运维需要思维的突破,从Ops走向DevOps,从项目走向产品,从资源走向应用。
很多问题一直在困扰、在思考,为什么CMDB大部分项目都是失败的?为什么讨论的更多的是运维自动化而不是IT自动化?为什么线上问题永远是运维人的黑锅?带着这些问题我们来一探究竟。
今天要和大家阐述一个新的思路——建立面向应用的运维管理新思维,带着这个思路去寻找运维新的解决方案,因此把面向应用管理抽象总结如下:

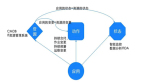
在ITIL时代,大家都知道一个概念,CMDB是IT服务系统的元数据中心,而现在应用更应该是CMDB的元数据。把运维的能力建立在面向应用的维度上,把面向应用的IT能力分成三部分:
1. CMDB即IT资源管理系统
支撑一个应用运行到底占用了哪些资源?应用占用的服务器是一种资源、占用的内存是一种资源、占用的存储是一种资源、占用的负载均衡是一种资源。但大家一定要注意,这个资源不是更多是一种后端服务出现,比如说IaaS服务或者是PaaS服务。
2. 动作
应用的变更有很多种场景,按照角色来归类,比如说应用交付、应用升级等场景,这些场景是面向Dev/Test/Ops的。还有一种应用在日常维护过程中的变更,面向纯Ops场景的,比如说应用的迁移、应用的扩容。动作是作用于资源的,比如说应用升级是版本发生变化,应用扩容是让应用的资源新增等等。过去的传统式运维,总是聚焦碎片式的运维自动化能力理解上。
3. 状态
为了实现对应用的健康状况或者质量的度量,我们需要采集各类状态数据,从而支撑各类场景的应用,比如说监控故障发现的需求,故障恢复的需要,应用服务优化的需要等等。
CMDB建设的不成功,部分是系统的原因,但更多是方法论的问题。我们总以为找到了很强的驱动力来建设资源维护的流程和场景,其实这些都是自己的设想。数据中心的基础设施部门统揽CMDB的一切配置建设和管理,资源部门,根本不关心且没法关心资源所关联的上层应用是什么。

因此我主张把CMDB建设分层建设,业务层和资源层CMDB可以分开建设,但一定以应用的CMDB建设为主,倒推资源层的CMDB建设完善。以应用为中心的IT资源生命周期管理建立起来之后,资源的广度不断拓宽自动化的深度。
但一定要注意CMDB的信息分成两类,一类是实例信息,一类是连接信息,也称为拓扑信息。拓扑信息需要结合我们平时的工作思路来建设和维护,比如说架构视图,是研发转维的过程中,必须要提供的输入,就是应用架构文档。部署视图,是指这个应用上线部署在哪些机房,哪些node。基础架构拓扑是物理overlay,这个地方表达的是基础设施层面的关系。业务流视图分成应用服务和端到端服务构建的能力视图,类似访问流拓扑。

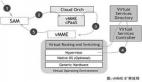
从应用的角度,资源的信息都能够很好的维护起来。此时就考虑如何支撑应用的动作了。这个场景起来之后,真正能解决CMDB数据维护动力和价值问题。面向应用的视角,提供完整的应用自动化和运维自动化能力。应用自动化打通Dev/Test/Staging/Prod等环境,构建面向用户的端到端自动化能力。典型的场景就是交付流水线,示意图如下:

可以把一个端到端的交付流水线,分成了四个标准化过程,纵向就分解了阶段、环境、动作和角色等概念。
1. 阶段
是对交付阶段的逻辑划分,对于一个企业的某个产品来说,建设的标准是单一交付流水线,而不是多交付流水线,单一交付流水线才能保证整个交付过程的一致性。一般分成研发、测试、预发布和生产运维阶段。
2. 环境
环境是以上四个阶段的进一步细分,在每一个阶段会存在多环境的问题,比如说测试阶段,有UAT环境、SIT环境;在生产阶段,有正式生产集群、有容灾备份集群等等。
3. 动作
交付的能力是动作来实现的,这个动作是一连串的能力编排。这个动作可以分解成部署动作和附加动作。部署动作是完成一个环境部署的标准化过程,比如说初始化环境、安装程序包等等,附加动作是针对特定环境要完成的一些动作,比如说针对用户接受性测试,可能会运行自动化测试等等。部署动作要确保在各个环境之间的一致性,这是部署脚本的基本能力,避免动作行为异化导致结果不同。
在动作层,还可以面向封装大量的自动化流程、工具能力等,这些能力都是满足一切应用场景的个性化。
4. 角色
谁来执行这些动作,不同的环境可以面向不同的角色,这是权限的控制。通常分成开发、测试和运维角色,但真正到企业内,角色的划分会细致的多;其次这个角色也是随着管理模式变化而变化的,测试人员可能来做生产环境的部署。
这个自动化能力就不是运维自动化,而是IT自动化。IT自动化的平台可以由运维来建设,确保可扩展、插件化的能力。扩展的能力,是能力可以延伸到不同角色的需要,插件化是可以集成不同角色过去的工具能力,从而实现一个面向DevOps的应用交付平台。
再回到运维自动化,在面向应用的自动化场景上,依然可以通过服务编排的模式来实现。但是回到其他运维资源上,就逐渐失去和应用的关联,从管理方便性的角度来说,更是如此了。举个例子,比如说数据库的维护,大家肯定都是喜欢对数据库的实例进行维护和变更,而不是再加一个应用的维度。在面向Iaas和PaaS能力的自动化上,可以面向资源进行动作服务编排,从而实现运维的自动化。
状态其实是面向应用的一种度量手段,度量越贴近应用,越贴近服务,度量的有效性就越强。监控手段是度量的一种,大家很多时候把监控的告警能力、发现问题作为核心手段。但从这个维度出发,告警泛滥成为必然,大家不断的去看提升告警的准确性,做告警收敛和告警关联。我们的做法是告警可视化分层面板,在时间这个维度上,把告警统一展示,面向应用层的告警权重增大,底层的告警权重变小,衡量应用的健康状况。其次在统一的看板上,人的思维会发生变化,底层的告警能力会不断形成决策参考数据,而非当成直接的问题,甚至可以告警一致。这都是因为以应用为中心,数据有了关联所致。
面向应用的运维管理新思维,是切实有效的,给过去的很多未解问题提供了解决方案,这也是我过去不断强调要“建立以应用运维+运维研发为核心的组织体系”的原因。应用的是贴近业务的,因此应用是驱动力***的。
【本文是51CTO专栏作者“王津银”的原创稿件,转载请注明出处】