在各种技术大会的架构分享中里,常常能听到这样一句话:“一切抛开业务的架构设计都是耍流氓。”基础架构建设,看起来正是“与业务无关”的耍流氓。
基础架构不直接实现业务功能,当购物车系统出现故障,没人会关心是Redis集群不稳定,还是配置中心连接数太高。因此这方面的工作,只有技术部门内部才能够意识到有多重要,却在与业务需求的PK中常常败下阵来,沦为房间里的大象,重要而不紧急,直至火烧眉毛不得不为之的那一天。
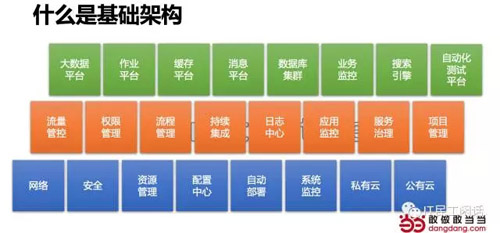
什么是基础架构?
基础架构与业务无关么?
电商系统有什么特点?
需要什么样的基础设施?
我国拉动经济的大招之一就是搞基建,俗称“铁公基”。前几年呢都说云计算是将来互联网的基础设施。
一个上规模的系统,需要更多统一的、专业分工的、可靠的组件、模块、框架和平台来保证整个体系的高效、可控、值得信赖。
电商,尤其是B2C电商,不同于门户、社交、游戏、工具,本质上是以交易为核心的系统,需要7*24小时全天候提供服务,涉及到钱,高度敏感,关联性强,又常常堆积了很多功能(多数只上不下),系统庞杂、边界模糊,积压了许多技术债务,采用多种异构技术,不易维护,缺乏文档,各种历史包袱,摊子越铺越大,完全符合熵增原理,管理成本越来越高,很难调整优化。
基础架构为整个体系服务,也必然受行业特点影响,电商的基础设施一般包含以下部分。
我们为什么要建设基础架构?
有四方面原因:
1.夯实基础,事半功倍
IT技术的价值在于复用,完善的基础架构将会为系统快速演进提供保障,高效响应业务需求。
2.提高系统可控性
系统越复杂,规模越大越难以管理,需要系统化的手段使之成为一套有机的整体。
3.隔离业务代码与框架、平台
人员流动率高、新手比例大,提供框架、平台可以令新手只实现业务代码,充分合理利用人力资源,提高系统稳定性。
4.降低技术债,提高管理效率
建设基础架构通过技术手段减少债务风险,完善的基础架构能够降低沟通成本、节约时间、提高管理效率。
如前所述,基础架构建设很难得到重视,需要怎样实施推进呢?
1.顺势而为,拨乱为治
如果基础架构建设投入不足,会在某些时刻引发问题,甚至严重影响业务,从而被高度关注,又或者某领域技术成为热点,这样的时机要牢牢抓住,顺势而为,实施适合自己的,接近行业主流的方案,该怎么做就怎么做,不必过多纠结。
2.自底向上,由点及面
基础架构建设是有其规律的,一般要自底向上,但层层递进全面实现需要投入大量资源,那么先布点,再以点作为支撑,展开成面更为可行,适当重复建设是可以接受的。
3.抓住痛点,有备无患
既然不能按部就班,就要把好钢用在刀刃上,集中优势兵力,解决关键问题。识别关键问题需要有全局观,并尽可能了解各方面的情况,找到痛点。痛点不一定就是难点,而且多数的问题,都是有解的,如何解决方向非常明确,提前做好调研,等待时机即可。
4.亡羊补牢,犹未晚矣
理想情况是凡事走在前面,理论上投入资源最少、风险***、收益***,但因为各方面原因,总有来不及补的窟窿,爆发问题也很正常,能及时处理就好,避免进一步恶化,也是非常必要的。
接下来,将从三个方面介绍当当基础架构建设的经验。
首先是部署运维方面。
现在很多公司都搞多机房灾备,常见标准是两地三中心,但经常搞着搞着就成了两地三机房,系统跨机房部署,备用不足,机房之间网络通讯问题直接影响系统可用性,多机房反倒成了不稳定因素。试问有多少公司真正进行过灾备切换演练?又有多少人在系统出了问题的时候敢拍着胸脯说切系统没问题?
到底应该怎样?拨乱反正,灾备就灾备,尽量不跨机房调用,技术实力够的话,搞成多活更好。
现在很多创业公司,甚至大公司都在上云,用公有云或者自建私有云。然而公有云就真的可靠么?一旦出现问题,导致业务损失,公有云会赔偿么?要不你再搞跨云部署?这不是给自己找麻烦呢么?本来用公有云是为了省钱省事,你这么牛干脆搞私有云得了,可是私有云真能Hold住么?是否储备了足够的技术人员,能够及时处理各种问题?技术复杂了,什么都软件定义,需要更强的运维。
一句话,尽量简化系统部署架构,多做演练,不要迷信所谓的高新技术,最终这些都是需要有人,人才是最宝贵的资产。
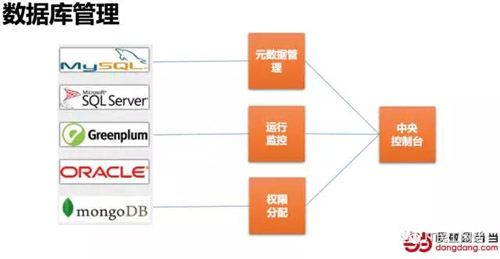
再说说数据库管理,数据库本身就是管理系统,然而一个大型系统,拥有数以百计乃至成千上万的数据库都很正常,而且可能会根据场景采用多种类型的数据库,从MySQL、SQLServer、Oracle到MongoDB、Greenplum不一而足。数据库表结构是否合理?数据同步、备份、数据库运行是否正常,管理分配数据库访问权限需要系统管理。搭建数据库管理平台可以解决这些问题,甚至可以进一步通过系统手段发现问题,比如哪些表空间增长太快需要扩容,比如是否有些同样含义的字段定义类型、长度不一致。
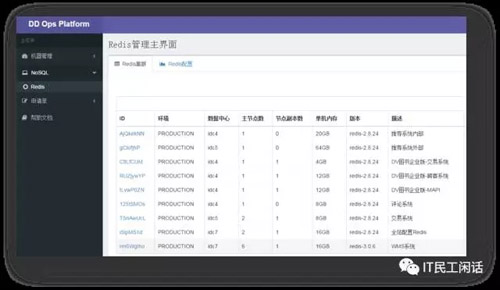
与数据库管理平台同理,Redis缓存集群也需要这样的资源管理平台,而且Redis自身的管理功能有限,又是分布式集群,更需要平台方式管理。因为使用姿势不当等问题,当当前两年在Redis使用上趟过许多坑,为了避免各团队重复掉坑,在2016年初上线了Redis资源管理平台,系统化管理缓存资源、节点,统一版本,令开发人员无需关心底层基础设施,简化运维复杂度,提供统一的系统化运维监控管理。当然,还有一点就是更合理的分配资源,更充分的利用资源。
系统监控的重要性无需赘述,这里说一下选型,当当的系统监控曾经用过Nagios,后来改成了Zabbix,作为主流开源产品,从选型角度来讲可能区别并不大,监控系统最重要的是落地,需要有人支持和推动,切实的应用,真正把每台服务器都监控起来。
其次是基础管理方面。
说起来有些可笑,很多互联网公司在技术部门自身的信息化建设方面投入很少,许多工程师以做业务系统,解决分布式、高并发、大数据量问题为荣,不屑于开发基础管理系统,结果造成了技术团队协作效率低下,管理混乱失序。
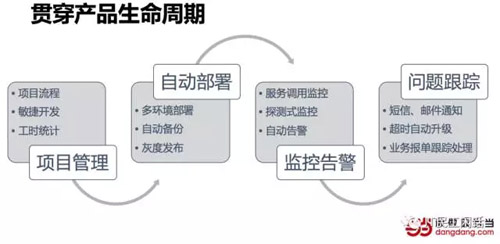
经过几年的建设,当当基本建成了贯穿产品生命周期的基础管理体系,涵盖项目管理、自动部署、监控告警、问题跟踪几部分。
PDLC是项目管理系统,通过系统可以发起需求,跟踪进度,分配任务,查看人力资源使用情况,对当前团队项目执行情况一目了然,心中有数。配合敏捷开发功能,电子看板可以很好的支持每天站会,比物理看板更有技术范儿。
有系统就比没有强,有些公司规模很大,却连项目管理系统都没有,不难想象一定会有很多问题,比如一但发生项目优先级调整,插入新需求,评估影响重新排期就只能靠人了,每到这个时刻项目经理就觉得自己就是个杯具。
系统多了,业务大了,甭管是否微服务,在成千上万台服务器里部署应用实例都是个大动作,偏偏又是天天都要面对的日常,如果都靠年纪轻轻的运维工程师写脚本执行,老板们一定没法淡定的坐在位子上。人虽然是宝贵的,但也是最靠不住的,稳定性比起机器可差多了。所以必须要有自动化部署平台,支持从开发到测试到生产各个环境的编译检查、版本管理、备份、灰度、回滚。
当当的自动化运维部署平台叫PANGU,在2015年获得过总裁认同奖。
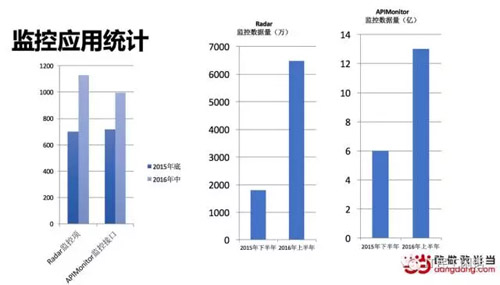
前面说的是系统监控,应用监控、业务监控也同样重要,监控的完善性体现了系统运维管理水平。Radar是探测式监控系统、APIMonitor是服务质量监控。从下图的统计对比可以看到,监控数据量大幅上升,这就是有了工具的好处,想用就用,快速铺开。接下来要解决的是监控更多维度、实现监控系统的自我监控以及基于监控数据提供趋势分析和关联分析,精准告警,甚至防患于未然。
无论是告警还是产品系统问题,都需要有人来追踪解决,Tracker就是这样的问题跟踪系统。通过系统可以避免问题因为转发而迷失在邮件服务器里,能够分级、跟踪问题解决的路径和时效,还能自动超时升级。下图为Tracker系统的报单实时刷新展示。Radar系统中也有类似的实时展示,通过红绿灯方式更直观的显示应用异常。此类系统的难点是问题分类和分级,需要与各部门使用人员进行沟通,并结合系统现状,逐步优化体验,提高效率。
***是技术架构方面。
技术架构方面,当当架构部经历了从组件到框架,再到平台的自底向上,由点及面,逐步推进的过程。
2014年,SOA选型使用Dubbo,考虑当当的系统异构情况,需要支持HTTP调用,二次开发了DubboX,并进行了开源,证明了具备开发基础组件的能力。
2015年,开发应用框架DDFrame,在其中嵌入DubboX和TBSchedule,以及自研的RDB模块,在多个系统中投入应用。后来自研分布式弹性作业调度框架Elastic-Job和轻量级数据库中间件Sharding-JDBC,这两个产品也都进行了开源。
2016年,在Elastic-Job基础上,结合Mesos,开发Elastic-Job-Cloud,这已经是采用容器领域***技术,实现资源自动管理调度的智能作业云平台,投入大规模使用将极大的降低服务器资源浪费,体现云计算的价值。
以上几种组件的开源地址如下,欢迎关注使用,更欢迎参与开发。
https://github.com/dangdangdotcom/dubbox
https://github.com/dangdangdotcom/elastic-job
https://github.com/dangdangdotcom/sharding-jdbc
***简单总结三句话:
1.用自动替代人工
2.用小系统驱动大团队
3.用基础平台支撑上层应用
所以没什么新鲜大道理是大家不知道的,最重要的是做出来,用好,才有价值。
【本文为51CTO专栏作者“史海峰”的原创稿件,转载请通过作者微信公众号“IT民工闲话(ITCrossTalker)”获取联系和授权】