介绍
Quickstart 将使您运行一个单节点,独立的 HBase 实例。
这一节描述了单节点独立 HBase 的设置。 独立的 实例具有所有的 HBase 守护进程 —— Master,RegionServers,和 ZooKeeper —— 运行于一个单独的JVM 持久化到本地文件系统。它是我们的大多数基本部署配置文件。我们将向你展示如何使用 hbase shell CLI 在 HBase 中创建一个表,向表中插入行,对表执行 put 和 scan 操作,启用或禁用表,以及启动和停止 HBase。
除了下载 HBase,这个过程应该耗费不超过 10 分钟。
在 0.94.x 之前,HBase 期望环回 IP 地址是 127.0.0.1 。Ubuntu 和 其它一些发行版默认为 127.0.1.1 ,而这将导致一些问题。参考 HBase 为什么关心 /etc/hosts ? 一文来了解更多信息。
在 Ubuntu 上,对于 0.94.x 和之前的版本,下面的 /etc/hosts 可以工作。如果遇到了问题,可以使用这个作为模板。
- 127.0.0.1 localhost
- 127.0.0.1 ubuntu.ubuntu-domain ubuntu
这个问题已经在 hbase-0.96.0 及之后的版本中修复了。
JDK 版本要求
HBase 要求安装 JDK。参考 Java 来了解关于支持的 JDK 版本的信息。
HBase 入门
过程:下载,配置,以独立模式启动 HBase
1.在 Apache下载镜像 的列表中选择一个下载站点。点击顶部的建议链接。这将带你到一个 HBase Release 镜像。点击名为 stable 的目录,然后下载以 .tar.gz 结尾的二进制文件到你的本地文件系统。目前先不要下载以 src.tar.gz 结尾的文件。
2.解压缩下载的文件,然后进入新创键的文件夹。
- $ tar xzvf hbase-1.2.4-bin.tar.gz
- $ cd hbase-1.2.4
3.你需要在启动 HBase 之前设置 JAVA_HOME 环境变量。你可以通过你的操作系统的常用机制设置环境变量,但是 HBase 提供了一个中心机制, conf/hbase-env.sh 。编辑这个文件,取消注释以 JAVA_HOME 开头的行,并将它设置为你的操作系统的适当位置。 JAVA_HOME 环境变量应该被设置为包含可执行文件 bin/java 的文件夹。大多数现代 Linux 操作系统提供了某种机制,比如 RHEL 或 CentOS 上的 /usr/bin/alternatives ,来透明地在 Java 这样的可执行文件的不同版本间进行切换。在这种情况下,你可以将 JAVA_HOME 设置为包含到 bin/java 的符号链接的目录,通常是 /usr 。
- JAVA_HOME=/usr
编辑 conf/hbase-site.xml ,它是主 HBase 配置文件。此时,你只需要指定本地文件系统中 HBase 和 ZooKeeper 写数据的文件夹。默认情况下,将在 /tmp 下创建一个新的文件夹。许多服务器被配置为在重启之后删除 tmp 下的内容,因而你应该将数据存储在其它地方。下面的配置将把 HBase 的数据存储在 hbase 目录下,在名为 testuser 的用户的主目录下。粘贴 <configuration> 标签下的 <property> 标签,在新的 HBase 安装中它应该是空的。
示例1. 独立 HBase 的 hbase-site.xml 示例
- <configuration>
- <property>
- <name>hbase.rootdir</name>
- <value>file:///home/testuser/hbase</value>
- </property>
- <property>
- <name>hbase.zookeeper.property.dataDir</name>
- <value>/home/testuser/zookeeper</value>
- </property>
- </configuration>
你无需创建 HBase 数据文件夹。HBase 将为你做这些。如果你创建了目录,HBase 将尝试执行迁移,这不是你想要的。
上面例子中的 hbase.rootdir 指向 本地文件系统 中的目录。’file:/‘ 前缀是我们如何表示本地文件系统的方式。要将 HBase 放置于已有 HDFS 实例上,则设置 hbase.rootdir 指向你的实例上的目录:比如, hdfs://namenode.example.org:8020/hbase 。更多关于这一变体的信息,参考下面关于 基于 HDFS 的独立 HBase 的小节。
1.HBase 提供了一种方便的方式,即 bin/start-hbase.sh 脚本来启动HBase。发出命令,如果一切正常,将有一条消息打印到标准输出显示 HBase 启动成功。你可以使用 jps 命令来验证你有一个称为 HMaster 的运行进程。在独立模式 HBase 在这个单独的 JVM 内运行所有的守护进程,比如,HMaster,一个单独的 HRegionServer,和 ZooKeeper 守护进程。进入 http://localhost:16010 来查看 HBase Web UI。
- $ bin/start-hbase.sh
- starting master, logging to /media/data/dev_tools/hbase-1.2.4/bin/../logs/hbase-hanpfei0306-master-ThundeRobot.out
- OpenJDK 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
- OpenJDK 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
- Could not start ZK at requested port of 2181. ZK was started at port: 2182. Aborting as clients (e.g. shell) will not be able to find this ZK quorum.
需要安装 Java 且其处于可用状态。如果你遇到了一个错误,指示 Java 没有安装,但它已经在你的系统中了,则可能位于非标准位置,编辑 conf/hbase-env.sh 文件并修改 JAVA_HOME 设置,使其指向包含了你的系统的 bin/java 的目录。
过程:首次使用 HBase
1.连接 HBase
使用 hbase shell 命令连接运行中的 HBase 实例,它位于你的 HBase 安装的 bin/ 目录下。在本示例中,省略了一些启动 HBase Shell 时打印的用法和版本信息。HBase Shell 提示以一个 > 字符结尾。
- $ bin/hbase shell
- hbase(main):001:0>
2.显示 HBase Shell 帮助文本
键入 help 并按回车,来显示一些 HBase Shell 基本的用法信息,以及一些命令示例。注意所有的表名,行,列必须用单引号字符引起来。
3.创建表
使用 create 命令创建一个新表。你必须指定表名和 ColumnFamily 名。
- hbase(main):002:0> create 'test', 'cf'
- 0 row(s) in 1.3540 seconds
- => Hbase::Table - test
列出关于表的信息
使用 list 命令来做到这一点:
- => Hbase::Table - test
- hbase(main):003:0> list
- TABLE
- test
- 1 row(s) in 0.0150 seconds
- => ["test"]
1.向表中放入数据
要向表中放入数据,使用 put 命令。
- hbase(main):004:0> put 'test', 'row1', 'cf:a', 'value1'
- 0 row(s) in 0.0990 seconds
- hbase(main):005:0> put 'test', 'row2', 'cf:b', 'value2'
- 0 row(s) in 0.0080 seconds
- hbase(main):006:0> put 'test', 'row3', 'cf:c', 'value3'
- 0 row(s) in 0.0050 seconds
这里,我们插入了三个值,每次一个。第一次插入在 row1 ,列 cf:a ,值为 value1 。HBase中的列由列族前缀,本示例中是 cf ,后跟一个逗号,及列限定符后缀,本示例中是 a 组成。
1.一次扫描表的所有数据
从 HBase 获取数据的一种方式是扫描。使用 scan 命令扫描表的数据。你可以限定你的扫描,但现在,获取所有数据。
- hbase(main):008:0> scan 'test'
- ROW COLUMN+CELL
- row1 column=cf:a, timestamp=1488785612445, value=value1
- row2 column=cf:b, timestamp=1488785622781, value=value2
- row3 column=cf:c, timestamp=1488785633890, value=value3
- 3 row(s) in 0.0220 seconds
1.获得单行数据
要一次获得单行数据,使用 get 命令。
- hbase(main):009:0> get 'test', 'row1'
- COLUMN CELL
- cf:a timestamp=1488785612445, value=value1
- 1 row(s) in 0.0160 seconds
1.禁用表
如果你想要删除表或修改它的设置,以及一些其它情形,你需要先禁用表,使用 disable 命令。你可以使用 enable 命令重新启用它。
- hbase(main):010:0> disable 'test'
- 0 row(s) in 2.2380 seconds
- hbase(main):011:0> enable 'test'
- 0 row(s) in 1.2260 seconds
如果你测试上面的 enable 命令则再次禁用表:
- hbase(main):012:0> disable 'test'
- 0 row(s) in 2.2200 seconds
1.丢弃表
要丢弃(删除)表,则使用 drop 命令。
- hbase(main):013:0> drop 'test'
- 0 row(s) in 1.2280 seconds
1.退出 HBase Shell
要退出 HBase Shell 并从你的集群断开,使用 quit 命令。HBase 依然在后台运行。
过程:停止 HBase
1.与提供 bin/start-hbase.sh 脚本来方便地启动 所有 HBase 守护进程的方式相同, bin/stop-hbase.sh 脚本用来停止它们。
- $ ./bin/stop-hbase.sh
- stopping hbase................
- $
1.发起了这个命令之后,它可能花费几分钟来执行关闭。使用 jps 来确保 HMaster 和 HRegionServer 进程的关闭。
上文已经向你展示了如何启动和停止一个独立的 HBase 实例。下一节我们给出 hbase 部署的其它模式的快速概述。
伪分布式本地安装
在学习了快速启动独立模式的工作后,你可以重新配置 HBase 以伪分布式模式运行。伪分布式模式意味着 HBase 依然完全运行于单独的主机上,但每个 HBase 守护进程(HMaster,HRegionServer,和 ZooKeeper )运行于分开的进程中:在独立模式下所有的守护进程运行于一个 jvm 进程/实例中。默认情况下,除非像 快速开始 一节所述那样配置了 hbase.rootdir 属性,你的数据依然存储于 /tmp 下面。在本文的稍后部分,我们将把你的数据存储于 HDFS 上,假设你有 HDFS 可用。你可以跳过 HDFS 配置来继续将数据存储在本地文件系统。
Hadoop配置
这个过程假设你已经在你的本地系统和/或远程系统中,配置好了 Hadoop 和 HDFS,它们正在运行且可访问。它还假设你在使用 Hadoop 2.Hadoop 文档中关于 设置单节点集群 的指南是一个很好的起点。
1.如果正在运行的话就停止 HBase
如果你已经学完了 快速开始 且 HBase 依然处于运行状态,则停止它。本过程将创建一个全新的 HBase 存储数据目录,因此你之前创建的任何数据库都会丢失。
2.配置 HBase
编辑 hbase-site.xml 配置。首先,添加下面的属性,它指导 HBase 运行于分布式模式,每个守护进程一个 JVM 实例。
- <property>
- <name>hbase.cluster.distributed</name>
- <value>true</value>
- </property>
接下来,将 hbase.rootdir 从本地文件系统修改为你的 HDFS 实例,使用 hdfs://// URI 语法。在本例中,HDFS 运行于 localhost 的端口 8020。
- <property>
- <name>hbase.rootdir</name>
- <value>hdfs://localhost:8020/hbase</value>
- </property>
你无需在 HDFS 下创建目录。HBase 将为你做这些。如果你创建了目录,HBase 将尝试执行迁移,这不是你想要的。
1.启动 HBase
使用 bin/start-hbase.sh 命令启动 HBase。如果你的系统配置正确,则 jps 命令应该显示 HMaster 和 HRegionServer 进程正在运行。
2.检查 HDFS 中的 HBase 目录
如果一切进展顺利,HBase 已经在 HDFS 中创建了它的目录。在上面的配置中,它被存储在了 HDFS 上的 /hbase/ 。你可以使用 Hadoop 的 bin/ 目录下的 hadoop fs 命令列出这个目录。
- $ ./bin/hadoop fs -ls /hbase
- Found 7 items
- drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/.tmp
- drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/WALs
- drwxr-xr-x - hbase users 0 2014-06-25 18:48 /hbase/corrupt
- drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/data
- -rw-r--r-- 3 hbase users 42 2014-06-25 18:41 /hbase/hbase.id
- -rw-r--r-- 3 hbase users 7 2014-06-25 18:41 /hbase/hbase.version
- drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/oldWALs
3.创建表并用数据填充
你可以使用 HBase Shell 创建表,填充数据,扫描并从中获取值,使用与 shell 练习中相同的过程。
4.启动和停止备份 HBase Master(HMaster)服务器
在生产环境中,在相同的硬件上运行多个 HMaster 实例没有意义,以运行伪分布式集群那样的方式对于生产环境同样没有意义。这个步骤只是为了测试和学习目的而提供。
HMaster 服务器控制 HBase 集群。你可以启动最多 9 个备份 HMaster 服务器,这将有总共 10 个 HMaster,算上主要的那个。要启动一个备份 HMaster,使用 local-master-backup.sh 。对于每个你想要启动的备份master,添加一个参数来表示那个 master 的端口偏移。每个 HMaster 使用三个端口(默认是16010,16020,16030)。端口偏移会加到这些端口上,因此,使用 2 作为偏移量的话,备份 HMaster 将使用 16012,16022, 和16032。下面的命令启动 3 个备份服务器,使用端口 16012/16022/16032,16013/16023/16033,和 16015/16025/16035。
- $ ./bin/local-master-backup.sh 2 3 5
要杀死备份 master,而不杀死整个集群,你需要找到它的进程 ID(PID)。PID 存储在一个名字类似于 /tmp/hbase-USER-X-master.pid 的文件中。文件仅有的内容是 PID。你可以使用 kill -9 命令来杀死那个 PID。下面的命令将杀死端口偏移为 1 的 master,但集群依然在运行:
- $ cat /tmp/hbase-testuser-1-master.pid |xargs kill -9
1.启动和停止额外的 RegionServers
HRegionServer 按照 HMaster 的指示管理在它的 StoreFiles 中的数据。通常,集群中的每个节点运行一个 HRegionServer 。在相同的系统上运行多个 HRegionServers 可能对于在伪分布式模式中的测试比较有用。 local-regionservers.sh 命令允许你运行多个 RegionServers 。它与 local-master-backup.sh
命令的工作方式类似,在那种情况下你提供的每个参数表示一个实例的端口偏移。每个 RegionServer 需要两个端口,默认端口是 16020 和 16030。然而,额外的 RegionServers 的基端口不是默认端口,因为默认端口已经被 HMaster 占用了,自 HBaser 版本 1.0.0 开始,它也是一个 RegionServer。使用端口 16200 和 16300 来代替。你可以在一个服务器上运行 99 个额外的非 HMaster 或 备份 HMaster 的 RegionServers。下面的命令启动四个额外 RegionServers,运行在从16202/16302开始的顺序端口(基本端口16200/16300加2)。
- $ .bin/local-regionservers.sh start 2 3 4 5
要手动地停止一个 RegionServer,使用 local-regionservers.sh 命令并传入 stop 参数和要停止的服务器的偏移。
- $ .bin/local-regionservers.sh stop 3
1.停止 HBase
捏可以使用与 快速开始 中介绍的相同的方法停止 HBase,使用 bin/stop-hbase.sh 命令。
高级 - 完全分布式
事实上,你需要一个完全分布式的配置来完整测试 HBase 并在真实世界的场景中使用它。在一个分布式的配置中,集群包含多个节点,它们中的每个都运行一个或多个 HBase 守护进程。这些包括主和备份 Master 实例,多个 ZooKeeper 节点,和多个 RegionServer 节点。
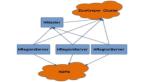
这个高级的 快速开始 为你的集群添加两个额外的节点。架构将像下面这样:
表 1. 分布式集群 Demo 架构
| Node Name | Master | ZooKeeper | RegionServer |
|---|---|---|---|
| node-a.example.com | yes | yes | no |
| node-b.example.com | backup | yes | yes |
| node-c.example.com | no | yes | yes |
这个 快速开始 假设每个节点是一个虚拟机,且它们都在相同的网络上。它基于前面的 快速开始 构建, 伪分布式本地安装 ,假设在那个过程里你配置的系统现在是 node -a 。在继续之前停止 node-a 上的 HBase。
确保所有的节点具有完整的通信权限,且没有防火墙规则可能阻止它们之间相互对话。如果你看到了类似 no route to host 的错误提示,则检查你的防火墙。
过程:配置无密码 SSH 访问
node-a 需要能够登入 node-b 和 node-c (以及其自身) 来启动守护进程。完成这一点最简单的方式是在所有主机上使用相同的用户名,并配置从 node-a 无密码 SSH 登录到其它主机。
在 node-a 上生成一个密钥对
当以运行 HBase 的用户登录时,生成一个 SSH 密钥对,使用如下的命令:
- $ ssh-keygen -t rsa
如果命令成功,则密钥对的位置将打印到标准输出。默认的公钥名字是 id_rsa.pub 。
在其它节点上创建放置共享密钥的目录。
在 node-b 和 node-c 上,以 HBase 用户登录,并在用户的主目录创建一个 .ssh/ 目录,如果它还没有存在的话。如果它已经存在了,请注意它可能已经包含了其它密钥。
1.将公钥拷贝到其它节点。
安全地将公钥从 node-a 拷贝到每个其它节点,通过使用 scp 或其它安全的方式。在其它的每个节点上,创建一个新的名为 .ssh/authorized_keys 的文件,如果它还没有存在的话,并将id_rsa.pub 文件的内容添加到它的末尾。注意你也需要对 node-a 自身做这些。
- $ cat id_rsa.pub >>~/.ssh/authorized_keys
2.测试无密码登录。
如果你正确地执行了过程,如果你从 node-a SSH 到其它的节点,使用相同的用户名,那么你应该不会再看到输入密码的提示符了。
由于 node-b 将运行一个备份 Master,重复上面的过程,将你看到的 node-a 的地方替换为 node-b 。确保不要重写了已有的 .ssh/authorized_keys 文件,使用 >> 操作符将新的密钥附接在已有文件,而不是 > 操作符。
过程:准备 node-a
node-a 将运行你的主 master 和 ZooKeeper 进程,但没有 RegionServers。停止在 node-a 上启动 RegionServer。
1.编辑 conf/regionservers 并移除包含 localhost 的行。添加包含 node-b 和 node-c 的主机名和 IP 地址的行。
即使你不想在 node-a 上运行 RegionServer,你应该通过其它服务器将用以与它通信的主机名引用它。在这个例子中,那将是 node-a.example.com 。这使您能够将配置分发到集群的每个节点,任何主机名冲突。保存文件。
1.配置 HBase 使用 node-b 作为备份 master。
创建一个新的文件 conf/ called backup-masters ,添加新的包含 node-b 的主机名的行。在这个示例中,主机名是 node-b.example.com 。
1.配置 ZooKeeper
事实上,你应该小心地考虑你的 ZooKeeper 配置。你可以在 zookeeper 中找到更多关于配置 ZooKeeper 的东西。这个配置将指导 HBase 在集群的每个节点上启动并管理一个 ZooKeeper 实例。
在 node-a 上,编辑 conf/hbase-site.xml 并添加如下的属性。
- <property>
- <name>hbase.zookeeper.quorum</name>
- <value>node-a.example.com,node-b.example.com,node-c.example.com</value>
- </property>
- <property>
- <name>hbase.zookeeper.property.dataDir</name>
- <value>/usr/local/zookeeper</value>
- </property>
1.你的配置中其它用 localhost 引用 node-a 的地方,修改引用指向其它节点将用以引用 node-a 的主机名。在这些例子中,主机名是 node-a.example.com 。
过程:准备 node-b 和 node-c
node-b 将运行一个备份 master 服务器和一个 ZooKeeper 实例。
1.下载并解压缩 HBase。
下载并解压缩 HBase 到 node-b ,就像你在 独立和伪分布式快速开始中做的那样。
1.将配置文件从 node-a 复制到 node-b 和 node-c 。
你的集群的每个节点需要具有相同的配置信息。复制 conf/ 目录的内容到 node-b 和 node-c 上的 conf/ 目录。
过程:启动并测试你的集群
1.确保 HBase 没有在任何节点上运行。
如果你忘了在前面的测试中停止 HBase,你将遇到错误。使用 jps 命令检查 HBase 是否在你的任何节点上运行。查找进程 HMaster,HRegionServer,和 HQuorumPeer。如果它们存在则杀掉它们。
1.启动集群。
在 node-a 上,发出 start-hbase.sh 命令。你的输出将类似下面这样。
- $ bin/start-hbase.sh
- node-c.example.com: starting zookeeper, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-zookeeper-node-c.example.com.out
- node-a.example.com: starting zookeeper, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-zookeeper-node-a.example.com.out
- node-b.example.com: starting zookeeper, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-zookeeper-node-b.example.com.out
- starting master, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-master-node-a.example.com.out
- node-c.example.com: starting regionserver, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-regionserver-node-c.example.com.out
- node-b.example.com: starting regionserver, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-regionserver-node-b.example.com.out
- node-b.example.com: starting master, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-master-nodeb.example.com.out
ZooKeeper 先启动,然后是 master,接着是 RegionServers,最后是备份 masters。
1.验证进程正在运行。
在集群的每个节点上,运行 jps 命令并验证正确的进程正在每个服务器上运行。你也可能看到其它的 Java 进程正在你的服务器上运行,如果它们用于其它目的。
实例 2. node-a jps 输出
- $ jps
- 20355 Jps
- 20071 HQuorumPeer
- 20137 HMaster
实例 3. node-b jps 输出
- $ jps
- 15930 HRegionServer
- 16194 Jps
- 15838 HQuorumPeer
- 16010 HMaster
实例 4. node-a jps 输出
- $ jps
- 13901 Jps
- 13639 HQuorumPeer
- 13737 HRegionServer
ZooKeeper 进程名
HQuorumPeer 进程是由 HBase 控制及启动的 ZooKeeper 实例。如果你以这种方式使用 ZooKeeper,则每个集群节点限制只有一个实例,且只有测试时才合适。如果 ZooKeeper 不在 HBase 下运行,则进程名称为 HQuorumPeer 。更多关于 ZooKeeper 配置的内容,包括在 HBase 下使用一个外部的 ZooKeeper 实例,请参考 zookeeper 。
1.浏览 Web UI。
Web UI 端口改变
Web UI 端口改变
在版本新于 0.98.x 的 HBase 中,HBase Web UI 使用的 HTTP 端口从 Master 采用60010,每个 RegionServer 采用 60030 变为了 Master 采用 16010 且 RegionServer 采用 16030。
如果所有的东西都设置正确,你应该能够连接到 Master 的 UI http://node-a.example.com:16010/ 或从 master 的 http://node-b.example.com:16010/,使用浏览器。如果你能够通过 localhost 连接,但无法通过其它主机名,则检查你的防火墙规则。你可以在它们的 IP 地址的端口上 16030 看到每个 RegionServers 的 web UI,或点击 Master 的 web UI 中它们的链接。
当节点或服务消失时测试发生了什么。
具有三个节点的集群,就像你配置的那样,不是非常有弹性的。当主 Master 或 RegionServer 消失时,你依然可以通过杀掉进程或看 logs,测试发生了什么。