













纵观数据库发展的几十年,从网状数据库、层次数据库到RDBMS数据库,在最近几年的NewSQL的兴起,加上开源的运动,再加上云的特性,可以说是日新月异。在20世纪80年代后,大部分的业务确定了使用RDBMS数据为存储基础。新世纪开始,随着互联网的发展,数据量的增大,慢慢RDBMS数据库撑不住了,就出现了读写分离策略。随着压力增加,Master撑不住了,这时就要分库了,把关联不大的数据分开部署,一些join查询不能用了,需要借助中间层。随着数据量的进一步增加,一个表的记录越来越大,查询就变得很慢,于是又得搞分表,比如按ID取模分成多个表以减少单个表的记录数。经历过这些事的人都知道过程是多么的折腾。在不同的场景下,就出现各自优秀的分布式数据库,比如在文档型存储下的MongoDB,KV类型的Redis,再比如今天讲的列族类型的HBase。
大数据时代数据存储的特点为:基础量大、增长快、计算与存储的实时性要求迫切、支持时效性短、易发散、易产生脏数据,这些HBase自出生起,就满足这些需求。在大数据时代,我们认为HBase是公认的大数据存储。HBase的原型出自Google的BigTable,这个跟大数据的GFS及MapReduce齐名的三篇论文,由此开创了大数据时代。目前在阿里,已经有上万台的HBase集群,在各个场景下有广泛的应用。
为什么要上云,需要了解到HBase本身比较复杂,这涉及到分布式、数据存储、响应延迟,索引等一些分布式、数据库的知识,对于运维好这个复杂系统还是有一定的难度;要有很好的使用姿势,虽然API比较简单,但是各种组合情况下,畅玩好HBase还是需要一定的功力; 上云是趋势,自己去基于ECS建设又不太了解云环境下,怎么正确部署HBase,怎么跟OSS等云上组件配合。
为此,我们提供云HBase加上专家服务 解决以上3个问题
最后,HBase在阿里集团使用了6年之久,已经在HBase的性能、运维等积累了大量的经验,我们希望把这些回馈给客户,例如:我们仅仅单条低字节高频写入情况就比社区版本高出30%+的性能。
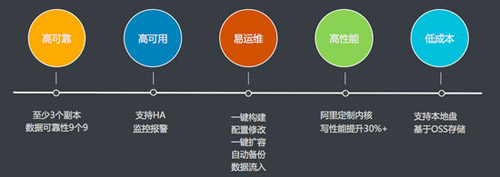
目前提供的价值点有,以下几点:
- 高可靠: 数据备份,数据可靠性9个9
- 高可用:Master节点强制HA机制,出现问题后直接切换
- 易运维:一键构建、配置修改、一键扩容、自动备份、数据流入
- 高性能:比如开源性能大幅度提升30%+
- 低成本:后续本地盘、云盘、OSS分级别存储
技术架构
从技术架构层面看,大致如下:
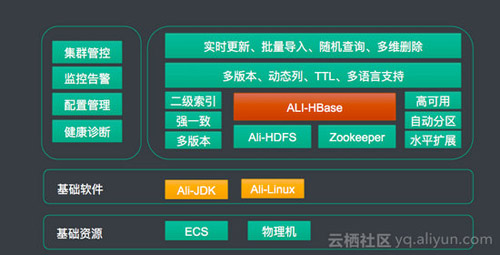
基础资源层:我们底层使用了ECS及本地磁盘的架构,保证在低成本的同时又具备高性能
基础软件层,我们使用了ALi-JDK及ALi-Liunx,这两个都有专门的团队在维护,对云HBase的贡献,比如:改进gc算法减少毛刺,改进linux中断提升性能。
HBase内核层,目前使用是跟阿里集团内部一致的版本,也就是说内部所有的性能优化、功能增强在公有云的客户都可以享受到。这些包括但不限于:提升读写性能、增强稳定性、降低磁盘、网络抖动引起的毛刺等等。 -另外就是运维平台,逐步完善,后续会包括 监控报警、配置管理、健康诊断等等 易于运维的功能。
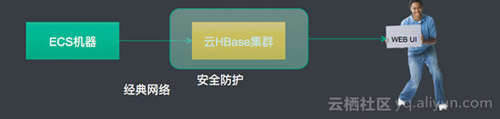
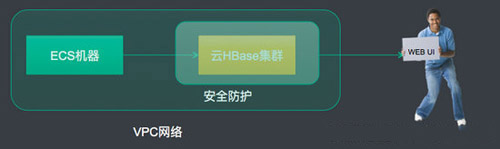
目前支持两种访问网络类型,第一种是经典网络、第二种是VPC网络。区别就是VPC再加了一层网络隔离。
经典网络:
VPC网络:
使用场景
HBase作为默认的大数据时代的存储,基本解决以下三大类的场景:
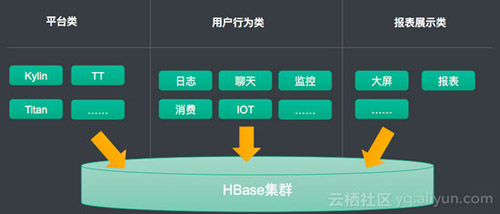
平台类,基本存放是平台的产品,就是其它软件的存储,比如 目前很就行的kylin,阿里内部的日志同步工具TT,图组件Titan等。此类存放的往往平台的数据,有时候往往是无业务含义的。作为平台的底层存储使用。
用户行为类,此类主要是面向各个业务系统。这里的用户不仅仅指的人,也包括物,比如物联网。在阿里主要还是人产生的数据,比如:淘宝收藏夹、交易数据、旺旺聊天记录等等。这里使用比较直接,就直接存放HBase,再读取。难度就是需要支持千万级别的并发写访问及读取,需要解决服务质量的问题,比如GC了,就出现大量的毛刺。
报表类的需求,比如报表、大屏等,最出名的就是阿里巴巴的天猫双十一大屏。
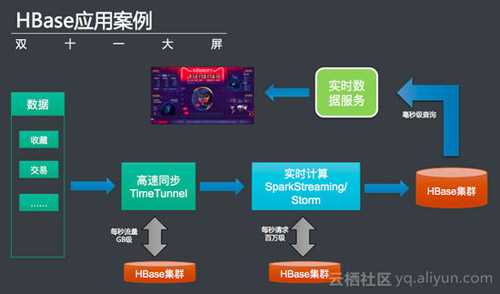
基本上:Mysql支持小数据量,查询较为复杂的数据应用;HBase支持大数据,查询较为简单的数据应用。
后续计划
一些功能,比如同步等,产品化,直接从rds及离线系统导入数据到云HBase系统中
完善云HBase功能,不断做精细化
提供HBase on OSS的能力,降低数据存储的成本
提供双集群多写多度的能力,做多区多地域容灾













