在深度学习项目开始前,选择一个合适的框架是非常重要的事情。最近,来自数据科学公司 Silicon Valley Data Science 的数据工程师 Matt Rubashkin(UC Berkeley 博士)为我们带来了深度学习 7 种流行框架的深度横向对比,希望本文能对你带来帮助。
在 SVDS,我们的研发团队一直在研究不同的深度学习技术;从识别图像到语音,我们也在各类框架下实现了不少应用。在这个过程中,我们意识到需要一个简明的方式来获取数据、创建模型、同时评估这些模型的表现。但当我们一次次开始新的深度学习项目时,我们却一直没有找到一个可以参考的标准来告诉自己如何开始。
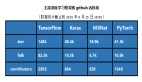
现在,为了回馈开源社区,同时帮助后来者,我们决定以我们的经验对目前流行的几种工具(Theano、TensorFlow、Torch、Caffe、MXNet、Neon 和 CNTK)进行一次横向对比。以下图表展示了各类深度学习工具的优劣,希望对大家能有所帮助。
先放结论
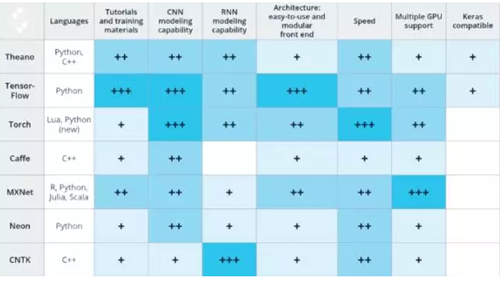
这组对比参考了多种公开基准评测,以及我们在图像/语音识别应用时对这些技术的 主观印象。此外,你需要注意:
语言
当你开始一个深度学习项目时,你***使用一个支持你所会语言的框架。比如 Caffe(C++)和 Torch(Lua)只能支持有限的语言(最近,随着 PyTorch 的出现,情况有所改观)。所以如果你希望选用上述两个框架,我们建议你事先熟悉 C++或 Lua 语言。相比之下,TensorFlow 与 MXNet 具有丰富的多语言支持,即使你对 C++感到陌生也可以使用它们。
教程和资源
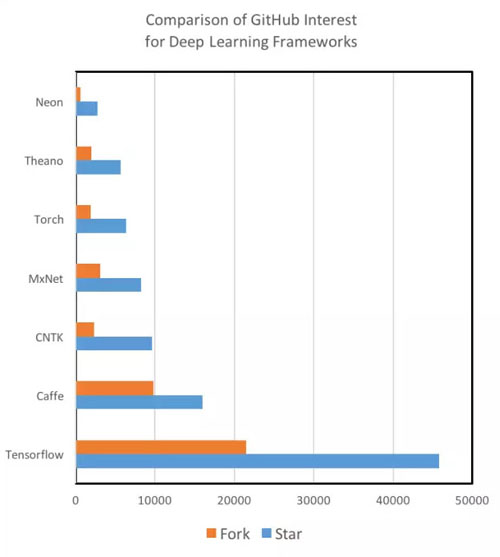
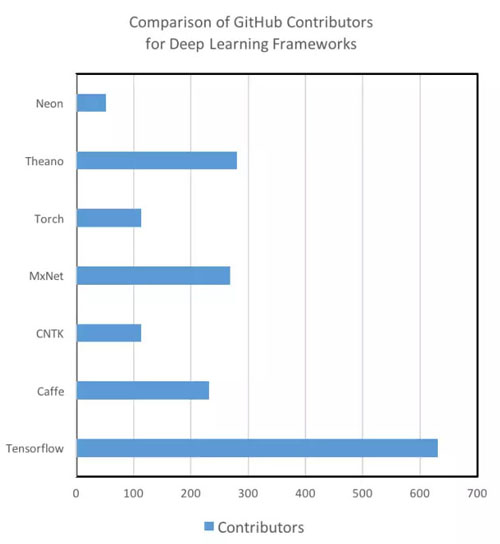
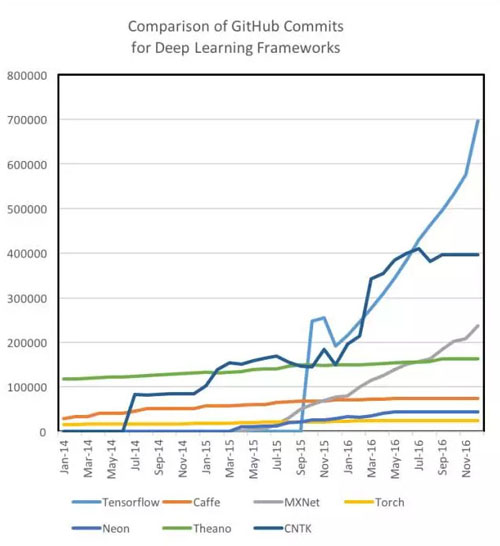
目前,各类深度学习框架的教程与可利用的资源在质量和数量上有着显著的不同。Theano,TensorFlow,Torch 和 MXNet 有着很详尽的文档教程,很容易被初学者理解和实现。与此相比,虽然微软的 CNTK 和英特尔的 Nervana Neon 也是强大的工具,我们却很少能见到有关它们的新手级资料。此外,在研究过程中,我们发现 GitHub 社区的参与度不仅可以用于准确地评价不同工具的开发水平,而且还是在搜索 StackOverflow 或 repo 的 Git Issues 时能否快速解决问题的参考性指标。当然,作为谷歌提供的框架,TensorFlow 理所当然地在教程,资源,开发者和社区贡献者的数量上***。
CNN 建模能力
卷积神经网络(CNN)经常被用于图像识别、推荐引擎和自然语言识别等方向的应用。CNN 由一组多层的神经网络组成,在运行时会将输入的数据进行预定义分类的评分。CNN 也可用于回归分析,例如构成自动驾驶汽车中有关转向角的模型。在横评中,我们评价一种框架的 CNN 建模能力考虑到以下几个特性:定义模型的机会空间、预构建层的可用性、以及可用于连接这些层的工具和功能。我们发现,Theano,Caffe 和 MXNet 都有很好的 CNN 建模能力。其中,TensorFlow 因为易于建立的 Inception V3 模型,Torch 因为其丰富的 CNN 资源——包括易于使用的时间卷积集使得这两种框架在 CNN 建模能力上脱颖而出。
RNN 建模能力
递归神经网络(RNN)常用于语音识别,时间序列预测,图像字幕和其他需要处理顺序信息的任务。由于预建的 RNN 模型不如 CNN 数量多,因此,如果你已经有一个 RNN 深度学习项目,优先考虑旧 RNN 模型是在哪种框架里实现的最重要。目前,Caffe 上的 RNN 资源最少,而 Microsoft 的 CNTK 和 Torch 有丰富的 RNN 教程和预构建模型。当然,***的 TensorFlow 中也有一些 RNN 资源,TFLearn 和 Keras 中更有很多使用 TensorFlow 的 RNN 示例。
架构
为在特定框架中构建和训练新模型,易于使用和模块化的前端是至关重要的。TensorFlow,Torch 和 MXNet 都有直观而模块化的架构,让开发相对变得简单。相比之下,我们在 Caffe 这样的框架上需要进行大量的工作才能创建一个新层。另外我们发现在开发过程中,因为有 TensorBoard web GUI 等应用的存在,TensorFlow 极易在训练中和训练后进行 debug 和监控。
速度
Torch 和 Nervana 具有开源卷积神经网络基准测试的***性能
Tensorflow 的性能在大多数测试中是具有竞争力的,而 Caffe 和 Theano 稍稍落后
微软声称他们的 CNTK 在一些 RNN 训练任务中有最快的速度。
在另一项对比 Theano、Torch 和 TensorFlow 的 RNN 性能的研究中,Theano 是其中最快的。
大多数深度学习应用都需要用到巨量的浮点运算(FLOP)。例如,百度的 DeepSpeech 识别模型需要 10s ExaFLOPs 用于训练,这是大于 10e18 的计算量。
考虑到目前英伟达 Pascal 架构的 TitanX 等***显卡可以每秒执行 11e9 FLOP。
因此,假如需要在大型数据集上训练一个新模型——用单 GPU 机器的话——可能会需要一个星期之久。为了减少构建模型所需的时间,我们需要使用多 GPU 并联的方式组建自己的机器。幸运的是,上述大部分架构都可以很好地支持多 GPU 运算。其中,据报道 MXNet 有着***的多 GPU 优化引擎。
Keras 兼容性
Keras 是一个用于快速构建深度学习原型的高级库。我们在实践中发现,它是数据科学家应用深度学习的好帮手。Keras 目前支持两种后端框架:TensorFlow 与 Theano,而且 Keras 再过不久就会成为 TensorFlow 的默认 API。
尽管如此,Keras 的作者表示,这一高级库在未来仍会作为支持多种框架的前端存在。
总结
如果你想要开始深度学习,你应该从评估自己的团队技能和业务需求开始。例如,如果一个以 Python 为中心的团队想开发图像识别的应用程序,你应该使用 TensorFlow,因为它有丰富的资源,较好性能和完整的原型工具。如果一个有 Lua 能力的团队希望将 RNN 大规模应用到生产环境中去,他们则会受益于 Torch 的高速和强大的 RNN 建模能力。
未来,我们将继续讨论在更大规模的应用中这些框架的表现。这些挑战包括多机并联时的多 GPU 优化,多种开源库的兼容性,如 CMU Sphinx 和 Kaldi 等,尽请期待。