













数据库中的函数封装了一些通用的功能,例如日期类型和字符串类型之间的转换,每个数据库系统都内置了一些函数,当然用户也可以自定义函数。
在Oracle数据库中,函数可总分为单行函数、分组函数「亦称聚合函数」、分析函数三类。
单行函数
单行函数分为五种类型:字符函数、数值函数、日期函数、转换函数、通用函数。比如:
--大小写控制函数
select lower('Hello World') 转小写, upper('Hello World') 转大写 from dual;
--initcap: 首字母大写
select initcap('hello world') 首字符大写 from dual;
--字符控制函数
-- concat: 字符连接函数, 等同于 ||
- select concat('Hello',' World') from dual;
分组函数
分组函数「亦称聚合函数」能在select或select的having子句中使用,当用于select子串时常常都和GROUP BY一起使用。多行函数分为接收多个输入,返回一个输出。比如:
--分组数据:求各个部门的平均工资
- select deptno,avg(sal) from emp group by deptno;
--group by作用于多列: 按部门,不同的工种,统计平均工资
--group by作用于多列:先按照***列分组;如果相同,再按照第二列分组
- select deptno,job,avg(sal) from emp group by deptno,job;
--:求部门的平均工资大于2000的部门
- select deptno,avg(sal) from emp group by deptno having avg(sal)>2000;
分析函数
分析函数是Oracle专门用于解决复杂报表统计需求的功能强大的函数,它可以在数据中进行分组然后计算基于组的某种统计值,并且每一组的每一行都可以返回一个统计值,为我们分析数据提供了一种简单高效的处理方式。
在分析函数出现以前,我们必须使用自联查询,子查询或者内联视图,甚至复杂的存储过程实现的语句,现在只要一条简单的SQL语句就可以实现了,而且在执行效率方面也有相当大的提高。
分析函数和分组函数的不同
普通的分组函数用group by分组,每个分组返回一个统计值,而分析函数采用partition by分组,并且每组每行都可以返回一个统计值。
分析函数的形式
常用的分析函数如下所列:
- row_number() over(partition by ... order by ...)
- rank() over(partition by ... order by ...)
- dense_rank() over(partition by ... order by ...)
- count() over(partition by ... order by ...)
- max() over(partition by ... order by ...)
- min() over(partition by ... order by ...)
- sum() over(partition by ... order by ...)
- avg() over(partition by ... order by ...)
- first_value() over(partition by ... order by ...)
- last_value() over(partition by ... order by ...)
- lag() over(partition by ... order by ...)
- lead() over(partition by ... order by ...)
分析函数常见应用场景
一般可以解决这样的问题:
①查找上一年度各个销售区域排名前10的员工
②按区域查找上一年度订单总额占区域订单总额20%以上的客户
③查找上一年度销售最差的部门所在的区域
④查找上一年度销售***和最差的产品
我们看看上面的几个问题就可以感觉到这几个查询和我们日常遇到的查询有些不同,具体有:
①需要对同样的数据进行不同级别的聚合操作
②需要在表内将多条数据和同一条数据进行多次的比较
③需要在排序完的结果集上进行额外的过滤操作
分析函数初体验
简单介绍几个分析函数的使用样例,让大家能够近距离体验一下Oracle分析函数的强大,Oracle的资料还是比较好找的「相对于DB2来说」,搜索「Oracle分析函数」关键字即可获取更多相关用法,这些样例均在scott用户下成功运行。
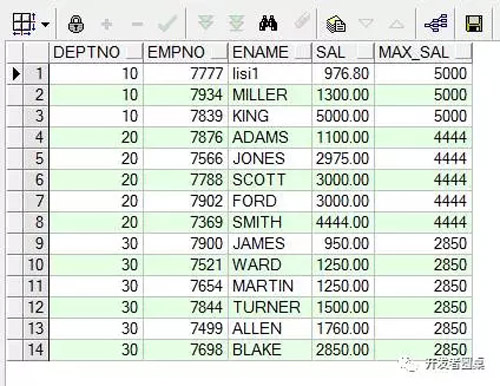
例1,显示各部门员工的工资,并附带显示该部门的***工资
执行SQL
- select e.deptno,
- e.empno,
- e.ename,
- e.sal,
- last_value(e.sal)
- over(partition by e.deptno
- order by e.sal rows
- --unbounded preceding and unbouned following针对当前所有记录的前一条、后一条记录,也就是表中的所有记录
- --unbounded:不受控制的,***的
- --preceding:在...之前
- --following:在...之后
- between unbounded preceding and unbounded following) max_sal
- from emp e;
运行结果
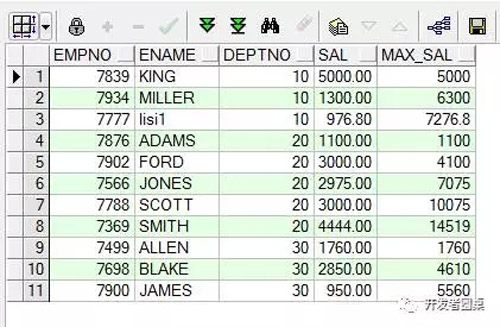
例2,按照deptno分组,然后计算每组值的总和
执行SQL
- select empno,
- ename,
- deptno,
- sal,
- sum(sal) over(partition by deptno order by ename) max_sal
- from emp;
运行结果
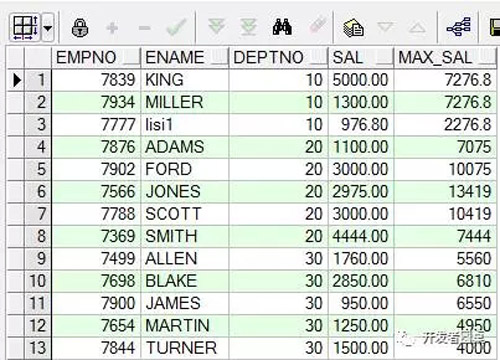
例3,当前行的上一行(rownum-1)到当前行的下辆行(rownum+2)的汇总
执行SQL
- select empno,
- ename,
- deptno,
- sal,
- --注意rows between 1 preceding and 1 following 是指当前行的上一行(rownum-1)到当前行的下辆行(rownum+2)的汇总
- sum(sal) over(partition by deptno
- order by ename
- rows between 1 preceding and 2 following) max_sal
- from emp;
运行结果
例4,***测试
执行SQL
- select
- deptno 部门编号,ename 员工姓名,sal 薪水,
- avg(sal) over(partition by deptno) 该部门薪水均值,
- sum(sal) over(partition by deptno) 该部门薪水总额,
- count(sal) over(partition by deptno) 部门员工数量,
- dense_rank() over(partition by deptno order by sal desc) 该人员的部门薪水排行1,
- row_number() over(partition by deptno order by sal desc) 该人员的部门薪水排行2,
- dense_rank() over(order by sal desc) 该人员的全公司薪水排行,
- min(sal) over(partition by deptno) 该部门的***薪水1 ,
- min(sal) keep(dense_rank first order by sal) over(partition by deptno) 该部门的***薪水2 ,
- first_value(sal) over(partition by deptno order by sal) 该部门的***薪水3,
- max(sal) over(partition by deptno) 该部门的***薪水1,
- max(sal) keep(dense_rank last order by sal) over(partition by deptno) 该部门的***薪水2,
- last_value(sal) over(partition by deptno order by sal) 该部门的***薪水3,
- last_value(sal) over(partition by deptno order by sal rows between unbounded preceding and unbounded following ) 该部门的***薪水4,
- lag(ename, 1, '00') over(order by sal desc) 薪水在自己前一位的人,
- lead(ename, 1, '00') over(order by sal desc) 薪水在自己后一位的人
- from emp e
- order by deptno,sal,ename
运行结果
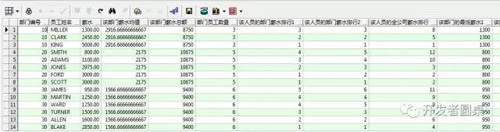
注意:
「该部门的***薪水1\2\3」等结果是一样的,只是使用了不同的写法而已。
last_value()的不同写法导致「该部门的***薪水3」和「该部门的***薪水4」结果是不同的,可以这样去理解:last_value()默认统计范围是 rows between unbounded preceding and current row,因此需要加上rows between unbounded preceding and unbounded following ,才能得到正确的统计结果,「该部门的***薪水4」的统计结果才是正确的。
【本文为51CTO专栏作者“朱国立”的原创稿件,转载请通过作者微信公众号“开发者圆桌”获取联系和授权】










