1 新智元编译
来源:arXiv、Github
编译:张易
【新智元导读】自动图像补全是计算机视觉和图形领域几十年来的研究热点和难点。在神经网络的帮助下,来自伯克利、Adobe 等研究人员利用组合优化和类似风格转移的方法,突破以往技术局限,成功实现了超逼真的“从0到1”图像生成。代码已在Github 开源。
 完胜 PS!新方法实现完美“脑补”
完胜 PS!新方法实现完美“脑补”
在分享照片之前,你可能会想进行一些修改,例如擦除分散注意力的场景元素,调整图像中的物体位置以获得更好的组合效果,或者把被遮挡的部分恢复出来。
这些操作,以及其他许多编辑操作,需要进行自动的孔洞填充(图像补足),这是过去几十年间计算机视觉和图形领域的一个研究热点。因为自然图像固有的模糊性和复杂性,整体填充也是长期以来的难点。
但现在,这个问题终于得到了比较好的解决,证据就是下面这幅图。

这项全新研究的主要贡献是:
-
提出了一个联合优化框架,可以通过用卷积神经网络为全局内容约束和局部纹理约束建模,来虚构出缺失的图像区域。
-
进一步介绍了基于联合优化框架的用于高分辨率图像修复的多尺度神经补丁合成算法。
-
在两个公共数据集上评估了所提出的方法,并证明了其优于基线和现有技术的优势。
克服现有方法局限,用深度学习风格转移合成逼真细节
我们稍后会详细介绍这项研究成果。在此之前,有必要补充一下背景知识。
现有的解决孔洞填充问题的方法分为两组。第一组方法依赖于纹理合成技术,其通过扩展周围区域的纹理来填充空白。这些技术的共同点是使用相似纹理的补丁,以从粗到精的方式合成孔洞的内容。有时,会引入多个尺度和方向,以找到更好的匹配补丁。Barnes et al.(2009) 提出了 PatchMatch,这是一种快速近似最近邻补丁的搜索算法。
尽管这样的方法有益于传递高频纹理细节,但它们不抓取图像的语义或全局结构。第二组方法利用大型外部数据库,以数据驱动的方式虚构缺失的图像区域。这些方法假定被相似上下文包围的区域可能具有相似的内容。如果能找到和所查询图像具有足够视觉相似度的图像样本,这种方法会非常有效,但是当查询图像在数据库中没有被很好地表示时,该方法可能会失败。另外,这样的方法需要访问外部数据库,这极大地限制了可能的应用场景。
最近,深度神经网络被用于纹理合成和图像的风格化(stylization)。特别需要指出,Phatak et al(2016)训练了具有结合了和对抗性损失的编码器 - 解码器 CNN(Context Encoders)来直接预测丢失的图像区域。这项工作能够预测合理的图像结构,并且评估非常快,因为孔洞区域的预测是在a single forward pass中进行的。虽然结果令人鼓舞,但有时这种方法的修复结果缺乏精细的纹理细节,在空白区域的边界周围会产生可见的伪迹。 这种方法也不能处理高分辨率图像,因为当输入较大时,和对抗性损失相关的训练会有困难。
在最近的一项研究中,Li和Wand(2016)指出,通过对图像进行优化(该图像的中间层神经响应与内容图像相似,底层卷局部响应模仿style图像的局部响应),可以实现逼真的图像stylization结果。那些局部响应由小的(通常3×3)神经补丁表示。 该方法证明能够将高频率细节从style图像传输到内容图像,因此适合于实际的传递任务(例如,传递面部或汽车的外观)。尽管如此,通过使用神经响应的 gram matrices 能更好地进行更多艺术风格的传递。
好,是主角出场的时候了——
为了克服上述方法的局限性,来自伯克利、Adobe、Pinscreen 和 USC Institute for Creative Technologies 的研究人员提出了一种混合优化方法(joint optimization),利用编码器 - 解码器CNN的结构化预测和神经补丁的力量,成功合成了实际的高频细节。类似于风格转移,他们的方法将编码器 - 解码器预测作为全局内容约束,并且将孔洞和已知区域之间的局部神经补丁相似性作为风格(style)约束。
更具体地说,使用中间层的补丁响应(该中间层使用预训练分类网络),可以通过训练类似于 Context Encoder 的全局内容预测网络来构造内容约束,并且可以用环绕孔洞的图像内容来对纹理约束进行建模。可以使用具有有限存储的 BFGS 的反向传递算法来有效地优化这两个约束。
作者在论文中写道:“我们通过实验证明,新提出的多尺度神经补丁合成方法可以产生更多真实和连贯的结果,保留结构和纹理的细节。我们在两个公共数据集上定量和定性地评估了所提出的方法,并证明了其在各种基线和现有技术上的有效性,如图1 所示。”

图1:对于给定的一张带有孔洞(256×256)的图像(512×512),我们的算法可以合成出更清晰连贯的孔洞内容(d)。我们可以和用Context Encoders(b)、PatchMatch(c)这两种方法产生的结果进行比较。
具体方法
为了进一步处理带有大面积孔洞的高分辨率图像,作者提出了一种多尺度神经补丁合成方法。为了简化公式,假设测试图像始终裁剪为 512×512,中间有一个 256×256 的孔洞。然后,创建一个三级金字塔,步长为二,在每个级别将图像缩小一半。它呈现 128×128 的最低分辨率,带有 64×64 的孔洞。接下来,我们以从粗到精的方式执行孔洞填充任务。初始化最低级别的内容预测网络的输出,在每个尺度(1)执行联合优化以更新孔洞;(2)upsample 以初始化联合优化并为下一个尺度设置内容约束。最后,重复此步骤,直到联合优化以最高分辨率完成。
Framework 概述
我们寻求对损失函数进行了优化的修复图像,其被表示为三个项的组合:整体内容项,局部纹理项和tv-loss项。 内容项是捕获图像的语义和全局结构的全局结构约束,并且局部项通过使其与已知区域一致来重新定义局部纹理。 内容项和纹理项均使用具有固定参数的预训练网络来计算。
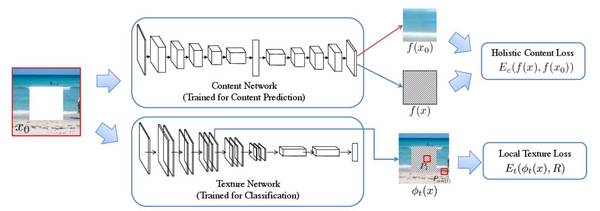
图2. Framework 概述。我们的方法使用两个联合损失函数来解决未知图像,即整体内容损失和局部纹理损失。通过将图像馈送到预训练的内容预测网络,并且将输出与推理(reference)内容预测进行比较来导出整体内容损失。 通过将 x 馈送到预训练网络(称为纹理网络),并且在其特征图上比较局部神经补丁来导出局部纹理损失。
高分辨率图像修复的算法
给定一个带有孔洞的高分辨率图像,我们产生了多尺度输入其中S是尺度的数量。s = 1是最粗糙的尺度,s = S是输入图像的原始分辨率。我们以迭代多尺度方式进行这一优化。
我们首先将输入缩小到粗糙尺度,计算内容的推理(reference)。在实际操作中,我们在 upsample 到一个新尺度时,将宽度和高度加倍。 在每个尺度中,我们根据等式 1 更新,通过 upsample 设置优化初始,并通过 upsample 在尺度上设置内容 reference。我们因此迭代地取得高分辨率的修复结果。算法1 是对该算法的总结。

实验过程
数据集
我们在两个不同的数据集上评估了我们提出的方法:Paris StreetView 和ImageNet 。 不使用与这些图像相关联的标签或其他信息。 Paris StreetView 包含 14,900 个训练图像和 100个测试图像。 ImageNet 有 1,260,000 个训练图像,以及从验证集随机选取的 200 个测试图像。 我们还选择了20个含干扰项的图像,以测试我们用于真实干扰项移除场景的算法。
量化比较
我们首先在 Paris StreetView 数据集上就低分辨率图像(128×128)将我们的方法和基线方法进行了定量比较。表1中的结果表明,我们的方法实现了最高的数值性能。我们将这归因于我们方法的性质——和 PatchMatch 相比,它能够推断图像的正确结构,而和 Context Encoder 相比,它能够从已知区域传递纹理细节。(图3)我们优于PatchMatch的结果表明,内容网络有助于预测合理的结构。我们胜过 Context Encoder 的结果表明,由纹理网络执行的神经补丁合成方法的有效性。
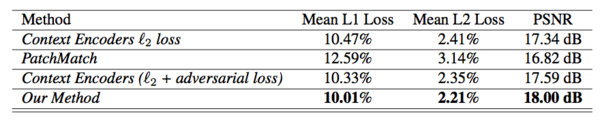
表1:在Paris StreetView数据集上的数值比较。PSNR值越高越好。

图3:Context Encoder(损失)、Context Encoders(对抗性损失)和PatchMatch的比较。当从边界向孔洞区域传递纹理时,我们的方法比Context Encoder(既使用损失也使用对抗性损失)表现更好。在推理正确结构时,我们的方法比PatchMatch表现更好。
内容网络在联合优化中的作用。我们比较了使用内容约束和不使用内容约束的修复结果。如图4 所示,当不使用内容项来引导优化时,修复结果的结构出错了。

图4:(a)为原始输入,(b)是不使用内容约束产生的修复结果,(c)是我们的结果。
高分辨率图像修复

图5是在ImageNet数据集上的比较结果。从上至下:原始输入,PatchMatch,Context Encoder(同时使用和对抗性损失),我们的结果。所有图像分辨率都是512×512(本文中已缩小以适应页面显示)。

图6是在Paris StreetView数据集上的比较结果。从上至下:原始输入,PatchMatch,Context Encoder(同时使用和对抗性损失),我们的结果。所有图像分辨率都是512×512(本文中已缩小以适应页面显示)。
真实世界干扰项去除场景
最后,我们的算法很容易扩展为处理任意形状的孔洞。 这是通过估计任意孔洞周围的边界平方,填充孔洞内的平均像素值,并通过裁剪图像形成输入,以使正方形边界框处于输入的中心,并将输入调整为内容网络输入的大小。然后,我们使用已经训练的内容网络进行前向传播。在联合优化中,纹理网络对自然中孔洞的形状和位置没有限制。这是分离将内容和纹理项分离的额外好处。由于 Context Encoder 仅限于方孔,我们在图7中展示了和 PatchMatch 的对比结果。如图所示,我们提出的联合优化方法更好地预测了结构,并提供了清晰和逼真的结果。

图7:随意对象的去除。从左到右:原始输入,对象遮挡,PatchMatch 结果,我们的结果。
结论
作者使用神经补丁合成提升了语义修复的现有技术。可以看到,当内容网络给出较强的关于语义和全局结构的先验信息时,纹理网络在生成高频细节方面非常强大。有一些场景复杂的情况,这种新的方法会产生不连续性和违背真实的图像(图8)。此外,速度仍然是这种算法的瓶颈。研究人员的目标是在未来的工作中解决这些问题。

图8:这是两个联合优化法失败的例子。
论文:使用多尺度神经补丁合成修补高分辨率图像

摘要
对于带有语义合理性和情境感知细节的自然图像,深度学习的最新进展为填充这些图像上的大面积孔洞带来了乐观的前景,并影响了诸如对象移除这样的基本的图像处理任务。虽然这些基于学习的方法在捕获高级特征方面比现有技术明显更有效,但由于存储器限制和训练困难,它们只能处理分辨率很低的输入。即使对于稍大的图像,修复的区域也会显得模糊,而且可以看到令人不快的边界。我们提出一种基于图像内容和风格(style)约束联合优化的多尺度神经补丁合成方法,不仅保留上下文结构,而且通过匹配和适应具有与深度分类网络相似的中层特性的补丁,可以产生高频细节。我们在 ImageNet 和 Paris Streetview 数据集上评估了我们的方法,并实现了最先进的修复精度。我们表明,相对于之前的方法,我们的方法可以产生更清晰和更连贯的结果,特别是对于高分辨率图像来说。
论文地址:https://arxiv.org/pdf/1611.09969.pdf
Github 代码:https://github.com/leehomyc/High-Res-Neural-Inpainting