作者 | Karlijn Willems
编译团队 | 饶蓁蓁,Mirra,apple黄卓君
文本挖掘应用领域无比广泛,可以与电影台本、歌词、聊天记录等产生奇妙的化学反应,电影对白、歌词和聊天记录等文本中往往藏着各种有趣的故事。想要开始文本挖掘,但是使用的教程过于复杂 ?找不到一个合适的数据集?这篇文章将会引导你学习8个技巧和诀窍,希望能够激励你开始文本挖掘的进程并且保持兴趣。
1. 对文章产生好奇
在数据科学中,几乎做所有事情的第一步都是产生好奇,文本挖掘也不例外。
文本挖掘应用领域无比广泛,可以与电影台本、歌词、聊天记录等产生奇妙的化学反应:如南方公园的对话,电影对白的文本挖掘和分析等也都是受到了文本挖掘的启发;近期大数据文摘相关文章《从恋爱到婚后的短信词频图发生了这些变化,你中了几枪?》带各位分析了聊天记录中隐藏的文本信息;而对各类歌词的文本信息分析,也颇有意思。(点击查看《这四十年来的香港歌坛在唱些什么》、《分析了42万字的歌词,为了搞清楚民谣歌手们在唱些什么》)
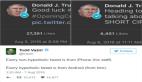
当然,你也可以像StackOverflow的数据科学家David Robinson一样对社交网络上的文本产生兴趣。他在几个星期前他的博客中对于川普的推特数据产生了好奇:“我看到一个假设……仅仅需要对数据进行调查”。

| 每一个非双曲线的推文是从苹果手机(他的工作人员)发送的。每一个双曲线推文是从Android手机(从他本人)手机发送的。pic.twitter.com/gwr6d8h5ed
——Todd Vaziri(@ tvaziri 2016年8月6日) |
也许,如果你对验证假设不是那么感兴趣,那你可能觉得文字图云非常炫酷,并且自己也想尝试创造这种文字图云。
2. 获得你需要的知识和技能
当你产生了好奇,就到了时间来设计你的游戏,并开始展开对文本挖掘知识和技能的学习。你可以轻松地通过完成一些教程和课程来做到这一点。
在这些课程中你应该注意的是:他们给你介绍的数据科学工作流程中至少需要有以下一些步骤,如数据准备或预处理、数据探索、数据分析等。
数据大本营为那些正在准备开始文本挖掘的人准备了一些材料:近日,泰德Kwartler写了一篇关于谷歌趋势和雅虎股票服务的文本挖掘数据教程。这种易于遵循的R教程,可以让你一边实际操作一边学习文本挖掘,这对于文本挖掘的的初学者来说是一个很好的开始。
此外,Ted Kwartler也是数据大本营R课程 “文本挖掘:词袋”的讲师,这门课会向你介绍各种分析方法和数据可视化的内容,让你通过文本挖掘技术对实际生活案例进行操作和研究。
另一方面,你也会有一些不仅限于R的其他材料。如果想学习Python,你可以看看以下这些教程和/或课程:用Python进行文本分析,或者你也可以浏览这个介绍Kaggle的教程。
3. 词,词,词 - 寻找你的数据
一旦你勾勒出了你需要分析和可视化数据数据的基本概念,就是时候去寻找数据了!
请相信我们当我们告诉你,有很多方法可以让你得到你想要的数据。除了提到过的谷歌趋势和雅虎,你也可以从以下方式访问数据:
- 推特! R和Python的提供包或库,将允许你连接到Twitter的API和检索推文。你将在下一节了解更多关于这部分的内容。
- 互联网档案馆,是一个非营利性的图书馆。囊括了数以百万计的免费图书、电影、软件、音乐、网站等。
- Gutenberg计划提供超过55,000本免费电子书。这些电子书大多数都跟文学有关,因此如果你想要分析莎士比亚,简·奥斯汀,爱伦坡的作品,这将是一个很好的来源。
- 对于学术方法类的文本挖掘,你可以使用JSTOR的数据研究。这是一个免费的自助服务工具,让计算机科学家、数字人文主义者和其他研究人员选择和JSTOR的内容进行互动。
- 如果你正在寻找做文本挖掘的系列或电影,就像是上面给出的例子,你可能要考虑下载字幕。一个简单的谷歌搜索绝对可以为你提供你需要的内容,从而形成自己的语料库开始文本挖掘。你也可以从corpora语料库得到你的数据。众所周知的两个语料库的是:路透社语料库和布朗语料库。
- 路透社语料库。有人会说路透社语料库不是最多样化的语料库使用,但是如果你刚开始学做文本挖掘,它还是非常不错的。
- 布朗语料库是按流派分类的文本,包括了500个资源。
正如你所看到的,寻找数据有无穷的可能性。所有包含文本的资源都可以成为你文本挖掘案例研究的课题。
4. 寻找合适的工具来完成工作
现在你已经发现了你的数据来源,你可能要使用合适的工具,让他们成为你的所有物,并对其进行分析。 这些你跟着学习的教程和课程将会教给你使用一些工具作为开始。 但是,这取决于你跟进的课程或教程,你可能会错过一些其他资料。要想完整的学习挖掘技术,下面将介绍一些R中用于文本挖掘的软件包: tm包,毫无疑问,是R在文本挖掘中最常用的包。这个包通常用于更多特定的软件包,例如像Twitter的包,您可以使用从Twitter网站提取的推文和追随者。 用R进行网络爬虫,你应该使用rvest库。有关使用rvest的一个简短的教程,去这里。 如果使用Python,你可以使用这些库: 自然语言工具包,包含在NLTK包中。因为你很容易获得超过50个语料库和词汇资源,这个包是非常有用的。你可以看到这个页面上的这些列表。
如果你想挖掘Twitter数据,你有很多数据包的选择。其中一个使用的比较多的是Tweepy包。对于Web爬虫,scrapy包就会派上用场提取你的网站需要的数据。也可以考虑使用urllib2的,一包打开的URLs。但是,有时requests包会更加推荐,它甚至可能使用起来更方便。有人说,它“更加人性化”,因为一些诸如,设置用户代理,并请求一个页面只有一行的代码的事情,他使用起来更方便。你有时会看到一些人推荐urllib包,但urlib包似乎不是太流行的:大多数开发人员会推荐他们觉得特别有用和使用过的一到两个包。
5. 好的开始是成功的一半 — 预处理你的数据
当我告诉你数据科学家用他们80%的时间来清洗数据,你可能不会惊讶。在这件事上,文本挖掘也不会例外。文本数据可以很杂乱,所以你应该确保你花了足够的时间来清洗它。如果你不确定预处理你的数据意味着什么,那一些标准的预处理步骤包括:抽取文本和结构,这样就可以有你想要处理的文本格式了;去掉停用词,比如“that” 或者“and”;词干提取。这个可以借助于词典或者语言学的规则/算法,比如Porter算法。这些步骤看起来很难,不过预处理你的数据并不需要严格这样做。因为大多数时候,我们前面提到的库和软件包已经可以帮到你很多了。比如说R语言的tm库里的内置函数可以帮你做一些预处理工作,像是词干提取,去掉停用词,删除空格,把单词转换成小写等等。
类似地,Python的nltk包的内置函数也可以帮你做许多预处理工作。不过,你仍然可以将数据预处理再进一步,比如用正则表达式来提取一些你感兴趣的文本模式。这样,你也可以加快数据清洗的过程。对于Python,你可以用re库。对于R,有一堆的函数可以帮到你,比如grep()返回pattern的匹配项的下标, grepl()返回pattern是否匹配的逻辑值, regexpr()和gregexpr()返回的结果包含了匹配的具体位置和字符串长度信息, sub()和gsub()返回替换之后的文本, strsplit()可以拆分字符串。
6. 数据科学家的漫游奇境记 — 探索你的数据
现在,你将迫不及待地开始分析你的数据。不过,在你开始之前,看一看你的数据总是一个不错的主意。借助于上面提到的库或包,可以帮你快速开始探索数据的几点想法:创建一个“文档字词矩阵”:这个矩阵中的元素,代表在语料库的某个文档中某个字词(一个单词或者连续出现的n个单词“n-gram”)出现的频率;建好这个矩阵之后,你就可以用一个直方图来可视化你的语料库中的字词频率。你也许还对语料库中的两个或多个字词的关联感兴趣;可视化你得语料库,你可以做一个文字云(word cloud)。在R中,你可以使用wordcloud库。在Python里也有这个包,一样的名字。
7. 提高你的文本挖掘技能
当你用前面提到的工具对你的数据做了预处理和一些基本的文本分析之后,你可能会想用你的数据集来拓宽你的文本挖掘技术。因为文本挖掘技术真的有很多很多,而你现在只看到了冰山之一角。首先,你应该想着去探索一下文本挖掘和自然语言处理(Natural Language Processing, NLP)之间有什么不同。有了NLP,你会发现命名实体识别(Named Entity Recognition),词性标注与解析(Part-Of-Speech Tagger & Parse),文本情感分析…等等技术。对于Python,你可以用nltk包。
除了这些包,你可以在深度学习和主题模型(比如隐含狄利克雷分布LDA)等方法中找到更多工具。下面列出了一些你可以使用的包:Python包[赵文2] :词嵌入模型(word2vec)可以用gensim包,还有GloVe包。如果想要更深入了解深度学习,你该看看theano包。最后,如果你想用LDA,可以用gensim包。R语言包:词嵌入可以用text2vec。如果你对文本情感分析感兴趣,可以用syuzhet加tm。topicmodels非常适合主题模型。这些包,还远不能囊括所有。因为文本挖掘是个大热门,近年的成果还有许多等待你去发现,而且它还会继续热下去,比如用于多媒体挖掘,多语言文本挖掘等等。
8. 不只是单词 — 可视化你的结果
别忘了传达你的分析结果!
视觉呈现会更吸引人。你的可视化就是你要讲的故事。所以别迟疑,把你分析的结果或者关系可视化出来吧。Python和R都有专门的软件包来帮你做这件事。用这些专门的数据可视化库来呈现你的结果吧:对于Python,你可以用NetworkX来可视化复杂的网络。不过matplotlib在可视化其它数据时也很方便。还有plotly,也很方便,可以在线制作交互式、达到出版质量的图片。对于那些数据可视化的热情粉丝们的一点建议:试着把Python和JavaScript的D3库联系起来,后者可以进行动态的数据操控和可视化,让你观众成为数据可视化过程里的活跃参与者。
对于R语言,除了这些你已经知道的库,比如总是很好用的ggplot2,你还可以用igraph库来分析社交网站上关注、被关注和转发之间的关系。你还想要更多?试着查看一下plotly和networkD3库,来把R和JavaScript或LDAvis库链接到交互式可视化模型中去。 用DataCamp来开始你的文本挖掘之旅吧 !
原文:https://www.datacamp.com/community/blog/text-mining-in-r-and-python-tips#gs.AwiKxRk
【本文是51CTO专栏机构大数据文摘的原创译文,微信公众号“大数据文摘( id: BigDataDigest)”】