Linux 日志分析
虽然提取的时候,不总是和你想的一样简单,但是日志中有大量信息在等着你。在这部分,我们会讲一些基本分析示例,你可以马上拿来处理你的日志(只是搜索里面有什么)。我们还会讲一些高级分析方法,开始的时候可能要花时间来做配置,但会为以后省很多时间。你可以把高级分析的示例用在待解析的数据上,比如生成摘要计数,过滤字段值等。
首先我们会演示,你应该如何使用不同的工具在命令行进行日志分析;然后,演示一个日志管理工具,它能够让大多数乏味的工作变得自动化和高效。
使用 Grep 搜索
搜索文本是找到你想要的信息的最基本方法。搜索文本最常用的工具是 grep 。这个命令行工具,大多数 Linux 发行版上都有,它支持你用正则表达式来搜索日志。正则表达式是一种用专门语言写成的语句,可用来识别匹配文本。最简单的正则表达式是把你搜索的字符串加上引号。
正则表达式
这里有个例子,它在 Ubuntu 的认证日志里搜索 “user hoover”:
- $ GREP "USER HOOVER" /VAR/LOG/AUTH.LOG
- ACCEPTED PASSWORD FOR HOOVER FROM 10.0.2.2 PORT 4792 SSH2
- PAM_UNIX(SSHD:SESSION): SESSION OPENED FOR USER HOOVER BY (UID=0)
- PAM_UNIX(SSHD:SESSION): SESSION CLOSED FOR USER HOOVER
构造精确的正则表达式很难。例如,假设我们搜索一个数字,比如端口号“4792” ,它也可以匹配时间戳,URLs和其他不需要的数据。在下面针对 Ubuntu 的例子里,它匹配了 Apache 日志,但这并不是我们想要的。
- $ grep "4792" /var/log/auth.log
- Accepted password for hoover from 10.0.2.2 port 4792 ssh2
- 74.91.21.46 - - [31/Mar/2015:19:44:32 +0000] "GET /scripts/samples/search?q=4972HTTP/1.0" 404 545 "-" "-”
延伸搜索
另一个有用的技巧是你可以用grep 做延伸搜索。它会输出匹配项的前几行和后几行内容。它可以帮你调试是什么导致了错误或问题。B 选项指定显示匹配项前面的行数,A 选项指定显示匹配项后面的行数。如下所示,我们看到,当有人以 admin 身份登陆失败后, 反向映射也会失败,这说明他们可能没有有效的域名。这很可疑!
- $ grep -B 3 -A 2 'Invalid user' /var/log/auth.log
- Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: reverse mapping checking getaddrinfo for 216-19-2-8.commspeed.net[216.19.2.8] failed - POSSIBLE BREAK-IN ATTEMPT!
- Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
- Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: <b>Invalid user</b>; admin from 216.19.2.8
- Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: input_userauth_request: invalid user admin [preauth]
- Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
Tail命令
你也可以将 tail 和 grep 搭配起来使用,以获取文件***几行,或者跟踪日志并实时打印。当你在进行交互式更改比如架设服务器或测试代码更改的时候,非常有用。
- $ tail -f /var/log/auth.log | grep 'Invalid user'
- Apr 30 19:49:48 ip-172-31-11-241 sshd[6512]: Invalid user ubnt from 219.140.64.136
- Apr 30 19:49:49 ip-172-31-11-241 sshd[6514]: Invalid user; admin from 219.140.64.136
全面介绍 grep 和正则表达式超出了本文的范围,Ryan 的教程里有更深入的介绍。
日志管理系统中有更高效更强大的搜索工具。它们通常对数据建立索引和并行查询,因此你可以在数秒之内快速查询高达 G 字节或 T 字节的日志。相比之下,用 grep ,可能要花几分钟,极端情况下会花费数小时。日志管理系统也像 Lucene (译注:一个开源的全文检索引擎工具包)一样使用查询语言 ,它为数字,字段等的搜索提供了简单的语法。
用Cut,AWK 和 Grok 解析日志
命令行工具
Linux 提供了几种文本解析和分析的命令行工具。如果你想快速解析少量的数据,它们很强大,但是处理大量数据要花很长时间。
Cut 命令
cut 命令可以从带分隔符的日志中解析字段。分隔符是类似等号或逗号的字符,用来划分字段或键值对。
比如说,我们想从这个日志中提取用户名:
- pam_unix(su:auth): authentication failure; logname=hoover uid=1000 euid=0 tty=/dev/pts/0 ruser=hoover rhost= user=root
我们可以和下面一样使用 cut 命令,获取第八个等号后边的文本。这是 Ubuntu 上的例子:
- $ grep "authentication failure" /var/log/auth.log | cut -d '=' -f 8
- root
- hoover
- root
- nagios
- nagios
AWK 命令
此外,你还可以用 awk,它拥有更强的解析字段的功能。它提供了一个脚本语言,让你几乎可以过滤出任何毫不相关的信息。
举个例子,假设我们在 Ubuntu 上有如下的日志,我们想提取登陆失败的用户名:
- Mar 24 08:28:18 ip-172-31-11-241 sshd[32701]: input_userauth_request: invalid user guest [preauth]
下面是使用 awk 的例子。首先,用一个正则表达式 /sshd.*invalid user/ 匹配 sshd 无效用户的那一行。然后使用 { print $9 } 打印第九个字段(默认的分隔符是空格)。这样就输出了用户名。
- $ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
- guest
- admin
- info
- test
- ubnt
你可以从 Awk 用户指南中获取更多关于如何使用正则表达式和打印字段的信息。
日志管理系统
日志管理系统让解析更容易并且让用户可以快速分析大量日志文件。它们可以自动解析标准日志格式,比如公共 Linux 日志或 web 服务日志。这会节省很多时间,因为你在定位系统问题的时候不用去想如何写你的解析逻辑。
这里你可以看一个来自 sshd 的日志信息,解析出了远程主机和用户字段。这个截图来自 Loggly,一个基于云计算的日志管理服务。

对非标准格式的日志,你也可以自定义解析规则。最常用的工具是 Grok,它用通用正则表达式库把纯文本解析成 JSON 格式。这是 Grok 的配置示例,用来解析 Logstash 的内核日志 :
- filter{
- grok {
- match => {"message" => "%{CISCOTIMESTAMP:timestamp} %{HOST:host} %{WORD:program}%{NOTSPACE} %{NOTSPACE}%{NUMBER:duration}%{NOTSPACE} %{GREEDYDATA:kernel_logs}"
- }
- }
这是用 Grok 解析后输出的结果:

使用 Rsyslog 和 AWK 过滤
过滤是搜索特定的字段,而不是全部文本。这让你的日志分析更精确,因为它会忽略其他不需要的日志信息。为了搜索一个字段值,你需要先解析你的日志或者至少有一种基于事件结构的搜索方法。
如何筛选出同一个应用的日志
通常,你只想看来自同一个应用的日志。如果你的应用总是把日志记录在单个文件中,这样很容易分析。如果你要从聚合或集中起来的日志里筛选出和某个程序相关的日志,会很复杂。这里有几种解决的办法。
用 Rsyslog 服务解析和过滤日志。这个例子是将 sshd 应用程序的日志写入名为 sshd-messages 的文件中,然后丢弃事件,所以它不会在其他日志里重复出现。你可以把它加到你的 Rsyslog.conf 文件里试一下。
- :programname, isequal, “sshd” /var/log/sshd-messages
- &~
使用命令行工具比如 awk ,提取特定字段的值,比如取 sshd 用户名。这是 Ubuntu 上的例子。
- $ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
- guestadmin
- info
- test
- ubnt
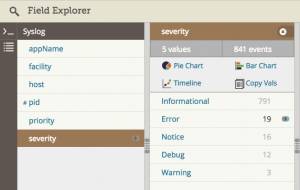
使用日志管理系统自动解析你的日志,然后点击目标应用的名字进行过滤。这个截图显示了 syslog 的各个字段,在一个叫做 Loggly 的日志管理服务中。如图中文氏图所示,当前正在过滤 sshd 这个应用。
如何筛选出错误信息
最常见的事情是,人们想看到日志中的错误。不巧的是,默认的 syslog 配置不会直接输出错误的级别,这使得错误信息很难被筛选。
这里有两种方案来解决这个问题。首先,你可以修改 rsyslog 配置,让它输出级别到日志文件中,使得错误信息容易被读取和搜索。在你的 Rsyslog 配置中你可以加一个pri-text 模版,如下所示:
- "<%pri-text%> : %timegenerated%,%HOSTNAME%,%syslogtag%,%msg%n"
这个例子的输出如下,可以看到级别是 err。
- <authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
你可以用 awk 或grep 筛选出错误信息。这是 Ubuntu 下的例子,我们加了开始结束标志 . 和 > ,这样它就只匹配这个字段。
- $ grep '.err>' /var/log/auth.log
- <authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
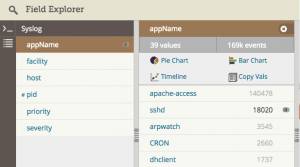
第二种选择是使用日志管理系统。好的日志管理系统会自动解析 syslog 消息并提取出级别字段。只需点一下,就会按指定的级别筛选日志。
这是 Loggly 的截图。显示了 syslog 各个字段, Error 级别高亮显示了,说明正在按级别 Error 过滤