一、前言
作为一名合格的数据分析师,其完整的技术知识体系必须贯穿数据获取、数据存储、数据提取、数据分析、数据挖掘、数据可视化等各大部分。
在此作为初出茅庐的数据小白,我将会把自己学习数据科学过程中遇到的一些问题记录下来,以便后续的查阅,同时也希望与各路同学一起交流、一起进步。刚好前段时间学习了Python网络爬虫,在此将网络爬虫做一个总结。
二、何为网络爬虫?
1. 爬虫场景
我们先自己想象一下平时到天猫商城购物(PC端)的步骤,可能就是:
打开浏览器==》搜索天猫商城==》点击链接进入天猫商城==》选择所需商品类目(站内搜索)==》浏览商品(价格、详情参数、评论等)==》点击链接==》进入下一个商品页面......
这样子周而复始。当然这其中的搜索也是爬虫的应用之一。简单讲,网络爬虫是类似又区别于上述场景的一种程序。
2. 爬虫分类
(1)分类与关系
一般最常用的爬虫类型主要有通用爬虫和聚焦爬虫,其中聚焦爬虫又分为浅聚焦与深聚焦,三者关系如下图:

(2)区别
通用爬虫与聚焦爬虫的区别就在有没有对信息进行过滤以尽量保证只抓取与主题相关的网页信息。
(3)聚焦爬虫过滤方法
- 浅聚焦爬虫
选取符合目标主题的种子URL,例如我们定义抓取的信息为招聘信息,我们便可将招聘网站的URL(拉勾网、大街网等)作为种子URL,这样便保证了抓取内容与我们定义的主题的一致性。
- 深聚焦爬虫
一般有两种,一是针对内容二是针对URL。其中针对内容的如页面中绝大部分超链接都是带有锚文本的,我们可以根据锚文本进行筛选。
3. 爬虫原理
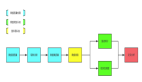
总的来说,爬虫就是从种子URL开始,通过 HTTP 请求获取页面内容,并从页面内容中通过各种技术手段解析出更多的 URL,递归地请求获取页面的程序网络爬虫,总结其主要原理如下图(其中红色为聚焦爬虫相对通用爬虫所需额外进行步骤):

4. 爬虫应用
网络爬虫可以做的事情很多,如以下列出:
- 搜索引擎
- 采集数据(金融、商品、竞品等)
- 广告过滤
- ……
其实就我们个人兴趣,学完爬虫我们可以看看当当网上哪种技术图书卖得比较火(销量、评论等信息)、看某个在线教育网站哪门网络课程做得比较成功、看双十一天猫的活动情况等等,只要我们感兴趣的数据,一般的话都可以爬取得到,不过有些网站比较狡猾,设置各种各样的反扒机制。总而言之,网络爬虫可以帮助我们做很多有趣的事情。
三、网络爬虫基础
个人建议本章除3.3以外,其他内容可以大致先看一下,有些许印象即可,等到后面已经完成一些简单爬虫后或者在写爬虫过程中遇到一些问题再回头来巩固一下,这样子或许更有助于我们进一步网络理解爬虫。
1. HTTP协议
HTTP 协议是爬虫的基础,通过封装 TCP/IP 协议链接,简化了网络请求的流程,使得用户不需要关注三次握手,丢包超时等底层交互。
2. 前端技术
作为新手,个人觉得入门的话懂一点HTML与JavaScript就可以实现基本的爬虫项目,HTML主要协助我们处理静态页面,而实际上很多数据并不是我们简单的右击查看网页源码便可以看到的,而是存在JSON(JavaScript Object Notation)文件中,这时我们便需要采取抓包分析,详见《5.2 爬取基于Ajax技术网页数据》。
3. 正则表达式与XPath
做爬虫必不可少的步骤便是做解析。正则表达式是文本匹配提取的利器,并且被各种语言支持。XPath即为XML路径语言,类似Windows的文件路径,区别就在XPath是应用在网页页面中来定位我们所需内容的精确位置。
四、网络爬虫常见问题
1. 爬虫利器——python
Python 是一种十分便利的脚本语言,广泛被应用在各种爬虫框架。Python提供了如urllib、re、json、pyquery等模块,同时前人又利用Python造了许许多多的轮,如Scrapy框架、PySpider爬虫系统等,所以做爬虫Python是一大利器。
说明:本章开发环境细节如下
- 系统环境:windows 8.1
- 开发语言:Python3.5
- 开发工具:Spyder、Pycharm
- 辅助工具:Chrome浏览器
2. 编码格式
Python3中,只有Unicode编码的为str,其他编码格式如gbk,utf-8,gb2312等都为bytes,在编解码过程中字节bytes通过解码方法decode()解码为字符串str,然后字符串str通过编码方法encode()编码为字节bytes,关系如下图:
编码为字节bytes,关系")
实战——爬取当当网
爬取网页
- In [5]:import urllib.request
- ...:data = urllib.request.urlopen("http://www.dangdang.com/").read()
- #爬取的data中的<title>标签中的内容如下:
- <title>\xb5\xb1\xb5\xb1\xa1\xaa\xcd\xf8\xc9\xcf\xb9\xba\xce\xef\xd6\xd0\xd0\xc4\xa3\xba\xcd\xbc\xca\xe9\xa1\xa2\xc4\xb8\xd3\xa4\xa1\xa2\xc3\xc0\xd7\xb1\xa1\xa2\xbc\xd2\xbe\xd3\xa1\xa2\xca\xfd\xc2\xeb\xa1\xa2\xbc\xd2\xb5\xe7\xa1\xa2\xb7\xfe\xd7\xb0\xa1\xa2\xd0\xac\xb0\xfc\xb5\xc8\xa3\xac\xd5\xfd\xc6\xb7\xb5\xcd\xbc\xdb\xa3\xac\xbb\xf5\xb5\xbd\xb8\xb6\xbf\xee</title>
查看编码格式
- In [5]:import chardet
- ...:chardet.detect(data)
- Out[5]: {'confidence': 0.99, 'encoding': 'GB2312'}
可知爬取到的网页是GB2312编码,这是汉字的国标码,专门用来表示汉字。
解码
- In [5]:decodeData = data.decode("gbk")
- #此时bytes已经解码成str,<title>标签内容解码结果如下:
- <title>当当—网上购物中心:图书、母婴、美妆、家居、数码、家电、服装、鞋包等,正品低价,货到付款</title>
重编码
- dataEncode = decodeData.encode("utf-8","ignore")
- #重编码结果
- <title>\xe5\xbd\x93\xe5\xbd\x93\xe2\x80\x94\xe7\xbd\x91\xe4\xb8\x8a\xe8\xb4\xad\xe7\x89\xa9\xe4\xb8\xad\xe5\xbf\x83\xef\xbc\x9a\xe5\x9b\xbe\xe4\xb9\xa6\xe3\x80\x81\xe6\xaf\x8d\xe5\xa9\xb4\xe3\x80\x81\xe7\xbe\x8e\xe5\xa6\x86\xe3\x80\x81\xe5\xae\xb6\xe5\xb1\x85\xe3\x80\x81\xe6\x95\xb0\xe7\xa0\x81\xe3\x80\x81\xe5\xae\xb6\xe7\x94\xb5\xe3\x80\x81\xe6\x9c\x8d\xe8\xa3\x85\xe3\x80\x81\xe9\x9e\x8b\xe5\x8c\x85\xe7\xad\x89\xef\xbc\x8c\xe6\xad\xa3\xe5\x93\x81\xe4\xbd\x8e\xe4\xbb\xb7\xef\xbc\x8c\xe8\xb4\xa7\xe5\x88\xb0\xe4\xbb\x98\xe6\xac\xbe</title>
3. 超时设置
允许超时
data = urllib.request.urlopen(“http://www.dangdang.com/”,timeout=3).read()
线程推迟(单位为秒)
import timetime.sleep(3)
4. 异常处理
每个程序都不可避免地要进行异常处理,爬虫也不例外,假如不进行异常处理,可能导致爬虫程序直接崩掉。
1. 网络爬虫中处理异常的种类与关系
(1)URLError
通常,URLError在没有网络连接(没有路由到特定服务器),或者服务器不存在的情况下产生。
(2)HTTPError
首先我们要明白服务器上每一个HTTP 应答对象response都包含一个数字“状态码”,该状态码表示HTTP协议所返回的响应的状态,这就是HTTPError。比如当产生“404 Not Found”的时候,便表示“没有找到对应页面”,可能是输错了URL地址,也可能IP被该网站屏蔽了,这时便要使用代理IP进行爬取数据,关于代理IP的设定我们下面会讲到。
(3)两者关系
两者是父类与子类的关系,即HTTPError是URLError的子类,HTTPError有异常状态码与异常原因,URLError没有异常状态码。所以,我们在处理的时候,不能使用URLError直接代替HTTPError。同时,Python中所有异常都是基类Exception的成员,所有异常都从此基类继承,而且都在exceptions模块中定义。如果要代替,必须要判断是否有状态码属性。
2. Python中有一套异常处理机制语法
(1)try-except语句
- try:
- blockexcept Exception as e:
- blockelse:
- block
- try 语句:捕获异常
- except语句:处理不同的异常,Exception是异常的种类,在爬虫中常见如上文所述。
- e:异常的信息,可供后面打印输出
- else: 表示若没有发生异常,当try执行完毕之后,就会执行else
(2)try-except-finally语句
- try:
- block except Exception as e:
- blockfinally:
- block
假如try没有捕获到错误信息,则直接跳过except语句转而执行finally语句,其实无论是否捕获到异常都会执行finally语句,因此一般我们都会将一些释放资源的工作放到该步中,如关闭文件句柄或者关闭数据库连接等。
4. 自动模拟HTTP请求
一般客户端需要通过HTTP请求才能与服务端进行通信,常见的HTTP请求有POST与GET两种。例如我们打开淘宝网页后一旦HTML加载完成,浏览器将会发送GET请求去获取图片等,这样子我们才能看到一个完整的动态页面,假如我们浏览后需要下单那么还需要向服务器传递登录信息。
(1)GET方式
向服务器发索取数据的一种请求,将请求数据融入到URL之中,数据在URL中可以看到。
(2)POST方式
向服务器提交数据的一种请求,将数据放置在HTML HEADER内提交。从安全性讲,POST方式相对于GET方式较为安全,毕竟GET方式是直接将请求数据以明文的形式展现在URL中。
5. cookies处理
cookies是某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)。
6. 浏览器伪装
(1)原理
浏览器伪装是防屏蔽的方法之一,简言之,其原理就是在客户端在向服务端发送的请求中添加报头信息,告诉服务器“我是浏览器”
(2)如何查看客户端信息?
通过Chrome浏览器按F12==》选择Network==》刷新后点击Name下任一个地址,便可以看到请求报文和相应报文信息。以下是在百度上搜索简书的请求报文信息,在爬虫中我们只需添加报头中的User-Agent便可实现浏览器伪装。

7. 代理服务器
(1)原理
代理服务器原理如下图,利用代理服务器可以很好处理IP限制问题。

个人认为IP限制这一点对爬虫的影响是很大的,毕竟我们一般不会花钱去购买正规的代理IP,我们一般都是利用互联网上提供的一些免费代理IP进行爬取,而这些免费IP的质量残次不齐,出错是在所难免的,所以在使用之前我们要对其进行有效性测试。
(2)实战——代理服务器爬取百度首页
- import urllib.requestdef use_proxy(url,proxy_addr,iHeaders,timeoutSec):
- '''
- 功能:伪装成浏览器并使用代理IP防屏蔽
- @url:目标URL
- @proxy_addr:代理IP地址
- @iHeaders:浏览器头信息
- @timeoutSec:超时设置(单位:秒)
- '''
- proxy = urllib.request.ProxyHandler({"http":proxy_addr})
- opener = urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
- urllib.request.install_opener(opener)
- try:
- req = urllib.request.Request(url,headers = iHeaders) #伪装为浏览器并封装request
- data = urllib.request.urlopen(req).read().decode("utf-8","ignore")
- except Exception as er:
- print("爬取时发生错误,具体如下:")
- print(er)
- return data
- url = "http://www.baidu.com"
- proxy_addr = "125.94.0.253:8080"
- iHeaders = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0"}
- timeoutSec = 10
- data = use_proxy(url,proxy_addr,iHeaders,timeoutSec)
- print(len(data))
8. 抓包分析
(1)Ajax(异步加载)的技术
网站中用户需求的数据如联系人列表,可以从独立于实际网页的服务端取得并且可以被动态地写入网页中。简单讲就是打开网页,先展现部分内容,再慢慢加载剩下的内容。显然,这样的网页因为不用一次加载全部内容其加载速度特别快,但对于我们爬虫的话就比较麻烦了,我们总爬不到我们想要的内容,这时候就需要进行抓包分析。
(2)抓包工具
推荐Fiddler与Chrome浏览器
(3)实战
请转《5.2 爬取基于Ajax技术网页数据》。
9. 多线程爬虫
一般我们程序是单线程运行,但多线程可以充分利用资源,优化爬虫效率。实际上Python 中的多线程并行化并不是真正的并行化,但是多线程在一定程度上还是能提高爬虫的执行效率,下面我们就针对单线程和多线程进行时间上的比较。
(1)实战——爬取豆瓣科幻电影网页
- '''多线程'''import urllibfrom multiprocessing.dummy import Poolimport timedef getResponse(url):
- '''获取响应信息'''
- try:
- req = urllib.request.Request(url)
- res = urllib.request.urlopen(req)
- except Exception as er:
- print("爬取时发生错误,具体如下:")
- print(er)
- return resdef getURLs():
- '''获取所需爬取的所有URL'''
- urls = []
- for i in range(0, 101,20):#每翻一页其start值增加20
- keyword = "科幻"
- keyword = urllib.request.quote(keyword)
- newpage = "https://movie.douban.com/tag/"+keyword+"?start="+str(i)+"&type=T"
- urls.append(newpage)
- return urls def singleTime(urls):
- '''单进程计时'''
- timetime1 = time.time()
- for i in urls:
- print(i)
- getResponse(i)
- timetime2 = time.time()
- return str(time2 - time1) def multiTime(urls):
- '''多进程计时'''
- pool = Pool(processes=4) #开启四个进程
- timetime3 = time.time()
- pool.map(getResponse,urls)
- pool.close()
- pool.join() #等待进程池中的worker进程执行完毕
- timetime4 = time.time()
- return str(time4 - time3) if __name__ == '__main__':
- urls = getURLs()
- singleTimesingleTimes = singleTime(urls) #单线程计时
- multiTimemultiTimes = multiTime(urls) #多线程计时
- print('单线程耗时 : ' + singleTimes + ' s')
- print('多线程耗时 : ' + multiTimes + ' s')
(2)结果:
单线程耗时 : 3.850554943084717 s
多线程耗时 : 1.3288819789886475 s
10. 数据存储
- 本地文件(excel、txt)
- 数据库(如MySQL)
备注:具体实战请看5.1
11. 验证码处理
在登录过程中我们常遇到验证码问题,此时我们有必要对其进行处理。
(1)简单验证码识别
利用pytesser识别简单图形验证码,
(2)复杂验证码识别
这相对有难度,可以调用第三方接口(如打码兔)、利用数据挖掘算法如SVM
接下篇文章《一名合格的数据分析师分享Python网络爬虫二三事(综合实战案例)》
【本文是51CTO专栏机构“岂安科技”的原创文章,转载请通过微信公众号(bigsec)联系原作者】