接上篇文章《一名合格的数据分析师分享Python网络爬虫二三事》
五、综合实战案例
1. 爬取静态网页数据
(1)需求
爬取豆瓣网出版社名字并分别存储到excel、txt与MySQL数据库中。
(2)分析
- 查看源码
- Ctrl+F搜索任意出版社名字,如博集天卷
- 确定正则模式
- "<div class="name">(.*?)</div>"
(3)思路
- 下载目标页面
- 正则匹配目标内容
- Python列表存储
- 写入Excel/txt/MySQL
(4)源码
- ''信息存储'''import urllibimport reimport xlsxwriterimport MySQLdb#-----------------(1)存储到excel与txt-------------------------#def gxls_concent(target_url,pat):
- '''
- 功能:爬取数据
- @target_url:爬取目标网址
- @pat:数据过滤模式
- '''
- data = urllib.request.urlopen(target_url).read()
- reret_concent = re.compile(pat).findall(str(data,'utf-8'))
- return ret_concentdef wxls_concent(ret_xls,ret_concent):
- '''
- 功能:将最终结果写入douban.xls中
- @ret_xls:最终结果存储excel表的路径
- @ret_concent:爬取数据结果列表
- '''
- # 打开最终写入的文件
- wb1 = xlsxwriter.Workbook(ret_xls)
- # 创建一个sheet工作对象
- ws = wb1.add_worksheet()
- try:
- for i in range(len(ret_concent)):
- data = ret_concent[i]
- ws.write(i,0,data)
- wb1.close()
- except Exception as er:
- print('写入“'+ret_xls+'”文件时出现错误')
- print(er) def wtxt_concent(ret_txt,ret_concent):
- '''
- 功能:将最终结果写入douban.txt中
- @ret_xls:最终结果存储excel表的路径
- @ret_concent:爬取数据结果列表
- '''
- fh = open(ret_txt,"wb")
- try:
- for i in range(len(ret_concent)):
- data = ret_concent[i]
- datadata = data+"\r\n"
- datadata = data.encode()
- fh.write(data)
- except Exception as er:
- print('写入“'+ret_txt+'”文件时出现错误')
- print(er)
- fh.close()def mainXlsTxt():
- '''
- 功能:将数据存储到excel表中
- '''
- target_url = 'https://read.douban.com/provider/all' # 爬取目标网址
- pat = '<div>(.*?)</div>' # 爬取模式
- ret_xls = "F:/spider_ret/douban.xls" # excel文件路径
- ret_txt = "F:/spider_ret/douban.txt" # txt文件路径
- ret_concent = gxls_concent(target_url,pat) # 获取数据
- wxls_concent(ret_xls,ret_concent) # 写入excel表
- wtxt_concent(ret_txt,ret_concent) # 写入txt文件 #---------------------END(1)--------------------------------##-------------------(2)存储到MySQL---------------------------#def db_con():
- '''
- 功能:连接MySQL数据库
- '''
- con = MySQLdb.connect(
- host='localhost', # port
- user='root', # usr_name
- passwd='xxxx', # passname
- db='urllib_data', # db_name
- charset='utf8',
- local_infile = 1
- )
- return con def exeSQL(sql):
- '''
- 功能:数据库查询函数
- @sql:定义SQL语句
- '''
- print("exeSQL: " + sql)
- #连接数据库
- con = db_con()
- con.query(sql) def gdb_concent(target_url,pat):
- '''
- 功能:转换爬取数据为插入数据库格式:[[value_1],[value_2],...,[value_n]]
- @target_url:爬取目标网址
- @pat:数据过滤模式
- '''
- tmp_concent = gxls_concent(target_url,pat)
- ret_concent = []
- for i in range(len(tmp_concent)):
- ret_concent.append([tmp_concent[i]])
- return ret_concentdef wdb_concent(tbl_name,ret_concent):
- '''
- 功能:将爬取结果写入MySQL数据库中
- @tbl_name:数据表名
- @ret_concent:爬取数据结果列表
- '''
- exeSQL("drop table if exists " + tbl_name)
- exeSQL("create table " + tbl_name + "(pro_name VARCHAR(100));")
- insert_sql = "insert into " + tbl_name + " values(%s);"
- con = db_con()
- cursor = con.cursor()
- try:
- cursor.executemany(insert_sql,ret_concent)
- except Exception as er:
- print('执行MySQL:"' + str(insert_sql) + '"时出错')
- print(er)
- finally:
- cursor.close()
- con.commit()
- con.close()def mainDb():
- '''
- 功能:将数据存储到MySQL数据库中
- '''
- target_url = 'https://read.douban.com/provider/all' # 爬取目标网址
- pat = '<div>(.*?)</div>' # 爬取模式
- tbl_name = "provider" # 数据表名
- # 获取数据
- ret_concent = gdb_concent(target_url,pat)
- # 写入MySQL数据库
- wdb_concent(tbl_name,ret_concent) #---------------------END(2)--------------------------------#if __name__ == '__main__':
- mainXlsTxt()
- mainDb()
(5)结果

2. 爬取基于Ajax技术网页数据
(1)需求
爬取拉勾网广州的数据挖掘岗位信息并存储到本地Excel文件中
(2)分析
a. 岗位数据在哪里?
- 打开拉勾网==》输入关键词“数据挖掘”==》查看源码==》没发现岗位信息
- 打开拉勾网==》输入关键词“数据挖掘”==》按F12==》Network刷新==》按下图操作
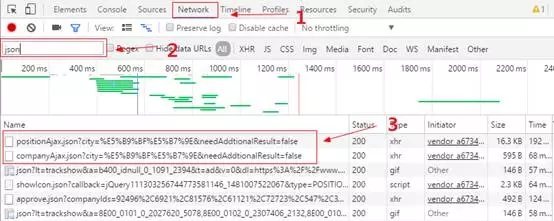
我们可以发现存在position和company开头的json文件,这很可能就是我们所需要的岗位信息,右击选择open link in new tab,可以发现其就是我们所需的内容。

b. 如何实现翻页?
我们在写爬虫的时候需要多页爬取,自动模拟换页操作。首先我们点击下一页,可以看到url没有改变,这也就是Ajax(异步加载)的技术。点击position的json文件,在右侧点击Headers栏,可以发现***部有如下内容:

当我们换页的时候pn则变为2且first变为false,故我们可以通过构造post表单进行爬取。
c. Json数据结构怎么样?

(3)源码
- import urllib.requestimport urllib.parseimport socketfrom multiprocessing.dummy import Poolimport jsonimport timeimport xlsxwriter#----------------------------------------------------------#######(1)获取代理IP###def getProxies():
- '''
- 功能:调用API获取原始代理IP池
- '''
- url = "http://api.xicidaili.com/free2016.txt"
- i_headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0"}
- global proxy_addr
- proxy_addr = []
- try:
- req = urllib.request.Request(url,headers = i_headers)
- proxy = urllib.request.urlopen(req).read()
- proxyproxy = proxy.decode('utf-8')
- proxyproxy_addr = proxy.split('\r\n') #设置分隔符为换行符
- except Exception as er:
- print(er)
- return proxy_addr def testProxy(curr_ip):
- '''
- 功能:利用百度首页,逐个验证代理IP的有效性
- @curr_ip:当前被验证的IP
- '''
- socket.setdefaulttimeout(5) #设置全局超时时间
- tarURL = "https://www.baidu.com/" #测试网址
- proxy_ip = []
- try:
- proxy_support = urllib.request.ProxyHandler({"http":curr_ip})
- opener = urllib.request.build_opener(proxy_support)
- opener.addheaders=[("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0")]
- urllib.request.install_opener(opener)
- res = urllib.request.urlopen(tarURL).read()
- proxy_ip.append(curr_ip)
- print(len(res))
- except Exception as er:
- print("验证代理IP("+curr_ip+")时发生错误:"+er)
- return proxy_ip def mulTestProxies(proxies_ip):
- '''
- 功能:构建多进程验证所有代理IP
- @proxies_ip:代理IP池
- '''
- pool = Pool(processes=4) #开启四个进程
- proxies_addr = pool.map(testProxy,proxies_ip)
- pool.close()
- pool.join() #等待进程池中的worker进程执行完毕
- return proxies_addr#----------------------------------------------------------#######(2)爬取数据###def getInfoDict(url,page,pos_words_one,proxy_addr_one):
- '''
- 功能:获取单页职位数据,返回数据字典
- @url:目标URL
- @page:爬取第几页
- @pos_words_one:搜索关键词(单个)
- @proxy_addr_one:使用的代理IP(单个)
- '''
- global pos_dict
- page = 1
- i_headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0")
- proxy = urllib.request.ProxyHandler({"http":proxy_addr_one})
- opener = urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
- opener.addheaders=[i_headers]
- urllib.request.install_opener(opener)
- if page==1:
- tORf = "true"
- else:
- tORf = "false"
- mydata = urllib.parse.urlencode({"first": tORf,
- "pn": page, #pn变化实现翻页
- "kd": pos_words_one } ).encode("utf-8")
- try:
- req = urllib.request.Request(url,mydata)
- data=urllib.request.urlopen(req).read().decode("utf-8","ignore") #利用代理ip打开
- pos_dict = json.loads(data) #将str转成dict
- except urllib.error.URLError as er:
- if hasattr(er,"code"):
- print("获取职位信息json对象时发生URLError错误,错误代码:")
- print(er.code)
- if hasattr(er,"reason"):
- print("获取职位信息json对象时发生URLError错误,错误原因:")
- print(er.reason)
- return pos_dictdef getInfoList(pos_dict):
- '''
- 功能:将getInfoDict()返回的数据字典转换为数据列表
- @pos_dict:职位信息数据字典
- '''
- pos_list = [] #职位信息列表
- jcontent = pos_dict["content"]["positionResult"]["result"]
- for i in jcontent:
- one_info = [] #一个职位的相关信息
- one_info.append(i["companyFullName"])
- one_info.append(i['companySize'])
- one_info.append(i['positionName'])
- one_info.append(i['education'])
- one_info.append(i['financeStage'])
- one_info.append(i['salary'])
- one_info.append(i['city'])
- one_info.append(i['district'])
- one_info.append(i['positionAdvantage'])
- one_info.append(i['workYear'])
- pos_list.append(one_info)
- return pos_listdef getPosInfo(pos_words,city_words,proxy_addr):
- '''
- 功能:基于函数getInfoDict()与getInfoList(),循环遍历每一页获取最终所有职位信息列表
- @pos_words:职位关键词(多个)
- @city_words:限制城市关键词(多个)
- @proxy_addr:使用的代理IP池(多个)
- '''
- posInfo_result = []
- title = ['公司全名', '公司规模', '职位名称', '教育程度', '融资情况', "薪资水平", "城市", "区域", "优势", "工作经验"]
- posInfo_result.append(title)
- for i in range(0,len(city_words)):
- #i = 0
- key_city = urllib.request.quote(city_words[i])
- #筛选关键词设置:gj=应届毕业生&xl=大专&jd=成长型&hy=移动互联网&px=new&city=广州
- url = "https://www.lagou.com/jobs/positionAjax.json?city="+key_city+"&needAddtionalResult=false"
- for j in range(0,len(pos_words)):
- #j = 0
- page=1
- while page<10: #每个关键词搜索拉钩显示30页,在此只爬取10页
- pos_wordspos_words_one = pos_words[j]
- #k = 1
- proxy_addrproxy_addr_one = proxy_addr[page]
- #page += 1
- time.sleep(3)
- pos_info = getInfoDict(url,page,pos_words_one,proxy_addr_one) #获取单页信息列表
- pos_infoList = getInfoList(pos_info)
- posInfo_result += pos_infoList #累加所有页面信息
- page += 1
- return posInfo_result#----------------------------------------------------------#######(3)存储数据###def wXlsConcent(export_path,posInfo_result):
- '''
- 功能:将最终结果写入本地excel文件中
- @export_path:导出路径
- @posInfo_result:爬取的数据列表
- '''
- # 打开最终写入的文件
- wb1 = xlsxwriter.Workbook(export_path)
- # 创建一个sheet工作对象
- ws = wb1.add_worksheet()
- try:
- for i in range(0,len(posInfo_result)):
- for j in range(0,len(posInfo_result[i])):
- data = posInfo_result[i][j]
- ws.write(i,j,data)
- wb1.close()
- except Exception as er:
- print('写入“'+export_path+'”文件时出现错误:')
- print(er)#----------------------------------------------------------#######(4)定义main()函数###def main():
- '''
- 功能:主函数,调用相关函数,最终输出路径(F:/spider_ret)下的positionInfo.xls文件
- '''
- #---(1)获取代理IP池
- proxies = getProxies() #获取原始代理IP
- proxy_addr = mulTestProxies(proxies) #多线程测试原始代理IP
- #---(2)爬取数据
- search_key = ["数据挖掘"] #设置职位关键词(可以设置多个)
- city_word = ["广州"] #设置搜索地区(可以设置多个)
- posInfo_result = getPosInfo(search_key,city_word,proxy_addr) #爬取职位信息
- #---(3)存储数据
- export_path = "F:/spider_ret/positionInfo.xls" #设置导出路径
- wXlsConcent(export_path,posInfo_result) #写入到excel中 if __name__ == "__main__":
- main()
接下篇文章《一名合格的数据分析师分享Python网络爬虫二三事(Scrapy自动爬虫)》
【本文是51CTO专栏机构“岂安科技”的原创文章,转载请通过微信公众号(bigsec)联系原作者】