1. 谈谈Openstack的发展历史
OpenStack是一个面向IaaS层的云管理平台开源项目,用于实现公有云和私有云的部署及管理。最开始Openstack只有两个组件,分别为提供计算服务的Nova项目以及提供对象存储服务的Swift,其中Nova不仅提供虚拟机服务,还包含了网络服务、块存储服务、镜像服务以及裸机管理服务。之后随着项目的不断发展,从Nova中拆分成多个独立的项目各自提供不同的服务,如拆分为Cinder项目提供块存储服务,拆分为Glance项目,提供镜像服务,nova-network则是neutron的前身,裸机管理也从Nova中分离出来为Ironic项目。最开始容器服务也是由Nova提供支持的,作为Nova的driver之一来实现,而后迁移到Heat,到现在已经分离成独立的项目Magnum,后来Magnum主要提供容器编排服务,单纯的容器服务由Zun项目负责。最开始Openstack并没有认证功能,从E版开始才加入认证服务Keystone,至此Openstack 6个核心服务才终于聚齐了。
- Keystone 认证服务。
- Glance 镜像服务。
- Nova 计算服务。
- Cinder 块存储服务。
- Neutorn 网络服务。
- Swift 对象存储服务。
E版之后,在这些核心服务之上,又不断涌现新的服务,如面板服务Horizon、服务编排服务Heat、数据库服务Trove、文件共享服务Manila、大数据服务Sahara以及前面提到的Magnum等,这些服务几乎都依赖于以上的核心服务。比如Sahara大数据服务会先调用Heat模板服务,Heat又会调用Nova创建虚拟机,调用Glance获取镜像,调用Cinder创建数据卷,调用Neutron创建网络等。还有一些项目围绕Openstack部署的项目,比如Puppet-openstack、Kolla、TripleO、Fuel等项目。
截至现在(2016年11月27日),Openstack已经走过了6年半的岁月,***发布的版本为第14个版本,代号为Newton,Ocata版已经处在快速开发中。
Openstack服务越来越多、越来越复杂,并且不断变化发展。以Nova为例,从最开始使用nova-conductor代理数据库访问增强安全性,引入objects对象模型来支持对象版本控制,现在正在开发Cell项目来支持大规模的集群部署以及将要分离的Nova-EC2项目,截至到现在Nova包含nova-api、nova-conductor、nova-scheduler、nova-compute、nova-cell、nova-console等十多个组件。这么庞大的分布式系统需要深刻理解其工作原理,理清它们的交互关系非常不容易,尤其对于新手来说。
2.工欲善其事,必先利其器
由于Openstack使用python语言开发,而python是动态类型语言,参数类型不容易从代码中看出,因此首先需要部署一个allinone的Openstack开发测试环境,建议使用RDO部署:Packstack quickstart,当然乐于折腾使用devstack也是没有问题的。
其次需要安装科学的代码阅读工具,图形界面使用pycharm没有问题,不过通常在虚拟机中是没有图形界面的,***vim,需要简单的配置使其支持代码跳转和代码搜索,可以参考我的vim配置GitHub - int32bit/dotfiles: A set of vim, zsh, git, and tmux configuration files。
掌握python的调试技巧,推荐pdb、ipdb、ptpdb,其中ptpdb***用,不过需要手动安装。打断点前需要注意代码执行时属于哪个服务组件,nova-api的代码,你跑去nova-compute里打断点肯定没用。另外需要注意打了断点后的服务必须在前端运行,不能在后台运行,比如我们在nova/compute/manager.py中打了断点,我们需要kill掉后台进程:
systemctl stop openstack-nova-compute
- 1.
然后直接在终端运行nova-compute即可。
su -c 'nova-compute' nova
- 1.
3 .教你阅读的正确姿势
学习Openstack的***步骤是:
- 看文档
- 部署allineone
- 使用之
- 折腾之、怒斥之
- 部署多节点
- 深度使用、深度吐槽
- 阅读源码
- 混社区,参与社区开发
阅读源码的首要问题就是就要对代码的结构了然于胸,需要强调的是,Openstack项目的目录结构并不是根据组件划分的,而是根据功能划分的,以Nova为例,compute目录并不是一定在nova-compute节点上运行的代码,而主要是和compute相关(虚拟机操作相关)的功能实现,同样的,scheduler目录代码并不全在scheduler服务节点运行,但主要是和调度相关的代码。好在目录结构并不是完全混乱的,它是有规律的。
通常一个服务的目录都会包含api.py、rpcapi.py、manager.py,这个三个是最重要的模块。
- api.py: 通常是供其它组件调用的库。换句话说,该模块通常并不会由本模块调用。比如compute目录的api.py,通常由nova-api服务的controller调用。
- rpcapi.py:这个是RPC请求的封装,或者说是RPC实现的client端,该模块封装了RPC请求调用。
- manager.py: 这个才是真正服务的功能实现,也是RPC的服务端,即处理RPC请求的入口,实现的方法通常和rpcapi实现的方法对应。
前面提到Openstack项目的目录结构是按照功能划分的,而不是服务组件,因此并不是所有的目录都能有对应的组件。仍以Nova为例:
- cmd:这是服务的启动脚本,即所有服务的main函数。看服务怎么初始化,就从这里开始。
- db: 封装数据库访问,目前支持的driver为sqlalchemy。
- conf:Nova的配置项声明都在这里。
- locale: 本地化处理。
- image: 封装Glance调用接口。
- network: 封装网络服务接口,根据配置不同,可能调用nova-network或者neutron。
- volume: 封装数据卷访问接口,通常是Cinder的client封装。
- virt: 这是所有支持的hypervisor驱动,主流的如libvirt、xen等。
- objects: 对象模型,封装了所有实体对象的CURD操作,相对以前直接调用db的model更安全,并且支持版本控制。
- policies: policy校验实现。
- tests: 单元测试和功能测试代码。
根据进程阅读源码并不是什么好的实践,因为光理解服务如何初始化、如何通信、如何发送心跳等就不容易,各种高级封装太复杂了。而我认为比较好的阅读源码方式是追踪一个任务的执行过程,比如追踪启动一台虚拟机的整个流程。
不管任何操作,一定是先从API开始的,RESTFul API是Openstack服务的唯一入口,也就是说,阅读源码就从api开始。而api组件也是根据实体划分的,不同的实体对应不同的controller,比如servers、flavors、keypairs等,controller通常对应有如下方法:
- index: 获取资源列表,一般对应RESTFul API的URL为“GET /resources”,如获取虚拟机的列表API为“GET /servers”。
- get: 获取一个资源,比如返回一个虚拟机的详细信息API为”GET /servers/uuid“。
- create: 创建一个新的资源,通常对应为POST请求。比如创建一台虚拟机为 “POST /servers”, 当然POST的数据为虚拟机信息。
- delete: 删除指定资源,通常对应DELETE请求,比如删除一台虚拟机为“DELETE/servers/uuid”。
- update: 更新资源信息,通常对应为PUT请求,比如更新虚拟机资源为”PUT /servers/uuid,body为虚拟机数据。
了解了代码结构,找到了入口,再配合智能跳转,阅读源码势必事半功倍。如果有不明白的地方,随时可以加上断点单步调试。
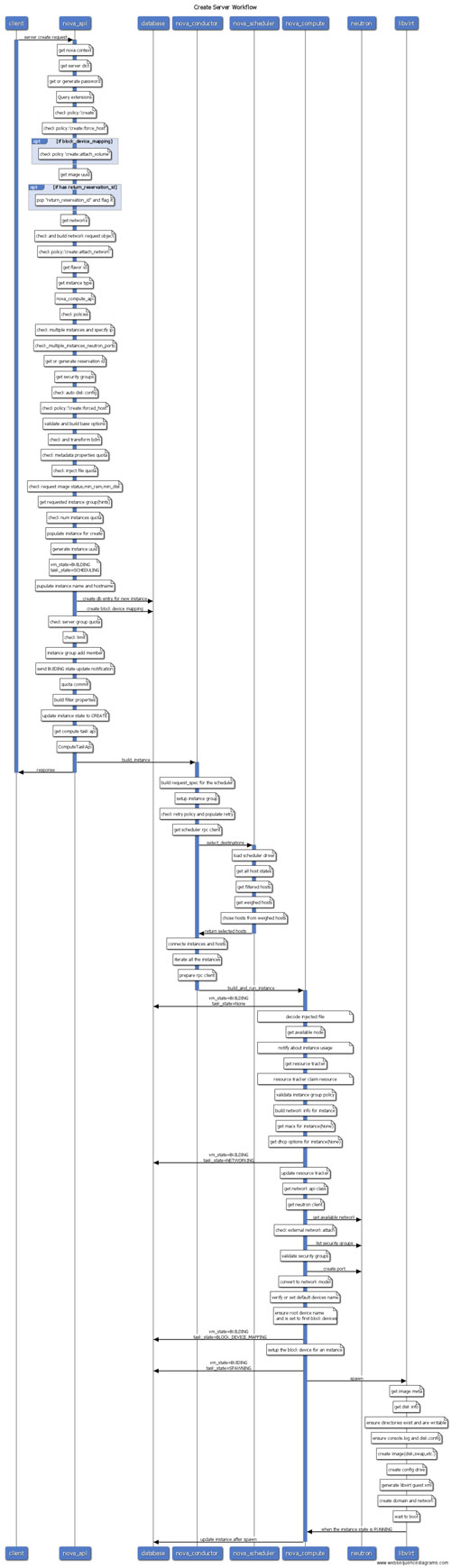
4.案例分析
接下来以创建虚拟机为例,根据组件划分,一步步分析整个工作流程以及操作序列。请再次回顾下api.py、rpcapi.py、manager.py以及api下的controller结构,否则阅读到后面会越来越迷糊。
S1 nova-api
入口为nova/api/openstack/compute/servers.py的create方法,该方法检查了一堆参数以及policy后,调用compute_api的create方法,这里的compute_api即前面说的nova/compute/api.py模块的API。
compute_api会创建数据库记录、检查参数等,然后调用compute_task_api的build_instances方法,compute_task_api即conductor的api.py。
conductor的api并没有执行什么操作,直接调用了conductor_compute_rpcapi的build_instances方法,该方法即时conductor RPC调用api,即nova/conductor/rpcapi.py模块,该方法除了一堆的版本检查,剩下的就是对RPC调用的封装,代码只有两行:
cctxt = self.client.prepare(version=version)
cctxt.cast(context, 'build_instances', **kw)
- 1.
- 2.
其中cast表示异步调用,build_instances是远程调用的方法,kw是传递的参数。参数是字典类型,没有复杂对象结构,因此不需要特别的序列化操作。
截至到现在,虽然目录由api->compute->conductor,但仍在nova-api进程中运行,直到cast方法执行,该方法由于是异步调用,因此nova-api不会等待远程方法调用结果,直接返回结束。
S2 nova-conductor
由于是向nova-conductor发起的RPC调用,而前面说了接收端肯定是manager.py,因此进程跳到nova-conductor服务,入口为nova/conductor/manager.py的build_instances方法。
该方法首先调用了_schedule_instances方法,该方法调用了scheduler_client的select_destinations方法,scheduler_client和compute_api以及compute_task_api都是一样对服务的client调用(即api.py),不过scheduler没有api.py,而是有个单独的client目录,实现在client目录的__init__.py模块,这里仅仅是调用query.py下SchedulerQueryClient的select_destinations实现,然后又很直接的调用了scheduler_rpcapi的select_destinations方法,终于又到了RPC调用环节。
毫无疑问,RPC封装同样是在scheduler的rpcapi中实现。该方法RPC调用代码如下:
return cctxt.call(ctxt, 'select_destinations', **msg_args)
- 1.
注意这里调用的call方法,即同步调用,此时nova-conductor并不会退出,而是堵塞等待直到nova-scheduler返回。
S3 nova-scheduler
同理找到scheduler的manager.py模块的select_destinations方法,该方法会调用driver对应的方法,这里的driver其实就是调度算法实现,由配置文件决定,通常用的比较多的就是filter_scheduler,对应filter_scheduler.py模块,该模块首先通过host_manager拿到所有的计算节点信息,然后通过filters过滤掉不满足条件的计算节点,剩下的节点通过weigh方法计算权值,***选择权值高的作为候选计算节点返回。nova-scheduler进程结束。
S4 nova-condutor
回到scheduler/manager.py的build_instances方法,nova-conductor等待nova-scheduler返回后,拿到调度的计算节点列表,然后调用了compute_rpcapi的build_and_run_instance方法。看到xxxrpc立即想到对应的代码位置,位于compute/rpcapi模块,该方法向nova-compute发起RPC请求:
cctxt.cast(ctxt, 'build_and_run_instance', ...)
- 1.
可见发起的是异步RPC,因此nova-conductor结束,紧接着终于轮到nova-compute登场了。
S5 nova-compute
到了nova-compute服务,入口为compute/manager.py,找到build_and_run_instance方法,该方法调用了driver的spawn方法,这里的driver就是各种hypervisor的实现,所有实现的driver都在virt目录下,入口为driver.py,比如libvirt driver实现对应为virt/libvirt/driver.py,找到spawn方法,该方法拉取镜像创建根磁盘、生成xml文件、define domain,启动domain等。***虚拟机完成创建。nova-compute服务结束。
一张图总结以上是创建虚拟机的各个服务的交互过程以及调用关系,需要注意的是,所有的数据库操作,比如instance.save()以及update操作,如果配置use_local为false,则会向nova-conductor发起RPC调用,由nova-conductor代理完成数据库更新,而不是由nova-compute直接访问数据库,这里的RPC调用过程在以上的分析中省略了。
整个流程用一张图表示为:
【本文是51CTO专栏作者“付广平”的原创文章,如需转载请通过51CTO获得联系】