近期的工作和Hive SQL打交道比较多,偶尔遇到一些SQL不好解决的问题,会将文件下载下来用pandas来处理,由于数据量比较大,因此有一些相关的经验可以和大家分享
近期的工作和Hive SQL打交道比较多,偶尔遇到一些SQL不好解决的问题,会将文件下载下来用pandas来处理,由于数据量比较大,因此有一些相关的经验可以和大家分享。
大文本数据的读写
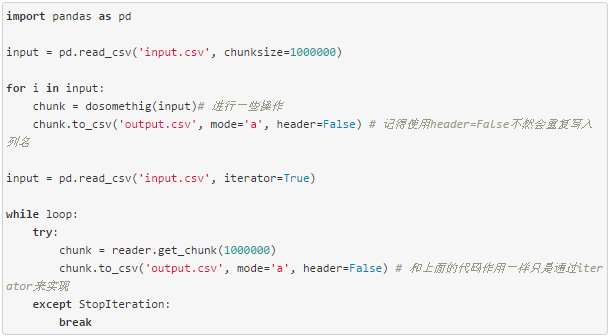
有时候我们会拿到一些很大的文本文件,完整读入内存,读入的过程会很慢,甚至可能无法读入内存,或者可以读入内存,但是没法进行进一步的计算,这个时候如果我们不是要进行很复杂的运算,可以使用read_csv提供的chunksize或者iterator参数,来部分读入文件,处理完之后再通过to_csv的mode='a',将每部分结果逐步写入文件。
to_csv, to_excel的选择
在输出结果时统称会遇到输出格式的选择,平时大家用的最多的.csv, .xls, .xlsx,后两者一个是excel2003,一个是excel2007,我的经验是csv>xls>xlsx,大文件输出csv比输出excel要快的多,xls只支持60000+条记录,xlsx虽然支持记录变多了,但是,如果内容有中文常常会出现诡异的内容丢失。因此,如果数量较小可以选择xls,而数量较大则建议输出到csv,xlsx还是有数量限制,而且大数据量的话,会让你觉得python都死掉了
读入时处理日期列
我之前都是在数据读入后通过to_datetime函数再去处理日期列,如果数据量较大这又是一个浪费时间的过程,其实在读入数据时,可以通过parse_dates参数来直接指定解析为日期的列。它有几种参数,TRUE的时候会将index解析为日期格式,将列名作为list传入则将每一个列都解析为日期格式
关于to_datetime函数再多说几句,我们拿到的时期格式常常出现一些乱七八糟的怪数据,遇到这些数据to_datimetime函数默认会报错,其实,这些数据是可以忽略的,只需要在函数中将errors参数设置为'ignore'就可以了。
另外,to_datetime就像函数名字显示的,返回的是一个时间戳,有时我们只需要日期部分,我们可以在日期列上做这个修改,datetime_col = datetime_col.apply(lambda x: x.date()),用map函数也是一样的datetime_col = datetime_col.map(lambda x: x.date())
把一些数值编码转化为文字
前面提到了map方法,我就又想到了一个小技巧,我们拿到的一些数据往往是通过数字编码的,比如我们有gender这一列,其中0代表男,1代表女。当然我们可以用索引的方式来完成

其实我们有更简单的方法,对要修改的列传入一个dict,就会达到同样的效果。

通过shift函数求用户的相邻两次登录记录的时间差
之前有个项目需要计算用户相邻两次登录记录的时间差,咋看起来其实这个需求很简单,但是数据量大起来的话,就不是一个简单的任务,拆解开来做的话,需要两个步骤,***步将登录数据按照用户分组,再计算每个用户两次登录之间的时间间隔。数据的格式很单纯,如下所示

如果数据量不大的,可以先unique uid,再每次计算一个用户的两次登录间隔,类似这样
这种方法虽然计算逻辑比较清晰易懂,但是缺点也非常明显,计算量巨大,相当与有多少量记录就要计算多少次。
那么为什么说pandas的shift函数适合这个计算呢?来看一下shift函数的作用

刚好把值向下错位了一位,是不是恰好是我们需要的。让我们用shift函数来改造一下上面的代码。

上面的代码就把pandas向量化计算的优势发挥出来了,规避掉了计算过程中最耗费时间的按uid循环。如果我们的uid都是一个只要排序后用shift(1)就可以取到所有前一次登录的时间,不过真实的登录数据中有很多的不用的uid,因此再将uid也shift一下命名为uid0,保留uid和uid0匹配的记录就可以了。