本文长度为2300字,建议阅读3分钟
好奇宝宝想知道人工智能的机器学习究竟是怎么学习的?本文用漫画让你看懂人工智能内部的工作原理。
最近,富士康放出话来,它的工厂夜间已经不需要开灯了——因为一个工人都不需要,干活的全是人工智能机器。
几乎所有大佬都在谈论人工智能。

似乎这个世界再也不需要人类了。

你可能听了一百遍人工智能,不过到底人工智能是个什么鬼,所谓人工智能的机器学习究竟是怎么学习的?它和你之前玩过的小霸王游戏机究竟有什么区别?
今天,我们用漫画
来直接让你看懂
人工智能内部的工作原理
▼
我们所举的例子是机器学习中的有监督学习。
人工智能机器学习分为有监督学习,无监督学习,强化学习和蒙特卡洛树等。这一句你看不懂完全可以忽略,因为不影响下面的解释。
我就是传说中的大boss,人工智能!怕了吧!

其实,人工智能基本等于人工智障!人类一目了然的事情,它得算半天,而且未必能搞定。

首先,我们来说说,人工智能和传统计算机原理之间的关系。
最传统的计算机,就是这玩意——
它的工作原理就是有一个确定的输入,就有一个确定的输出。
对于机器,原理也一样。比如这个

但人类,被输入一个刺激后,其实是往往这样的
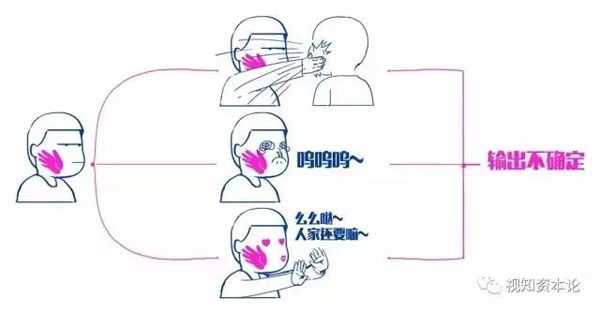
在现实世界中,我们看到女朋友的脸,无论她化了什么样的妆,你一眼就能认出来。
但传统计算机的单一输入值,单一确定输出的模式,就傻眼了。

但怎么让机器模仿出人的输入输出能力,有类似人类的智能。这就是人工智能问题的核心。
其实,要做的就是对复杂的输入信号进行分解计算,对计算中的不同因子进行不同的处理,无论输入的有怎样变化,都能做出大致合理的输出。
用专业的说法,就是在输入输出之间的隐藏层进行一系列权重调整,建立一个模型。
这样无论人脸加上什么伪装,只要落在一个范围内,机器都能认出这张脸。

这时候,机器就变得像人一样能认人了,就成了人工智能。
▼
看到这儿,其实你就比百分九十以上的人更了解人工智能了。但人工智能怎么具体调整权重,我们可以讲个机器人按脸杀人的故事。
***步先要让机器可以认出人脸。

所以我们要拿很多包含人脸的图片喂给它:

脸上不同的部位分别被抽象为一组数字,比如鼻子可以极度简化为为长度和宽度两个数据

然后发送给程序去处理——人工神经网络现在特别流行,我们就用它好了。这些数字的流动,的确有点像人类脑神经的工作方式:
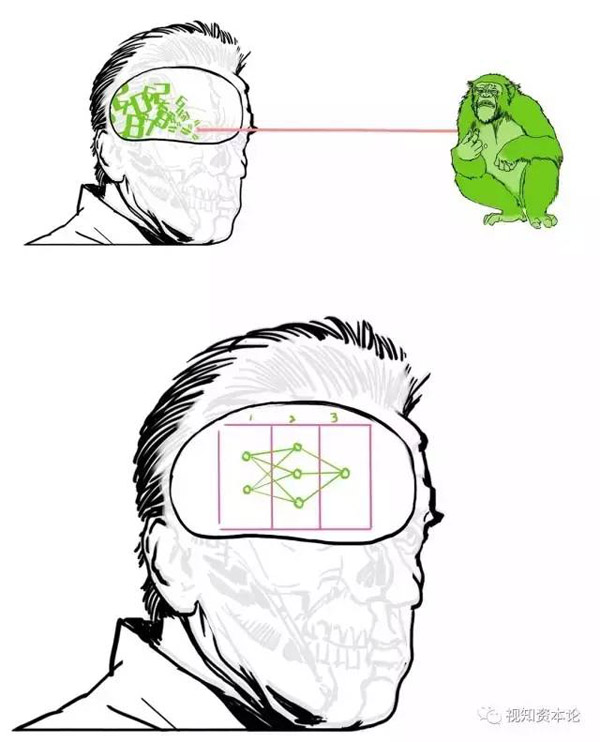
这个图看起来不知所谓,其实特别简单,就是挨个把输入的数字乘以那些系数,***加起来。
对,这些系数就是所谓的“权重”。
输出层输出的就是一个普通的数字。我们给他设定一个阈值,比如20;把牙齿,鼻子和眼睛都算出来,等于28,大于20,就判定输入的是人脸。

这差不多是一种很原始的人工神经网络,叫做感知机。
不过现在的神经网络会引入一种叫做激活函数的东西,把这种一刀切的智障变成一个稍稍聪明一点的样子:
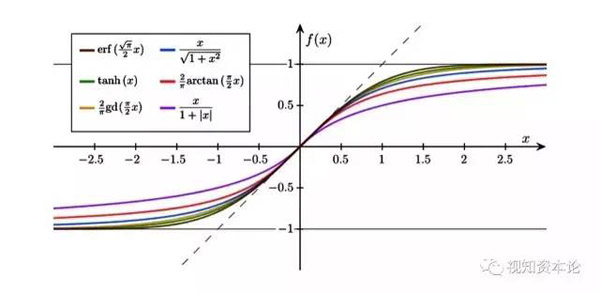
这个图像有什么意义呢?
就是把一个简单到***的“是不是”的问题,转化为有“百分之多少”的概率问题。看上去是不是智能了不少?

同时,聪明的你一定发现了,决定成效的关键其实就是那些“权重”。
怎么获得恰当的权重组合?
这就是机器学习的意义:让机器自己根据每一次考试的结果去修正自己的权重。
慢着,它自己怎么知道对错?

这还是要人类事先给这些照片进行分类:哪些是人,哪些是狗,哪些是ET……
这就好像人类在给他出有标准答案的考试,所以叫做“有监督学习”。

然后我们只要不断重复这个过程,权重就会逐渐调整到更恰当的组合,输出结果就会越来好,判断越来越准。
如此不断重复同一过程,达到改进的方式,就叫做“迭代”。

只要我们的神经网络设计的没问题,最终,就可以准确识别出人类。

现在***进的算法,已经可以达到各种状况下98%以上的正确率了!

这整个过程就叫做“训练”。
我们用来训练它的图片和每张图片对应的标签,就叫做“训练集”。
▼
一般介绍人工智能文章到这里就不会再往深里说了,如果继续往下看,你对人工智能的了解就会远远99.99%的人类。
所以,你做好准备成为砖家了吗?
首先,大家***奇的应该是:程序到底怎么调整权重的?

这个被称作“反向传播”的过程是这样的:在每一次训练中,我们都要确定程序给出的结论错的有多远。
我们已经说过,程序的猜测和答案都可以转化为数值

把所有的错的平方都加起来,再平均一下,就得到一个“损失函数”。
损失函数当然越小越好,这代表我们的神经网络更厉害。
我们一开始可能在山顶,这意味着“损失”特别大,所以我们要尽快下山止损。

怎么做呢?一种最常用的也很有效的办法就是,永远选择最陡的路线,这样很容易就会到达某个山谷。
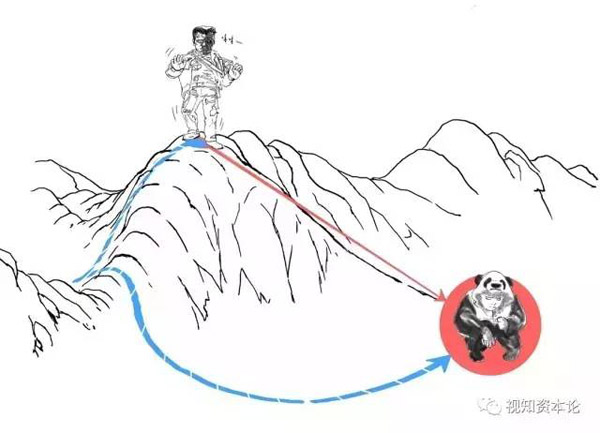
当损失函数达到某个最小值,不怎么变化了,就说明训练差不多了。这种方法就被叫做“梯度下降”。
具体而言,其实就是求导数:

看到这个公式有没有一点想崩溃的感觉?

如果还没有彻底崩溃,就稍微解释一下吧:
这个式子的意思就是,把某个权重减少这么多,损失函数对相应权重的偏导数乘以α。
至于怎么求这个偏导数的数值……你确定你真的想知道?

而这个α呢,也很重要,叫做“学习速率”。
它的意思是:发现错误之后,改变的幅度太大或太小都不好。比如学开车,转弯
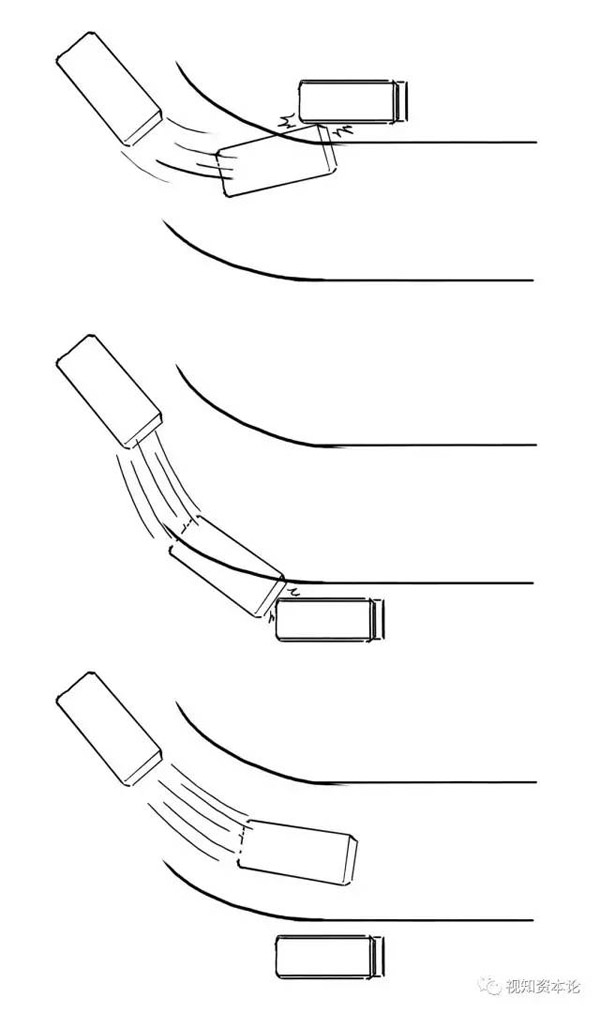
至于改的幅度(系数)多大***,这就要靠悟了。

▼
好吧,说了这么难的东西,再来点八卦吧。
为啥要让人工智能杀那么多猩猩、海豚、蜥蜴?
因为如果没有这些负样本,人工智能随手一抓都是对的。

这样,就不存在学习和积累经验(调整权重)的过程,也不会有在现实世界中真正找到人脸的能力。
不要被那些所谓人工智能专家神神鬼鬼的术语所迷惑,其实人工神经网络的有监督学习的整个过程,无非就是在做自动化的回归分析罢了。
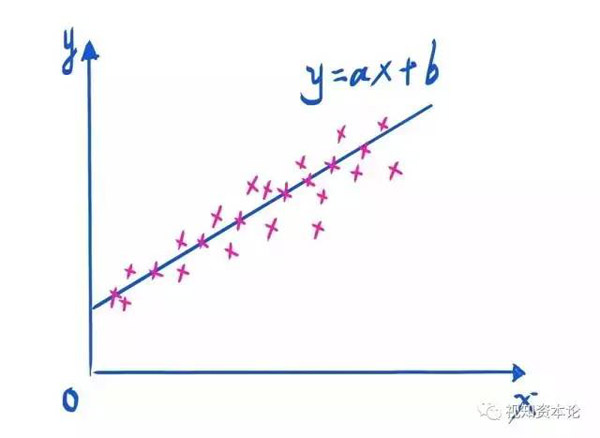
从最简单的一元线性回归到多元非线性回归,就是越来越看起来越来越智能的过程。人工智能的专家也是这么循序渐进掌握机器学习的。
▼
***,如果你能坚持到这里...
恭喜,你已经成为半个机器学习的专家了!
如果大家喜欢,我们下次再来讲讲其他人工智能的技术,比如无监督学习、强化学习!
参考资料:
- 斯坦福大学公开课:《机器学习》
- FaceNet: A Unified Embedding for Face Recognition and Clustering, Florian Schroff,Dmitry Kalenichenko,James Philbin,Google Inc.
- Efficient BackProp, Yann LeCun,Leo Bottou
- 《人工智能时代》,杰瑞·卡普兰
- 《心灵、语言和社会》,约翰·塞尔