背景
作为一个开放领域的知识社交平台,知乎为大家提供了「友善」、「理性」、「专业」的讨论氛围,吸引了大量用户参与,产生了很多优质内容。但同时也吸引了一些垃圾制造者,在知乎上生产了不少的垃圾内容,如「违法」、「广告」、「淫秽色情」、「人身攻击」等,严重影响了知乎用户的正常讨论交流,极大地影响了用户体验,同时也对社区管理造成了较大的干扰。
我们先来看看都有哪些真实的垃圾:
非法内容
用侮辱、夸张的手法嘲讽他人,如「脑残」、「智商欠费」等等。这类内容表现为不尊重他人,用恶毒的言语刺激对方,使得讨论无法正常有效进行。
还有一些垃圾广告,如微商。
这些垃圾内容严重影响了知乎用户的正常交流。此前我们的工程师们也尝试了一些方法去识别处理它们。如文本分类模型,准确率达到了 96%, 每天识别 300+ 条;利用 DFA 根据关键词大量召回。这些尝试虽然都取得了一定的效果,但是召回不够、或召回过多非垃圾内容、或者存在不少的误伤。为此我们引入人工审核,但不能快速处理,容易造成内容堆积,而且对管理员也是很大压力,平均每周要消耗 1 个人力。
前期的尝试虽然效果不是很理想,但积累了比较多的数据。对这些数据的分析,我们发现这些垃圾内容是有套路的。基于此,我们利用 Aho-Corasick 自动机实现多模匹配,在其基础上增加了过滤机制,实现了第一版的垃圾内容分析系统,取得了不错的效果。
Aho-Corasick 自动机
AC 自动机算法于 1975 年产生于贝尔实验室。该算法巧妙地将多模式串建成一个确定性有限状态机 (DFA),以待匹配字符串作为该 DFA 的输入,使状态机进行状态转移,当到达某些特定的状态时,完成模式匹配, 能 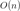
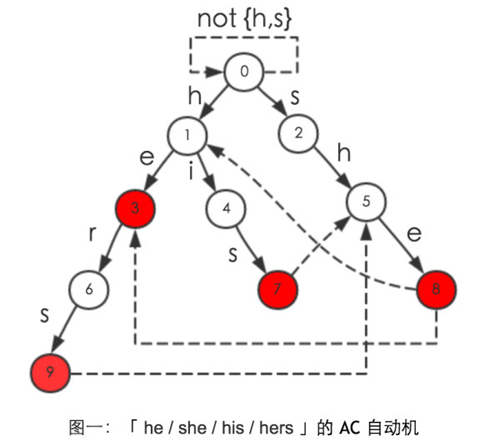
当输入一个字符串时「ushers」,该自动机从状态 0 开始进行状态转换,完整的状态转移路径如图二所示
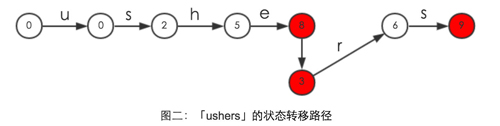
当遇到 AC 中的红色节点时,说明发生了模式匹配,匹配到的模式有:「he」、「she」、「hers」。
具体可以用 Double Array Trie 实现 AC 自动机,在保持高效多模匹配的基础,进一步节省空间。
贝叶斯方法
虽然 AC 自动机能快速的从字符串中找到存在于词典中的关键词,但这仅仅能满足一小部分需求,即不顾准确率的大量召回,很显然会造成误伤,这对知友也是很不友好。肯定有知乎用户会问,直接用「贝叶斯」方法不就可以搞定吗?你看人家做 spam 邮件过滤,不也做得还不错,还用什么 AC ?对对对,你说的都是正确的。但是实验发现,单纯地用 「贝叶斯」方法直接进行过滤时,准确率和召回率都不是很理想。究其原因呀,有 1)知友们知识面广、思维发散,2)长尾,很多词语出现频次相对较低。
AC + 贝叶斯 > max { AC, 贝叶斯 }
考虑到上述问题,我们提出了利用 AC 自动机,根据设定的类别关键词圈定相应类别的内容,然后在每个类别里利用「贝叶斯」方法的思想准确过滤出垃圾内容。现在我们有了解决问题的思想(思想很重要),来看看我们具体是怎么利用 AC 和「贝叶斯」这两个神器,打造垃圾内容过滤的。直接上图,一图胜千言。
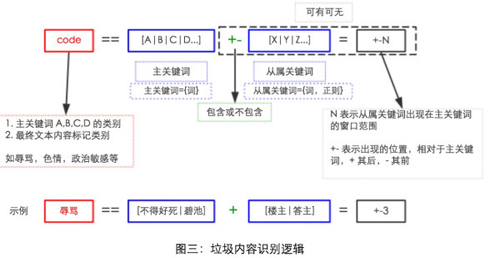
图三中「主关键词」就是利用 AC 自动机按关键词圈定相应类别的内容。圈定之后,利用「可有可无」这儿所配置的策略在每个类别里进行垃圾内容过滤,策略即是利用「贝叶斯」思想总结出来的。
下面以评论数据为例,介绍如何运用贝叶斯方法来总结策略。
首先,分析样本数据,提取每一个词,计算每个词在正常评论和垃圾评论中出现的频率。比如,我们假定「sb」这个词,在 1000 条垃圾评论中,有 500 条包含该词,那么它的出现频率就是0.5;而在 1000 条正常评论中,只有 2 条包含该词,那么出现频率就是0.002。那现在对一条新的评论,发现其中包含「sb」这个词,它是垃圾评论的概率可以通过式一计算。(此处用S和H分别表示垃圾评论和正常评论,W表示词 「sb」,P(S)表示垃圾评论的概率,P(W/S)表示垃圾评论中W出现的频率)
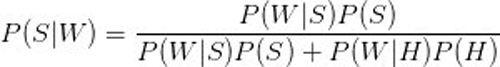
(式一)
在没有更多先验知识的情况下,我们通常假设P(S)=P(H=0.5)。那在前文的例子中,很容易计算出P(S/W)=0.996,说明「sb」词很容易区分出垃圾评论。通过这样的方式去挖掘出词语,当然也可以从正面角度考虑,比如「我」这个词,在我们的数据中能较好地区分出不是垃圾评论。此外,还可以考虑多个词语联合共现,甚至词之间的空间结构关系。这些在目前的逻辑里都是支持的。
有了具体实现,我们来看看实际的效果,如图四所示。(对于不利于讨论的内容也会被处理)
线上效果如图五所示。
这套逻辑已融入到了算法机器人「瓦力」的大脑中,在知乎的诸多场景下,如评论、私信、回答、提问等,以 99% 的准确率处理着每天产生的垃圾内容。每天处理掉 3000+ 条垃圾评论,上线后处理了站内上万条封建迷信提问、上千条代为完成个人任务、上千条求医问药等违规提问,帮助知友们维护起了一个「友善」的讨论环境。
此外,这套系统也十分方便运营人员实现一站式自助策略管理。首先通过样本制定策略,然后通过离线版本进行策略验证,评估其准确率和召回率,最后自助上线策略。整个过程均无需工程师的介入,大大提高了运营效率。
总结和展望
为了友善地讨论交流,我们踏出了这一小步,主动识别处理了诸多垃圾内容。但还有很长的路要走,后续我们将为机器人「瓦力」打造更加完善智能的大脑,如自动归纳策略,引入深度学习等,为其建立更加科学高效的识别能力,以全自动的方式准确地识别出所有内容。
虽以识别垃圾内容为出发点,建立了基于 AC 自动机和「贝叶斯」思想的内容识别系统,但这套系统还可以运用到其他场景,比如舆情、其他内容归类等,在这儿就不展开了。