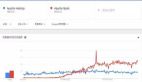
现在如果你想要选择一个解决方案来处理企业中的大数据并不是难事,毕竟有很多数据处理框架可以任君选择,如Apache Samza,Apache Storm 、Apache Spark等等。Apache Spark应该是2016年风头最劲的数据处理框架,它在数据的批处理和实时流处理方面有着得天独厚的优势。
Apache Spark为大数据处理提供一套完整的工具,用户在大数据集上进行操作完全不需考虑底层基础架构,它会帮助用户进行数据采集、查询、处理以及机器学习,甚至还可以构建抽象分布式系统。
Apache Spark以速度而闻名,当然这是MapReduce改进的结果,它没有把数据保存在磁盘上,而是选择将数据保存在内存中。另外,Apache Spark提供了三种语言的库,即Scala,Java和Python。
Spark架构
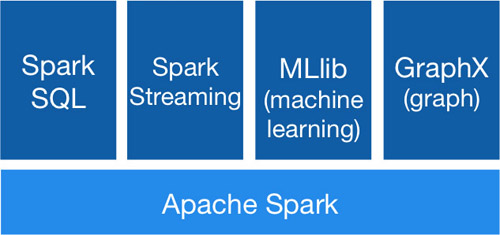
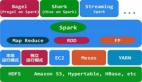
Apache Spark虽然主要用于处理流数据,但是它也包含了很多数据执行操作的组件,上图就展示了它的不同模块。
Spark SQL:Apache Spark附带了SQL接口,这意味着用户可以直接使用SQL查询来与数据进行交互,这些查询统统是由Spark的执行引擎来处理的。
Spark Streaming:此模块提供一组API,用于编写对数据的实时流执行操作的应用程序,它会先将传入的数据流划分为微批次,然后再对数据执行操作。
MLib:MLLib提供了一组API,主要用于对大型数据集运行机器学习算法。
GraphX:支持内置的图操作算法,尤其适用于有很多连接节点的数据集。
除了数据处理库,Apache Spark还附带了一个Web UI。当运行Spark应用程序时,Web UI会默认打开4040端口进行监听,用户可以在其中查看有关任务执行器和统计信息的详细信息,甚至还可以查看任务在执行阶段所花费的时间,从而帮助用户进一步优化性能。
用例
分析:Spark在数据流传入构建实时分析时能够发挥很大作用,它可以有效处理各种来源的大量数据,支持HDFS,Kafka,Flume,Twitter和ZeroMQ,还可以处理自定义数据源。
趋势数据:Apache Spark可用于从传入事件流计算趋势数据。
物联网:物联网系统会生成大量数据然后将其推送到后端进行处理。 Apache Spark能够以固定的间隔(每分钟,小时,周,月等)构建数据管道,还可以基于一组可配置的事件触发操作。
机器学习:因为Spark可以批量处理离线数据并提供机器学习库(MLib),所以用户的数据集上可以轻松应用机器学习算法。 此外,用户可以通过一个大型数据集来实验不同的算法,将MLib与Spark Streaming组合,就可以轻松拥有一个实时机器学习系统。
虽然Apache Spark在很短的时间内就获得了***的人气,但是它也不是***无缺的。
部署棘手
目前Apache Spark支持三种分布式部署方式,分别是standalone、spark on mesos和 spark on YARN。其中,独立部署是最简单直接的方法,而后两种部署方式较为复杂,对于没有经验的新手来说难度很大,在安装依赖的时候可能会遇到一些问题。如果不正确,Spark应用程序将在独立模式下工作,但在集群模式下运行时会遇到类路径异常。
内存问题
因为Apache Spark是为处理大量数据而存在的,所以监控和测量内存使用是至关重要的。Spark中有很多配置是可以根据用例进行调整的,默认配置不一定是***的,所以建议用户要仔细阅读Spark内存配置的文档,根据自己的需求及时作出调整。
版本发布频繁导致API更改
Apache Spark无论是1.x.x版本还是2.x.x版本都一直遵循着三四个月的发布周期,虽说版本的快速迭代代表了Spark的活力和开发人员功能开发的能力,但是它也意味着API的变化。对于,不希望API变化的用户来说,频繁的版本发布反而成了一大难题,甚至为了确保Spark应用程序不受API更改的影响不得不增加额外的开销。
Python支持不成熟
Apache Spark支持Scala,Java和Python,这很对开发人员的胃口,但是这三者的地位并非平起平坐的,尤其是在涉及到新功能时,Java和Scala总是可以***时间更新,而 Python库需要一些时间才能赶上***的API和功能。所以用户在选用***版本的Spark时,应该首先考虑使用Java或Scala实现,如果选用Python则需考虑 feature/API中是否已经支持。
文档贫乏
文档教程和代码演练对于新手快速提升能力非常重要,而Apache Spark的样例虽然会和文档一起分享出来,但是大部分的示例都很基本,有质量的深度样例很少,所以对于想要学习Spark的用户来说参考意义并不是很大。
后记
Apache Spark能够在短时间内击败其它对手走红,不是没有道理的,它的确是一款很好的大数据处理框架,但是如果你的数据没有达到一定的量级,选用Spark无异于杀鸡用牛刀,而简单的解决方案不失为一个更好的选择。