













导读:和人脑不同,计算机程序学习执行一项任务后,通常也会很快地忘记它们。而DeepMind这项***研究通过修改学习规则,程序在学习一个新任务时,还能记得起老任务。这样的程序,能够持续地、自适应地学习,无疑这是程序迈向更加智能化的重要一步。
计算机程序学习执行一项任务后,通常也会很快地忘记它们。相比之下,我们的大脑以非常不同的方式工作。我们能够逐步学习,一次获得一个技能,并在学习新任务时运用我们以前的知识。作为起点,DeepMind在最近的PNAS文章里,提出一种方法来克服神经网络中的灾难性遗忘。灵感源自神经科学关于哺乳动物和人类大脑巩固化既往获得的技能和记忆的理论。
神经科学家已经发现,在大脑中有两种固化方法:系统固化和突触固化。系统固化是指将我们大脑的快速学习过程获取的记忆印记到缓慢学习过程。这种印记由有意识的和无意识的回忆所介导的—例如,这可能在梦中发生。第二种机制突触固化,则是指那些在既往学习任务中扮演重要角色的神经元之间的连接,不太可能被重写。我们的算法,就是从这种机制中得到灵感,来解决灾难性忘记的问题。
一个神经网络由多个连接组成,其连接方式与大脑的神经元之间的连接方式相同。某个学习任务完成后,我们计算每个连接对该任务的重要性。当我们学习下一个新的任务时,按照每个连接对旧任务的重要性的比例,保护它们免受修改。因此,可以学习新任务而不重写在先前任务中已经学习的内容,并且不会引起显著的计算成本增加。用数学术语来说,我们可以认为在一个新任务中每个连接所附加的保护比作弹簧,弹簧的强度与其连接的重要性成比例。为此,我们称之为“弹性权重固化”( Elastic Weight Consolidation , EWC)。

为了测试我们的算法,我们让程序依次学习一个Atari游戏。当DeepMind在2014年突破性地教它的机器学习系统如何玩Atari游戏时,系统可以学会击败游戏,并且得分高于人类,但不记得它是如何做到的。单单从得分来学习一个游戏是一项具有挑战性的任务,但是依次学习多个游戏更具挑战性,因为每个游戏需要单独的策略。如下图所示,如果没有EWC,程序会在每个游戏停止后(蓝色)会快速忘记它。这意味着,平均来说,它几乎没有学会任何游戏。 然而,如果我们使用EWC(棕色和红色),程序不会轻易忘记,并可以一个接一个地学会玩好几个游戏。
“以前,我们有一个系统,可以学习玩任何游戏,但它只能学会玩一个游戏,”James Kirkpatrick,DeepMind的研究科学家,并且其新研究论文的主要作者告诉WIRED。 “在这里我们展示一个可以学习玩很多个游戏的系统”。
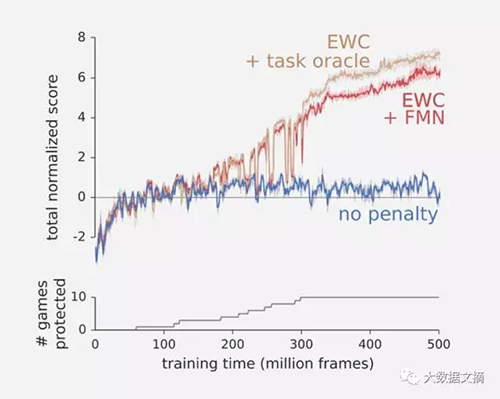
“我们只允许它们在游戏之间的变化非常缓慢,”他说。 “这种方式有学习新任务的空间,但我们应用的更改不会覆盖我们以前学习的算法”。
为了测试算法,DeepMind使用深层神经网络,称为Deep Q-Network (DQN),它以前曾用来征服Atari游戏。然而,这次使用EWC算法来“增强”DQN。它测试了算法和神经网络上随机选择的十个Atari游戏,这是AI已经证明可以像一个人类玩家一样好。每个游戏播放2000万次之前系统自动移动到下一个Atari游戏。
使用EWC算法的深层神经网络能够学习玩一个游戏,然后转移它学到的玩一个全新的游戏。
然而,系统绝不***。 虽然它能够从以前的经验中学习并保留最有用的信息,但是它不能像只完成一个游戏的神经网络那样表现得好。“目前,我们已经展示了顺序学习,但我们还没有证明它是对学习效率的改进,”Kirkpatrick说。 “我们的下一步将尝试和利用顺序学习尝试和改进现实世界的学习”。
连续学习任务而不忘记的能力是生物和人工智能的核心组成部分。今天,计算机程序还不能自适应地、实时地从数据学习。然而,DeepMind已经证明灾难性地遗忘并不是神经网络的不可逾越的挑战。这项研究也推进了我们对固化过程在人类大脑中如何发生的理解。事实上,我们的工作所基于的神经科学理论主要在非常简单的例子中得到证实。通过将这个理论应用在更现实和复杂的机器学习环境中,我们希望进一步加强对突触固化在记忆保留中的作用及其机制的研究。
来源:
https://deepmind.com/blog/enabling-continual-learning-in-neural-networks/, http://www.wired.co.uk/article/deepmind-atari-learning-sequential-memory-ewc
【本文是51CTO专栏机构大数据文摘的原创译文,微信公众号“大数据文摘( id: BigDataDigest)”】

















