在利用深度学习网络进行预测性分析之前,我们首先需要对其加以训练。目前市面上存在着大量能够用于神经网络训练的工具,但TensorFlow无疑是其中极为重要的首选方案之一。

大家可以利用TensorFlow训练自己的机器学习模型,并利用这些模型完成预测性分析。训练通常由一台极为强大的设备或者云端资源完成,但您可能想象不到的是,TensorFlow亦可以在iOS之上顺利起效——只是存在一定局限性。
在今天的博文中,我们将共同了解TensorFlow背后的设计思路、如何利用其训练一套简单的分类器,以及如何将上述成果引入您的iOS应用。
在本示例中,我们将使用“根据语音与对话分析判断性别”数据集以了解如何根据音频记录判断语音为男声抑或女声。数据集地址: https://www.kaggle.com/primaryobjects/voicegender
获取相关代码:大家可以通过GitHub上的对应项目获取本示例的源代码:https://github.com/hollance/TensorFlow-iOS-Example
TensorFlow是什么,我们为何需要加以使用?
TensorFlow是一套用于构建计算性图形,从而实现机器学习的软件资源库。
其它一些工具往往作用于更高级别的抽象层级。以Caffe为例,大家需要将不同类型的“层”进行彼此互连,从而设计出一套神经网络。而iOS平台上的BNNS与MPSCNN亦可实现类似的功能。
在TensorFlow当中,大家亦可处理这些层,但具体处理深度将更为深入——甚至直达您算法中的各项计算流程。
大家可以将TensorFlow视为一套用于实现新型机器学习算法的工具集,而其它深度学习工具则用于帮助用户使用这些算法。
当然,这并不是说用户需要在TensorFlow当中从零开始构建一切。TensorFlow拥有一整套可复用的构建组件,同时囊括了Keras等负责为TensorFlow用户提供大量便捷模块的资源库。
因此TensorFlow在使用当中并不强制要求大家精通相关数学专业知识,当然如果各位愿意自行构建,TensorFlow也能够提供相应的工具。
利用逻辑回归实现二元分类
在今天的博文当中,我们将利用逻辑回归(logistic regression)算法创建一套分类器。没错,我们将从零开始进行构建,因此请大家做好准备——这可是项有点复杂的任务。所谓分类器,其基本工作原理是获取输入数据,而后告知用户该数据所归属的类别——或者种类。在本项目当中,我们只设定两个种类:男声与女声——也就是说,我们需要构建的是一套二元分类器(binary classifier)。
备注:二元分类器属于最简单的一种分类器,但其基本概念与设计思路同用于区分成百上千种不同类别的分类器完全一致。因此,尽管我们在本份教程中不会太过深入,但相信大家仍然能够从中一窥分类器设计的门径。
在输入数据方面,我们将使用包含20个数字朗读语音、囊括多种声学特性的给定录音。我将在后文中对此进行详尽解释,包括音频频率及其它相关信息。
在以下示意图当中,大家可以看到这20个数字全部接入一个名为sum的小框。这些连接拥有不同的weights(权重),对于分类器而言代表着这20个数字各自不同的重要程度。
以下框图展示了这套逻辑分类器的起效原理:

在sum框当中,输入数据区间为x0到x19,且其对应连接的权重w0到w19进行直接相加。以下为一项常见的点积:
sum = x[0]*w[0] + x[1]*w[1] + x[2]*w[2] + ... + x[19]*w[19] + b
- 1.
我们还在所谓bias(偏离)项的末尾加上了b。其仅仅代表另一个数字。
数组w中的权重与值b代表着此分类器所学习到的经验。对该分类器进行训练的过程,实际上是为了帮助其找到与w及b正确匹配的数字。最初,我们将首先将全部w与b设置为0。在数轮训练之后,w与b则将包含一组数字,分类器将利用这些数字将输入语音中的男声与女声区分开来。为了能够将sum转化为一条概率值——其取值在0与1之间——我们在这里使用logistic sigmoid函数:
y_pred = 1 / (1 + exp(-sum))
- 1.
这条方程式看起来很可怕,但做法却非常简单:如果sum是一个较大正数,则sigmoid函数返回1或者概率为100%; 如果sum是一个较大负数,则sigmoid函数返回0。因此对于较大的正或者负数,我们即可得出较为肯定的“是”或者“否”预测结论。
然而,如果sum趋近于0,则sigmoid函数会给出一个接近于50%的概率,因为其无法确定预测结果。当我们最初对分类器进行训练时,其初始预期结果会因分类器本身训练尚不充分而显示为50%,即对判断结果并无信心。但随着训练工作的深入,其给出的概率开始更趋近于1及0,即分类器对于结果更为肯定。
现在y_pred中包含的预测结果显示,该语音为男声的可能性更高。如果其概率高于0.5(或者50%),则我们认为语音为男声; 相反则为女声。
这即是我们这套利用逻辑回归实现的二元分类器的基本设计原理。输入至该分类器的数据为一段对20个数字进行朗读的音频记录,我们会计算出一条权重sum并应用sigmoid函数,而我们获得的输出概率指示朗读者应为男性。
然而,我们仍然需要建立用于训练该分类器的机制,而这时就需要请出今天的主角——TensorFlow了。在TensorFlow中实现此分类器要在TensorFlow当中使用此分类器,我们需要首先将其设计转化为一套计算图(computational graph)。一项计算图由多个负责执行计算的节点组成,且输入数据会在各节点之间往来流通。
我们这套逻辑回归算法的计算图如下所示:

看起来与之前给出的示意图存在一定区别,但这主要是由于此处的输入内容x不再是20个独立的数字,而是一个包含有20个元素的向量。在这里,权重由矩阵W表示。因此,之前得出的点积也在这里被替换成了一项矩阵乘法。
另外,本示意图中还包含一项输入内容y。其用于对分类器进行训练并验证其运行效果。我们在这里使用的数据集为一套包含3168条example语音记录的集合,其中每条示例记录皆被明确标记为男声或女声。这些已知男声或女声结果亦被称为该数据集的label(标签),并作为我们交付至y的输入内容。
为了训练我们的分类器,这里需要将一条示例加载至x当中并允许该计算图进行预测:即语音到底为男声抑或是女声?由于初始权重值全部为0,因此该分类器很可能给出错误的预测。我们需要一种方法以计算其错误的“具体程度”,而这一目标需要通过loss函数实现。Loss函数会将预测结果y_pred与正确输出结果y进行比较。
在将loss函数提供给训练示例后,我们利用一项被称为backpropagation(反向传播)的技术通过该计算图进行回溯,旨在根据正确方向对W与b的权重进行小幅调整。如果预测结果为男声但实际结果为女声,则权重值即会稍微进行上调或者下调,从而在下一次面对同样的输入内容时增加将其判断为“女声”的概率。
这一训练规程会利用该数据集中的全部示例进行不断重复再重复,直到计算图本身已经获得了最优权重集合。而负责衡量预测结果错误程度的loss函数则因此随时间推移而变低。
反向传播在计算图的训练当中扮演着极为重要的角色,但我们还需要加入一点数学手段让结果更为准确。而这也正是TensorFlow的专长所在:我们只要将全部“前进”操作表达为计算图当中的节点,其即可自动意识到“后退”操作代表的是反向传播——我们完全无需亲自进行任何数学运算。太棒了!
Tensorflow到底是什么?
在以上计算图当中,数据流向为从左至右,即代表由输入到输出。而这正是TensorFlow中“流(flow)”的由来。不过Tensor又是什么?
Tensor一词本义为张量,而此计算图中全部数据流皆以张量形式存在。所谓张量,其实际代表的就是一个n维数组。我曾经提到W是一项权重矩阵,但从TensorFlow的角度来看,其实际上属于一项二阶张量——换言之,一个二组数组。
- 一个标量代表一个零阶张量。
- 一个向量代表一个一阶张量。
- 一个矩阵代表一个二阶张量。
- 一个三维数组代表一个三阶张量。
之后以此类推……
这就是Tensor的全部含义。在卷积神经网络等深度学习方案当中,大家会需要与四维张量打交道。但本示例中提到的逻辑分类器要更为简单,因此我们在这里最多只涉及到二阶张量——即矩阵。
我之前还提到过,x代表一个向量——或者说一个一阶张量——但接下来我们同样将其视为一个矩阵。y亦采用这样的处理方式。如此一来,我们即可将数据库组视为整体对其loss进行计算。
一条简单的示例(example)语音内包含20个数据元素。如果大家将全部3168条示例加载至x当中,则x会成为一个3168 x 20的矩阵。再将x与W相乘,则得出的结果y_pred为一个3168 x 1的矩阵。具体来讲,y_pred代表的是为数据集中的每条语音示例提供一项预测结论。
通过将我们的计算图以矩阵/张量的形式进行表达,我们可以一次性对多个示例进行预测。
安装TensorFlow
好的,以上是本次教程的理论基础,接下来进入实际操作阶段。
我们将通过Python使用TensorFlow。大家的Mac设备可能已经安装有某一Python版本,但其版本可能较为陈旧。在本教程中,我使用的是Python 3.6,因此大家最好也能安装同一版本。
安装Python 3.6非常简单,大家只需要使用Homebrew软件包管理器即可。如果大家还没有安装homebrew,请点击此处参阅相关指南。
接下来打开终端并输入以下命令,以安装Python的最新版本:
brew install python3
- 1.
Python也拥有自己的软件包管理器,即pip,我们将利用它安装我们所需要的其它软件包。在终端中输入以下命令:
pip3 install numpy
pip3 install scipy
pip3 install scikit-learn
pip3 install pandas
pip3 install tensorflow
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
除了TensorFlow之外,我们还需要安装NumPy、SciPy、pandas以及scikit-learn:
NumPy是一套用于同n级数组协作的库。听起来耳熟吗?NumPy并非将其称为张量,但之前提到了数组本身就是一种张量。TensorFlow Python API就建立在NumPy基础之上。
SciPy是一套用于数值计算的库。其它一些软件包的起效需要以之为基础。
pandas负责数据集的加载与清理工作。
scikit-learn在某种意义上可以算作TensorFlow的竞争对手,因为其同样是一套用于机器学习的库。我们之所以在本项目中加以使用,是因为它具备多项便利的功能。由于TensorFlow与scikit-learn皆使用NumPy数组,因为二者能够顺畅实现协作。
实际上,大家无需pandas与scikit-learn也能够使用TensorFlow,但二者确实能够提供便捷功能,而且每一位数据科学家也都乐于加以使用。
如大家所知,这些软件包将被安装在/usr/local/lib/python3.6/site-packages当中。如果大家需要查看部分未被公布在其官方网站当中的TensorFlow源代码,则可以在这里找到。
备注:pip应会为您的系统自动安装TensorFlow的最佳版本。如果大家希望安装其它版本,则请点击此处参阅官方安全指南。另外,大家也可以利用源代码自行构建TensorFlow,这一点我们稍后会在面向iOS构建TensorFlow部分中进行说明。
下面我们进行一项快速测试,旨在确保一切要素都已经安装就绪。利用以下内容创建一个新的tryit.py文件:
import tensorflow as tf
a = tf.constant([1, 2, 3])
b = tf.constant([4, 5, 6])
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print(sess.run(a + b))
- 1.
- 2.
- 3.
- 4.
- 5.
而后通过终端运行这套脚本:
python3 tryit.py
- 1.
其会显示一些与TensorFlow运行所在设备相关的调试信息(大多为CPU信息,但如果您所使用的Mac设备配备有英伟达GPU,亦可能提供GPU信息)。最终结果显示为:
[5 7 9]
- 1.
这里代表的是两个向量a与b的加和。另外,大家可能还会看到以下信息:
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.
- 1.
如果出现上述内容,则代表您在系统当中安装的TensorFlow并非当前CPU的最优适配版本。修复方法之一是利用源代码自行构建TensorFlow,因为这允许大家对全部选项加以配置。但在本示例当中,由于其不会造成什么影响,因此直接忽略即可。深入观察训练数据集
要训练分类器,我们自然需要数据。
在本项目当中,我们使用来自Kory Becker的“根据语音判断性别”数据集。为了能够让这份教程能够与TensorFlow指南上的MNIST数字化识别有所不同,这里我决定在Kaggle.com上寻找数据集,并最终选定了这一套。
那么我们到底该如何立足音频实现性别判断?下载该数据集并打开voice.csv文件之后,大家会看到其中包含着一排排数字:

我们首先需要强调这一点,这里列出的并非实际音频数据!相反,这些数字代表着语音记录当中的不同声学特征。这些属性或者特征由一套脚本自音频记录中提取得出,并被转化为这个CSV文件。具体提取方式并不属于本篇文章希望讨论的范畴,但如果大家感兴趣,则可点击此处查阅其原始R源代码。
这套数据集中包含3168项示例(每项示例在以上表格中作为一行),且基本半数为男声录制、半数为女声录制。每一项示例中存在20项声学特征,例如:
- 以kHz为单位的平均频率
- 频率的标准差
- 频谱平坦度
- 频谱熵
- 峰度
- 声学信号中测得的最大基频
- 调制指数
- 等等……
别担心,虽然我们并不了解其中大多数条目的实际意义,但这不会影响到本次教程。我们真正需要 关心的是如何利用这些数据训练自己的分类器,从而立足于上述特征确保其有能力区分男性与女性的语音。
如果大家希望在一款应用程序当中使用此分类器,从而通过录音或者来自麦克风的音频信息检测语音性别,则首先需要从此类音频数据中提取声学特征。在拥有了这20个数字之后,大家即可对其分类器加以训练,并利用其判断语音内容为男声还是女声。
因此,我们的分类器并不会直接处理音频记录,而是处理从记录中提取到的声学特征。
备注:我们可以以此为起点了解深度学习与逻辑回归等传统算法之间的差异。我们所训练的分类器无法学习非常复杂的内容,大家需要在预处理阶段提取更多数据特征对其进行帮助。在本示例的特定数据集当中,我们只需要考虑提取音频记录中的音频数据。
深度学习最酷的能力在于,大家完全可以训练一套神经网络来学习如何自行提取这些声学特征。如此一来,大家不必进行任何预处理即可利用深度学习系统采取原始音频作为输入内容,并从中提取任何其认为重要的声学特征,而后加以分类。
这当然也是一种有趣的深度学习探索方向,但并不属于我们今天讨论的范畴,因此也许日后我们将另开一篇文章单独介绍。
建立一套训练集与测试集
在前文当中,我提到过我们需要以如下步骤对分类器进行训练:
- 向其交付来自数据集的全部示例。
- 衡量预测结果的错误程度。
- 根据loss调整权重。
事实证明,我们不应利用全部数据进行训练。我们只需要其中的特定一部分数据——即测试集——从而评估分类器的实际工作效果。因此,我们将把整体数据集拆分为两大部分:训练集,用于对分类器进行训练; 测试集,用于了解该分类器的预测准确度。
为了将数据拆分为训练集与测试集,我创建了一套名为split_data.py的Python脚本,其内容如下所示:
import numpy as np # 1
import pandas as pd df = pd.read_csv("voice.csv", header=0) #2
labels = (df["label"] == "male").values * 1 # 3
labels = labels.reshape(-1, 1) # 4
del df["label"] # 5
data = df.values
# 6
from sklearn.model_selection import train_test_split X_train,
X_test, y_train, y_test = train_test_split(data, labels, test_size=0.3, random_state=123456)
np.save("X_train.npy", X_train) # 7
np.save("X_test.npy", X_test)
np.save("y_train.npy", y_train)
np.save("y_test.npy", y_test)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
下面我们将分步骤了解这套脚本的工作方式:
- 首先导入NumPy与pandas软件包。Pandas能够轻松实现CSV文件的加载,并对数据进行预处理。
- 利用pandas从voice.csv加载数据集并将其作为dataframe。此对象在很大程度上类似于电子表格或者SQL表。
- 这里的label列包含有该数据集的各项标签:即该示例为男声或者女声。在这里,我们将这些标签提取进一个新的NumPy数组当中。各原始标签为文本形式,但我们将其转化为数字形式,其中1=男声,0=女声。(这里的数字赋值方式可任意选择,在二元分类器中,我们通常使用1表示‘正’类,或者说我们试图检测的类。)
- 这里创建的新labels数组是一套一维数组,但我们的TensorFlow脚本则需要一套二维张量,其中3168行中每一行皆对应一列。因此我们需要在这里对数组进行“重塑”,旨在将其转化为二维形式。这不会对内存中的数据产生影响,而仅变化NumPy对数据的解释方式。
- 在完成label列之后,我们将其从dataframe当中移除,这样我们就只剩下20项用于描述输入内容的特征。我们还将把该dataframe转换为一套常规NumPy数组。
- 这里,我们利用来自scikit-learn的一项helper函数将data与labels数组拆分为两个部分。这种对数据集内各示例进行随机洗牌的操作基于random_state,即一类随机生成器。无论具体内容为何,但只要青筋相同内容,我们即创造出了一项可重复进行的实验。
- 最后,将四项新的数组保存为NumPy的二进制文件格式。现在我们已经拥有了一套训练集与一套测试集!
大家也可以进行额外的一些预处理对脚本中的数据进行调整,例如对特征进行扩展,从而使其拥有0均值及相等的方差,但由于本次示例项目比较简单,所以并无深入调整的必要。
利用以下命令在终端中运行这套脚本:
python3 split_data.py
- 1.
这将给我们带来4个新文件,其中包含有训练救命(X_train.npy)、这些示例的对应标签(y_train.npy)、测试示例(X_test.npy)及其对应标签(y_test.npy)。
备注:大家可能想了解为什么这些变量名称为何有些是大写,有些是小写。在数学层面来看,矩阵通常以大写表示而向量则以小写表示。在我们的脚本中,X代表一个矩阵,y代表一个向量。这是一种惯例,大部分机器学习代码中皆照此办理。
建立计算图
现在我们已经对数据进行了梳理,而后即可编写一套脚本以利用TensorFlow对这套逻辑分类器进行训练。这套脚本名为train.py。为了节省篇幅,这里就不再列出脚本的具体内容了,大家可以点击此处在GitHub上进行查看。
与往常一样,我们首先需要导入需要的软件包。在此之后,我们将训练数据加载至两个NumPy数组当中,即X_train与y_train。(我们在本脚本中不会使用测试数据。)
import numpy as np
import tensorflow as tf
X_train = np.load("X_train.npy")
y_train = np.load("y_train.npy")
- 1.
- 2.
- 3.
- 4.
现在我们可以建立自己的计算图。首先,我们为我们的输入内容x与y定义所谓placeholders(占位符):
num_inputs = 20
num_classes = 1
with tf.name_scope("inputs"):
x = tf.placeholder(tf.float32, [None, num_inputs], name="x-input")
y = tf.placeholder(tf.float32, [None, num_classes], name="y-input")
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
其中tf.name_scope("...")可用于对该计算图中的不同部分按不同范围进行分组,从而简化对计算图内容的理解。我们将x与y添加至“inputs”范围之内。我们还将为其命名,分别为“x-input”与“y-input”,这样即可在随后轻松加以引用。
大家应该还记得,每条输入示例都是一个包含20项元素的向量。每条示例亦拥有一个标签(1代表男声,0代表女声)。我之前还提到过,我们可以将全部示例整合为一个矩阵,从而一次性对其进行全面计算。正因为如此,我们这里将x与y定义为二维张量:x拥有[None, 20]维度,而y拥有[None, 1]维度。
其中的None代表第一项维度为灵活可变且目前未知。在训练集当中,我们将2217条示例导入x与y; 而在测试集中,我们引入951条示例。现在,TensorFlow已经了解了我们的输入内容,接下来对分类器的parameters(参数)进行定义:
with tf.name_scope("model"):
W = tf.Variable(tf.zeros([num_inputs, num_classes]), name="W")
b = tf.Variable(tf.zeros([num_classes]), name="b")
- 1.
- 2.
- 3.
其中的张量W包含有分类器将要学习的权重(这是一个20 x 1矩阵,因为其中包含20条输入特征与1条输出结果),而b则包含偏离值。这二者被声明为TensorFlow变量,意味着二者可在反向传播过程当中实现更新。
在一切准备就绪之后,我们可以对作为逻辑回归分类器核心的计算流程进行声明了:
y_pred = tf.sigmoid(tf.matmul(x, W) + b)
- 1.
这里将x与W进行相乘,同时加上偏离值b,而后取其逻辑型成长曲线(logistic sigmoid)。如此一来,y_pred中的结果即根据x内音频数据的描述特性而被判断为男声的概率。
备注:以上代码目前实际还不会做出任何计算——截至目前,我们还只是构建起了必要的计算图。这一行单纯是将各节点添加至计算图当中以作为矩阵乘法(tf.matmul)、加法(+)以及sigmoid函数(tf.sigmoid)。在完成整体计算图的构建之后,我们方可创建TensorFlow会话并利用实际数据加以运行。
到这里任务还未完成。为了训练这套模型,我们需要定义一项loss函数。对于一套二元逻辑回归分类器,我们需要使用log loss,幸运的是TensorFlow本身内置有一项log_loss()函数可供直接使用:
with tf.name_scope("loss-function"):
loss = tf.losses.log_loss(labels=y, predictions=y_pred)
loss += regularization * tf.nn.l2_loss(W)
- 1.
- 2.
- 3.
其中的log_loss计算图节点作为输入内容y,我们会获取与之相关的示例标签并将其与我们的预测结果y_pred进行比较。以数字显示的结果即为loss值。
在刚开始进行训练时,所有示例的预测结果y_pred皆将为0.5(或者50%男声),这是因为分类器本身尚不清楚如何获得正确答案。其初始loss在经-1n(0.5)计算后得出为0.693146。而在训练的推进当中,其loss值将变得越来越小。
第二行用于计算loss值与所谓L2 regularization(正则化)的加值。这是为了防止过度拟合阻碍分类器对训练数据的准确记忆。这一过程比较简单,因为我们的分类器“内存”只包含20项权重值与偏离值。不过正则化本身是一种常见的机器学习技术,因此在这里必须一提。
这里的regularization值为另一项占位符:
with tf.name_scope("hyperparameters"):
regularization = tf.placeholder(tf.float32, name="regularization")
learning_rate = tf.placeholder(tf.float32, name="learning-rate")
- 1.
- 2.
- 3.
我们还将利用占位符定义我们的输入内容x与y,不过二者的作用是定义hyperparameters。
Hyperparameters允许大家对这套模型及其具体训练方式进行配置。其之所以被称为“超”参数,是因为与常见的W与b参数不同,其并非由模型自身所学习——大家需要自行将其设置为适当的值。
其中的learning_rate超参数负责告知优化器所应采取的调整幅度。该优化器(optimizer)负责执行反向传播:其会提取loss值并将其传递回计算图以确定需要对权重值与偏离值进行怎样的调整。这里可以选择的优化器方案多种多样,而我们使用的为ADAM:
with tf.name_scope("train"):
optimizer = tf.train.AdamOptimizer(learning_rate)
train_op = optimizer.minimize(loss)
- 1.
- 2.
- 3.
其能够在计算图当中创建一个名为train_op的节点。我们稍后将运行此节点以训练分类器。为了确定该分类器的运行效果,我们还需要在训练当中偶尔捕捉快照并计算其已经能够在训练集当中正确预测多少项示例。训练集的准确性并非分类器运行效果的最终检验标准,但对其进行追踪能够帮助我们在一定程度上把握训练过程与预测准确性趋势。具体来讲,如果越是训练结果越差,那么一定是出了什么问题!
下面我们为一个计算图节点定义计算精度:
with tf.name_scope("score"):
correct_prediction = tf.equal(tf.to_float(y_pred > 0.5), y)
accuracy = tf.reduce_mean(tf.to_float(correct_prediction), name="accuracy")
- 1.
- 2.
- 3.
我们可以运行其中的accuracy节点以查看有多少个示例得到了正确预测。大家应该还记得,y_pred中包含一项介于0到1之间的概率。通过进行tf.to_float(y_pred > 0.5),若预测结果为女声则返回值为0,若预测结果为男声则返回值为1。我们可以将其与y进行比较,y当中包含有正确值。而精度值则代表着正确预测数量除以预测总数。
在此之后,我们将利用同样的accuracy节点处理测试集,从而了解这套分类器的实际工作效果。
另外,我们还需要定义另外一个节点。此节点用于对我们尚无对应标签的数据进行预测:
with tf.name_scope("inference"):
inference = tf.to_float(y_pred > 0.5, name="inference")
- 1.
- 2.
为了将这套分类器引入应用,我们还需要记录几个语音文本词汇,对其进行分析以提取20项声学特征,而后再将其交付至分类器。由于处理内容属于全新数据,而非来自训练或者测试集的数据,因此我们显然不具备与之相关的标签。大家只能将数据直接交付至分类器,并希望其能够给出正确的预测结果。而inference节点的作用也正在于此。
好的,我们已经投入了大量精力来构建这套计算图。现在我们希望利用训练集对其进行实际训练。
训练分类器
训练通常以无限循环的方式进行。不过对于这套简单的逻辑分类器,这种作法显然有点夸张——因为其不到一分钟即可完成训练。但对于深层神经网络,我们往往需要数小时甚至数天时间进行脚本运行——直到其获得令人满意的精度或者您开始失去耐心。
以下为train.py当中训练循环的第一部分:
with tf.Session() as sess:
tf.train.write_graph(sess.graph_def, checkpoint_dir, "graph.pb", False)
sess.run(init)
step = 0
while True:
# here comes the training code
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
我们首先创建一个新的TensorFlow session(会话)对象。要运行该计算图,大家需要建立一套会话。调用sess.run(init)会将W与b全部重设为0。
我们还需要将该计算图写入一个文件。我们将之前创建的全部节点序列至/tmp/voice/graph.pb文件当中。我们之后需要利用此计算图定义以立足测试集进行分类器运行,并尝试将该训练后的分类器引入iOS应用。
在while True:循环当中,我们使用以下内容:
perm = np.arange(len(X_train))
np.random.shuffle(perm)
X_train = X_train[perm]
y_train = y_train[perm]
- 1.
- 2.
- 3.
- 4.
首先,我们对训练示例进行随机洗牌。这一点非常重要,因为大家当然不希望分类器根据示例的具体顺序进行判断——而非根据其声学特征进行判断。
接下来是最重要的环节:我们要求该会话运行train_op节点。其将在计算图之上运行一次训练:
feed = {x: X_train, y: y_train, learning_rate: 1e-2,
regularization: 1e-5}
sess.run(train_op, feed_dict=feed)
- 1.
- 2.
- 3.
在运行sess.run()时,大家还需要提供一套馈送词典。其将负责告知TensorFlow当前占位符节点的实际值。
由于这只是一套非常简单的分类器,因此我们将始终一次性对全部训练集进行训练,所以这里我们将X_train数组引入占位符x并将y_train数组引入占位符y。(对于规模更大的数据集,大家可以先从小批数据内容着手,例如将示例数量设定为100到1000之间。)
到这里,我们的操作就阶段性结束了。由于我们使用了无限循环,因此train_op节点会反复再反复加以执行。而在每一次迭代时,其中的反向传播机制都会对权重值W与b作出小幅调整。随着时间推移,这将令权重值逐步趋近于最优值。
我们当然有必要了解训练进度,因此我们需要经常性地输出进度报告(在本示例项目中,每进行1000次训练即输出一次结果):
if step % print_every == 0:
train_accuracy, loss_value = sess.run([accuracy, loss], feed_dict=feed)
print("step: %4d, loss: %.4f, training accuracy: %.4f" % \
(step, loss_value, train_accuracy))
- 1.
- 2.
- 3.
- 4.
这一次我们不再运行train_op节点,而是运行accuracy与loss两个节点。我们使用同样的馈送词典,这样accuracy与loss都会根据训练集进行计算。正如之前所提到,训练集中的较高预测精度并不代表分类器能够在处理测试集时同样拥有良好表现,但大家当然希望随着训练的进行其精度值不断提升。与此同时,loss值则应不断下降。
另外,我们还需要时不时保存一份checkpoint:
if step % save_every == 0:
checkpoint_file = os.path.join(checkpoint_dir, "model")
saver.save(sess, checkpoint_file)
print("*** SAVED MODEL ***")
- 1.
- 2.
- 3.
- 4.
其会获取分类器当前已经学习到的W与b值,并将其保存为一个checkpoint文件。此checkpoint可供我们参阅,并判断分类器是否已经可以转而处理测试集。该checkpoinit文件同样被保存在/tmp/voice/目录当中。
使用以下命令在终端中运行该训练脚本:
python3 train.py
- 1.
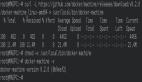
输出结果应如下所示:
Training set size: (2217, 20)
Initial loss: 0.693146
step: 0, loss: 0.7432, training accuracy: 0.4754
step: 1000, loss: 0.4160, training accuracy: 0.8904
step: 2000, loss: 0.3259, training accuracy: 0.9170
step: 3000, loss: 0.2750, training accuracy: 0.9229
step: 4000, loss: 0.2408, training accuracy: 0.9337
step: 5000, loss: 0.2152, training accuracy: 0.9405
step: 6000, loss: 0.1957, training accuracy: 0.9553
step: 7000, loss: 0.1819, training accuracy: 0.9594
step: 8000, loss: 0.1717, training accuracy: 0.9635
step: 9000, loss: 0.1652, training accuracy: 0.9666
*** SAVED MODEL ***
step: 10000, loss: 0.1611, training accuracy: 0.9702
step: 11000, loss: 0.1589, training accuracy: 0.9707
. . .
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
当发现loss值不再下降时,就稍等一下直到看到下一条*** SAVED MODEL ***信息,这时按下Ctrl+C以停止训练。
在超参数设置当中,我选择了正规化与学习速率,大家应该会看到其训练集的准确率已经达到约97%,而loss值则约为0.157。(如果大家在馈送词典中将regularization设置为0,则loss甚至还能够进一步降低。)
上半部分到此结束,下半部分我们将察看训练的实际效果,以及如何在iOS上使用TensorFlow,最后讨论一下iOS上使用TensorFlow的优劣。