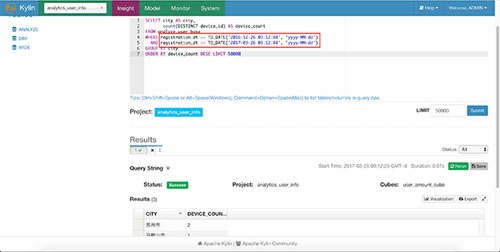
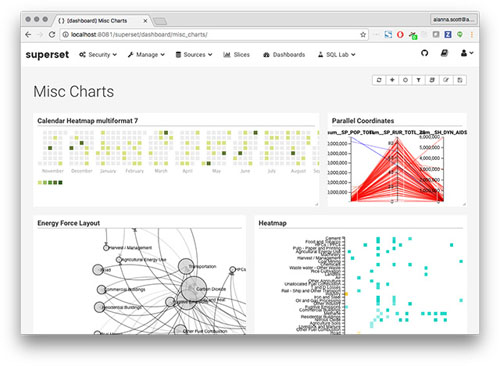
最后,让我们多尝试一些可视化图表吧,把它们做成dashboard
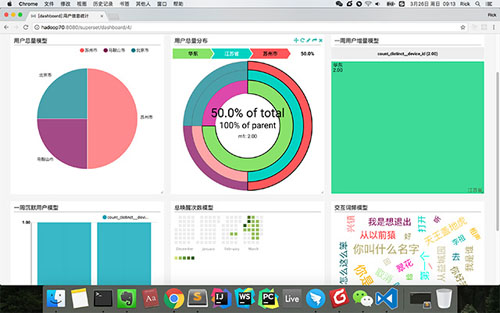
结论:kylin很好地支持了我厂每天上百GB数据的立方体建模和实时查找,结合superset的方案,作为我厂内部的可视化工具,收到了很好地效果。