一、过去:从猫到狗
翻阅1982年第1期的《世界科学》杂志,看到这样一则消息:“1981年10月17日,在瑞典的斯德哥摩尔城举行的诺贝尔奖授奖大会上,美国加州理工学院的罗杰•握尔考特•斯佩里(Roger Wolcott Sperry)博士和加拿大出生的美国人戴维•哈贝尔教授以及瑞典的托尔斯滕•韦塞尔分享了1981年诺贝尔生理学、医学奖。斯佩里因证明大脑两半球的高度专门化以及许多较高级的功能集中在右半球而获奖;哈贝尔和韦塞尔因研究视觉系统的信息处理方面有所发现而获奖。”
哈贝尔和韦塞尔的获奖要归功于“猫星人”,据说这个研究从1958年开始,在猫的后脑头骨上,开了一个小洞,向洞里插入电极,测量神经元的活跃程度,从而发现了一种神经元细胞——“方向选择性细胞”,即后脑皮层的不同视觉神经元与瞳孔所受刺激之间确实存在某种对应关系。这一重要发现,激活了一度沉寂的神经网络的研究。但是,人们不得不面对这样的现实:神经网络相关运算中耗费的运算量与神经元数目的平方成正比。基于硬件基础,那个时候人们普遍认为潜在的庞大的计算量是几乎无法实现的。

计算能力成了拦路虎,人们探寻真理的脚步一刻没有停歇。同样是1981年,IBM PC机中首次应用了8088芯片,开创了全新的微机时代。1985年INTEL推出了32位微处理器,而且制造工艺也有了很大的进步。许多人对286、386、486机器还存有记忆,人类的计算能力伴随着摩尔定律在大踏步前进。关于神经网络的算法也有了新的突破,1986年Hinton和David Rumelhard联合在国际权威杂志《自然》上提出在神经网络模型上运用反向传播算法,大大降低了原来预计的运算量。20世纪80年代末到90年代初,共享存储器方式的大规模并行计算机又获得了新的发展。1993年,Cray公司研制成功了第一台具有标志性的大规模并行计算机。我国的银河系列并行计算机,在国际上也独树一帜。新世纪以来,大规模并行计算机蓬勃发展,逐渐成为国际上高性能计算机的主流。
伴随着计算处理能力的提升,深度学习有了较快的发展,从结构上分为生成型深度结构、判别型深度结构、混合型深度结构三类。1989年,加拿大多伦多大学教授Yann LeCun就和他的同事提出了卷积神经网络,是一种包含卷积层的深度神经网络模型,较早尝试深度学习对图像的处理。2012年,Hinton构建深度神经网络,在图像识别问题上取得质的提升和突破。百度公司将相关最新技术成功应用到人脸识别和自然图像识别问题,并推出相应的产品。同样是从2012年,人们逐渐熟悉Google Brain团队。2015年至2017年初,一只“狗”引起世界的关注,人类围棋大师们陷入沉思。
二、现在:深度学习有多深
回答这个问题之前,让我们回顾一下机器学习。以使用决策树、推导逻辑规划、聚类、贝叶斯网络等传统算法对结构化的数据进行分析为基础,对真实世界中的事件作出决策和预测,通常被称为机器学习。比如无人驾驶汽车识别交通标志,这种机器视觉就是典型的机器学习。但是在特定的天气条件下,算法不灵,机器学习就有了局限。
深度学习在机器学习的基础上又前进了一步,同样是从数据中提取知识来解决和分析问题,深度学习使用的是人工神经网络算法,允许发现中间表示来扩展标准机器学习,这些中间表示能够解决更复杂的问题,并且以更高的精度、更少的观察和更不麻烦的手动调谐,潜在地解决其它问题。最常见的深度学习类型是前馈深层神经网络(DNN),其使用大量的互连处理单元层从原始输入数据中“发现”适当的中间呈现。DNN提供了一个强大的框架,可应用于各种业务问题。例如可以分析视网膜扫描以“辨识”哪些模式指示健康或患病视网膜(并指示特定疾病)。“辨识”过程依赖于强力的高性能计算。

根据Gartner的相关资料,深度学习已经在图像识别、机器翻译、语音识别、欺诈检测、产品推荐等方面得到应用,如下表1、2:
表1:深度学习当前部分相关领域及案例

表2 深度学习当前的能力范围
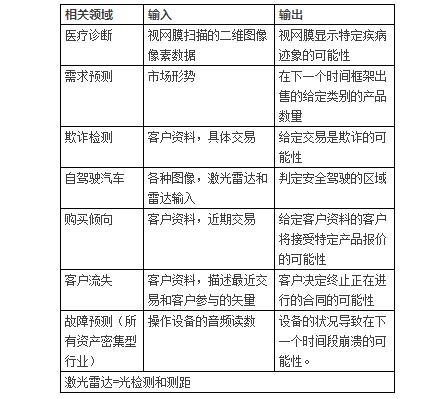
来源:Gartner(2017年1月)
Gartner估计,从初创公司到技术巨头,全球有2,000多家供应商正在推出深度学习相关产品。但是,当前的深度学习有其一定的局限:
1、深度学习技术是启发式的。深度学习是否会解决一个给定的问题是不清楚的,根本没有数学理论可以表明一个“足够好”的深度学习解决方案是否存在。该技术是启发式的,工作即代表有效。
2、深度学习技术的不可预期性。深度学习涉及隐藏层,在许多情况下,即使是领先的科学家也不能解释这些层面发生了什么,这样的“黑盒子” 可能对解释甚至接受结果造成问题,有时甚至破坏合规性和道德性。
3、深度学习系统化运用不成熟。没有适合所有行业且通用的深度学习,企业想要创建自己的解决方案,目前必须混合和匹配可用的工具,并跟上新软件的快速出现。
4、部分错误的结果造成不良影响。深度学习目前不能以100%的精度解决问题。深度学习延续了较浅层机器学习的大多数风险和陷阱。
5、学习速度不尽如人意。一个两岁的孩子可以在被告知几次后识别大象,而深度学习系统可能需要成千上万的例子,并且“看”这些例子数十万或数百万次,才能成功。
6、当前的范围比较狭窄。比如,AlphaGo系统学会了在大师水平线上玩Go,也只会玩Go。应用于任何其他游戏(甚至更简单)时,系统将彻底失败。
三、未来:从GPU到?PU
深度学习是人工智能发展的主要驱动力。目前主要是在弱人工智能的发展中产生重要作用,主要是特定的行业应用,如上文提到的图像识别、自动驾驶和机器翻译等。但是要支撑和实现和人脑类似的强人工智能,OSTP(美国白宫科技政策办公室)认为至少在几十年内无法实现。除了上文提及的数据不足、相关算法需要改进外,对高性能计算的追求就是一个长期的持续的根本任务。

GPU这个概念在当前的“读图时代”,很多人并不陌生。GPU是相对于CPU的一个概念,由于在现代的计算机中(特别是家用系统,游戏的发烧友)图形的处理变得越来越重要,需要一个专门的图形的核心处理器,这就是GPU。GPU对于深度学习技术非常重要。随着技术的演进,核心处理器也将更新迭代。例如,谷歌大脑团队正在设计TPU(深度学习芯片),这是针对深度神经网络运算的改进版的处理器。
量子计算至少在未来十年内不会影响深度学习。谷歌大脑团队的科学家Jeff Dean认为,人的大脑不是量子计算机,量子计算几乎不会对深度学习造成特别明显的影响,特别是在中短期内(比如未来十年)。但是,未来的未来,量子计算是不是能根本上改变深度学习,这谁也说不准。
文章转载自微信公众号“三思派”(ID: Science-Pie)