












by 崔维福
情感分析是学术领域研究多年的课题,用google学术搜索可以找到很多paper,基本的方法上有基于词典规则的方法、语言文法的方法,此外还有分类器以及近几年比较火的深度学习的方法(稍后有详细介绍)。
各类paper是有一定的借鉴意义的,不过这主要是学术界在单个问题上的细化,要真正从研究领域落地到大数据的处理还有很多工作要做。
一、工程上的处理流程
工程上的处理流程具体包括以下几个方面:
1、情感分析任务的界定
在进行情感分析任务的界定时,要弄清楚工程的需求到底是什么;要分析文本的哪个层面上的情感,比如篇章、段落、句子、短语、词等粒度;是不是要分析所有的文本还是分析其中的部分文本;准许的错误误差是在个什么范围内等。
2、情感分析标准的制定
在实际的企业应用中往往要根据行业的特点来制定一些情感分析的标准,甚至要从客户的立场中去建立标准。根据国双实际接触客户的经验,在行业上建立标准后,还需要再具体跟客户做一些适度调整。
3、 语料数据加工、词典加工
有了上一步的工作, 接下来进行加工语料或者字典的总结。这一步中不同的方法要做的工作不同,基本上是铺人力的工作,难点是让各个语料加工人员能协调一致,执行统一的标准 (通常会在这个过程中还会反作用到第二步情感分析标准的制定,因为看到实际数据后会发现标准总会有一些模糊地带)
4、根据数据特征、规模等选择合适的方法,并评测方法的优劣
工程中的方法并不是单一的方法,想用一个方法或者模型来解决各类数据源上的问题是不可能的。想要做出好的效果一定是采用分而治之的思想,比如,能用规则精准过的就不需要用分类器。
当应用在实际产品时,***能结合产品的垂直特点,充分利用垂直行业的特性,比如在金融行业、汽车行业,它们一定有自己的行话,这些行话具有非常明显的规则或者特征。
二、情感分析方法及工具
情感分析对象的粒度最小是词汇,但是表达一个情感的最基本的单位则是句子,词汇虽然能描述情感的基本信息,但是单一的词汇缺少对象,缺少关联程度,并且不同的词汇组合在一起所得到的情感程度不同甚至情感倾向都相反。所以以句子为最基本的情感分析粒度是较为合理的。篇章或者段落的情感也可以通过句子的情感来计算。
现阶段关于情感分析方法主要有两类:
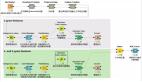
(一)、基于词典的方法:
基于词典的方法主要通过制定一系列的情感词典和规则,对文本进行拆句、分析及匹配词典(一般有词性分析,句法依存分析),计算情感值,***通过情感值来作为文本的情感倾向判断的依据。
做法:
基于词典的情感分析大致步骤如下:
- 对大于句子力度的文本进行拆解句子操作,以句子为最小分析单元;
- 分析句子中出现的词语并按照情感词典匹配;
- 处理否定逻辑及转折逻辑;
- 计算整句情感词得分(根据词语不同,极性不同,程度不同等因素进行加权求和);
- 根据情感得分输出句子情感倾向性。
如果是对篇章或者段落级别的情感分析任务,按照具体的情况,可以以对每个句子进行单一情感分析并融合的形式进行,也可以先抽取情感主题句后进行句子情感分析,得到最终情感分析结果。
参考及工具:
1. 常见英文情感词库:GI(The General Inquirer)、sentiWordNet等;
2. 常见中文情感词库:知网、台湾大学的情感极性词典;
3. 几种情感词典构建方法:基于bootstrapping方法的Predicting the semantic orientation of adjectives及Determining the sentiment of opinions两种最为经典的词典构建方法。
(二)、 基于机器学习的方法:
情感词典准确率高,但存在召回率比较低的情况。对于不同的领域,构建情感词典的难度是不一样的,精准构建成本较高。另外一种解决情感分析的思路是使用机器学习的方法,将情感分析作为一个有监督的分类问题。对于情感极性的判断,将目标情感分为三类:正、中、负。对训练文本进行人工标注,然后进行有监督的机器学习过程,并对测试数据用模型来预测结果。
处理过程:
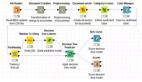
基于机器学习的情感分析思路是将情感分析作为一个分类问题来处理,具体的流程如下:
1、 文本预处理
文本的预处理过程是使用机器学习作用于文本分类的基础操作。由于文本是非结构化数据及其特殊性,计算机并不能直接理解,所以需要一系列的预处理操作后,转换为计算机可以处理的结构化数据。在实际分析中,文本更为复杂,书写规范也更为随意,且很有可能掺杂部分噪声数据。整体上来说,文本预处理模块包括去噪、特征提取、文本结构化表示等。
特征抽取:中文最小语素是字,但是往往词语才具有更明确的语义信息,但是随着分词,可能出现词语关系丢失的情况。n-元文法正好解决了这个问题,它也是传统机器学习分类任务中最常用的方法。
文本向量化:对抽取出来的特征,向量化是一个很重要的过程,是实现由人可以理解的文本转换为计算机可以处理数据的重要一步。这一步最常用到的就是词袋模型(bag-of-words )以及最近新出的连续分布词向量模型(word Embedding)。词袋模型长度为整个词表的长度,词语对应维度置为词频,文档的表示往往比较稀疏且维度较高。Embedding的表示方式,能够有效的解决数据稀疏且降维到固定维度,更好的表示语义信息。对于文档表示,词袋模型可以直接叠加,而Embedding的方法可以使用深度学习的方法,通过pooling得到最终表示。
特征选择:在机器学习分类算法的使用过程中,特征好坏直接影响机器的准确率及召回率。选择有利于分类的特征,可以有效的减少训练开支及防止模型过拟合,尤其是数据量较大的情况下,这一部分工作的重要性更加明显。其选择方法为,将所有的训练语料输入,通过一定的方法,选择最有效的特征,主要的方法有卡方,信息熵,dp深层感知器等等。
目前也有一些方法,从比句子粒度更细的层次去识别情感,如基于方面的情感分析(Aspect based Sentiment Analysis),他们从产品的评价属性等更细粒度的方面对评价主体进行情感倾向性分析。
2、分类算法选择
文本转换为机器可处理的结构后,接下来便要选择进行机器学习的分类算法。目前,使用率比较高的是深度学习(CNN,RNN)和支持向量机(SVM)。深度学习的方法,运算量大,准确率有一定的提高,所以都在做这方面的尝试。而支持向量机则是比较传统的方法,其准确率及数据处理能力也比较出色,很多人都在用它来做分类任务。
参考及工具:
1. svm分类 libsvm
2. python 机器学习工具scikit-learn
3. 深度学习框架:Tensorflow、Theano
本文选自国双商业市场在知乎的回答。


















![[[186255]]](http://www.36dsj.com/wp-content/uploads/2017/03/3-8.jpg){kind=link}