一、缘起
在我工作的多家公司,有众多的领域,如房产,电商,广告等领域。尽管业务相差很大,但都涉及到爬虫领域。开发爬虫项目多了后,自然而然的会面对一个问题——
- 这些开发的爬虫项目有通用性吗?
- 有没有可能花费较小的代价完成一个新的爬虫需求?
- 在维护运营过程中,是否能够工具化,构建基于配置化的分布式爬虫应用?
这就是是我们今天要讨论的话题。
二、项目需求
立项之初,我们从使用的脚度试着提几个需求。
1. 分布式抓取
由于抓取量可能非常庞大,一台机器不足以处理百万以上的抓取任务,因此分布式爬虫应用是首当其冲要面对并解决的问题。
2. 模块化,轻量
我们将爬虫应用分成“应用层,服务层,业务处理层,调度层” 四个脚色。
3. 可管理,可监控
管理监控是一个体系,即配置可管理化,运行实时监控化。在系统正常运行时,可以变更爬虫的配置,一旦实时监控爬虫出现异常,可实时修正配置进行干预。所有的一切,均可以通过UI界面进行操作。
4. 通用性,可扩展。
爬虫业务往往多变,不同领域的爬取需求不尽相同。举例说,房源抓取包含图片抓取,小区信息抓取,房源去重等模块。新闻抓取包括内容抓取,正文提取,信息摘要等相关。
因此,系统需要能够支持业务扩展需求,可以支持不同的业务使用同一套框架进行应用开发。
三 模块分解
针对业务需求,我们将系统分解成多个应用模块。
1. 应用层
应用层是针对管理员,系统维护人员使用。主要分成两个模块,系统配置模块和运营管理模块。
- 系统配置模块:系统配置模块包含抓取网站管理配置,在线测试等功能。
- 运营管理模块:运营管理模块包含实时抓取量统计,分析,正确率等。甚至包括失败原因,失败量。
系统运营人员可以根据运营模块得到实时的反馈,使用系统配置模块进行配置修正,在线测试正确后将配置生效,再实时监控新的配置产生的效果。
2. 服务层
服务层是整个系统传输的中枢,相当于整个分布式集中的系统总线和数据总线。服务层提供一个http/thrift接口,读取数据库,输出配置信息。
- 提供网站爬虫配置接口。从数据库中实时读取配置信息,响应业务层的配置请求。
- 提供业务层输出写入接口。接受业务层实时爬取的信息汇总,包括正确数据量,错误数据量,以及错误原因。
- 提供实时报表统计分析。响应应用层的运营管理模块,查询数据库,实时提供数据分析报告。
3. 业务处理层
业务处理层是整个爬虫系统的核心,可分成多台应用服务器进行处理。业务处理层主要包含解决两件事情。
- 如何获取url
- 得到url后,如何处理
(1) 如何获取url
对于爬虫来说,如何获取url至关重要。我们将这一过程定义为发现系统。对于发现系统而言,目标为如何发现待抓取网站的详细url列表,尽可能的发现更全。
a 假设场景 A
我们逛一个电商网站:打开首页-打开分类页-可能会有多层分类页-逐层点击-直至最小的分类页面。
打开这个分类页会发现该分类页下的所有分页页面,一页一页往下翻,就能够获得该分类页的所有商品。
b 假设场景 B
我们逛一个汽车网站:打开首页-找到品牌页-接着找到车系-最后找到车款页面。
通过以上场景分析可以得到一个结论,人能非常智能的找到所有待抓取的详细页面,即电商的商品,汽车的车款页面。那么,是否可以通过配置方式来模拟这一过程呢?
请看下图:
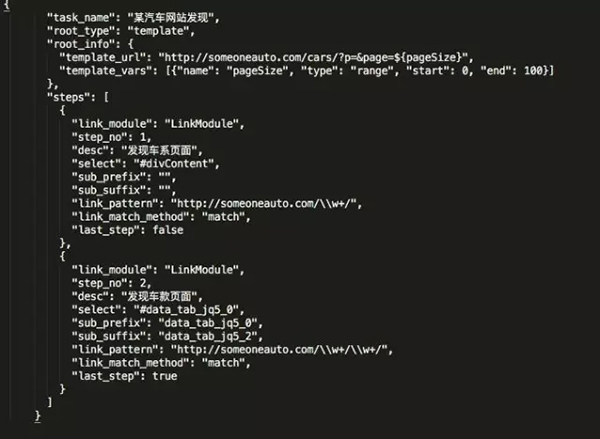
备注如下:
*root_info:
定义发现模块的入口页面,如同人打开汽车站的网页,后续的发现都是起始于这些入口页。
这里给出的实例是,某汽车网的品牌列表页,根据“模板化”套用变量的配置,共有100个入口页。
* steps:
依次遍历这100个入口页,分别会执行steps中定义的步骤。机器模拟人的方式进行查看浏览。
每个step中,会使用"link_module"定义的类进行逻辑进行处理。
- 读取入口页的html,结合"sub_prefix","sub_suffix"和"select"定义的内容,获得页面子区域html。
- 使用"link_match_method"的方法(含前缀包含,匹配等),抽取子区域的链接。
- 每个链接 和"link_pattern"进行匹配,匹配成功的url进入下一步。
- 每一步得到的url,自动进和地下一步处理,处理逻辑为递归上面a-c,直至"last_step"为true为止。
此处,即"last_step"为true中发现的url,即为发现系统最终需要获取的url列表。发现系统总结,通过配置的方式,结合人类的浏览习惯,通过若干步迭代,最终获取网站的详细页url列表。
由于每一步的抽取链接规则,以及步数据都是人为定义,因此,可以适配绝大部分网站的发现系统。当然,越复杂的网站发现配置可能更多一些、更为繁杂,但万变不离其宗。
2. 得到url后,如何处理
前提当然是每个业务的处理各不相同,有抽取页面属性功能、有正文提取、有图片获取,甚至有和当前系统对接等。
由于业务处理不一致,很自然想到的是通过配置方式,定义职责链系统,如同著名框架Netty中的Pipeline设计。在处理过程中,定义一个Context上下文处理类,并且,所有的中间结果都暂缓在这个Context中。
描述比较空洞,还是结合实际案例来看。

备注如下:
得到一个url后,读取配置,当url和"site"匹配时,适用当前"site"规则。
* pipeline定义职责链的处理过程
此处的定义为“抓取模块,Javascript处理模块,通用解析模块”。对应的处理如下:
先执行抓取模块,得到html。紧接着执行Javascript处理模块,输入为html,解析html,此处可能是评论,也可能是价格,总之处理的是动态加载项目,紧接着处理“通用解析模块”
* "parser_rules"定义的是解析模块
最终输出的是kv,在java中是map,python中是dict。即从上一步的html中,找到每一荐的"sizzle",执行"prefix","suffix"即前后缀移除(过滤如同“价格:xxx元,前缀为“价格:",后缀为元)。
对了,sizzle也是一个开源技术,据说以前鼎鼎有名的Jquery也是"sizzle"引擎。Java中可以使用Jsoup解析处理。
怎么知道需要取的"sizzle"内容是什么呢?具体可以结合firebug插件,选中即可得。选中后,结合应用层的管理工具,即可进行测试。
* “isrequire"
可以看到,配置项中有“isrequire",表示这项内容是否必须。如果必须,且在实际处理中获取不到,那么在抓取的过程中,就会记录一个错误, 错误原因自然是“$key is null"。此外,每一个module都可能出错,一旦出错,就没有必要往后去执行。
因此,在抓取过程中,业务处理层从服务层获得一批url(默认100个)后,在处理这一百个url结束后,会向服层report,report内容为:
| 当前任务处理机器,于什么时间处理100个页面。不同网站成功多少、失败多少、什么模块失败多少,解析模块什么字段失败多少。 |
所有这些信息,均是实时统计,并在运营监控系统中以图表形示绘制出来,必要时可以发出报警,交由维护人员实时干预。
Q: 提一个问题,新增一个anotherauto.com网站怎么办?
A: 其实也很简单,再增加一个配置呗。业务定义pipeline,如果有解析需求,填写对应的解析项即可。
以上两个系统,发现系统和处理系统,在我们实际生产中,是通过以下步骤贯穿。
- 发现系统累计发现待抓取网站的详细页,因为是一个累计持续的过程。因此有把握持续无限接近网站的100%页面。
- 处理系统通过服务层,每次去取配置信息(可能维护人员在实时修正)及待抓取的列表进行处理。
待抓取的列表根据业务的优先级,分普通队列及优先级队列,通过任务调度系统进行统一管理和配置。
4. 调度层
- 调度层主要是业务系统。
- 新增一个网站任务调度
- 网站发现频率,包括增量发现频率和全量发现频率
- 网站抓取优先级推送至队列
- 断点续抓管理
- ......
四、系统架构设计
- 从业务模块上看:应用层,服务层,业务处理层,调度层
- 从功能系统上看:发现系统,抓取系统, 配置系统,监控系统
- 从扩展性上看:自定义职责链,自定义属性提取
- 从实时性上看:实时抓取,实时配置生效,实时监控,实时测试
- 从系统架构上看:分布式架构,服务层主从切换设计,轻量(仅依赖于队列,数据库,java)
五、图例





【本文是51CTO专栏机构“岂安科技”的原创文章,转载请通过微信公众号(bigsec)联系原作者】