












我们知道,在实时性要求不是很高的应用场景中,比如,月度统计报表生成等,我们基于传统的Hadoop MapReduce来处理海量大数据(包括使用Hive),在各方面表现都还不错,只需要离线处理数据,然后存储结果即可。但是如果在一些实时性要求相对较高的应用场景中,哪怕处理时间能够在原有的基础有大幅度地减少,也能很好地提升用户体验。对于大数据的实时性要求,其实是相对的,比如,传统使用MapReduce计算框架处理PB级别的查询分析请求,可能耗时30分钟甚至更多,但是如果能够使这个延迟大大降低,如3分钟计算出结果,这是很令人震撼的。Impala就是基于这样的需求驱动而出现的。
Impala是Cloudera开发的一款用来进行大数据实时查询分析的开源工具,它能够实现通过我们熟悉的传统关系数据库的SQL风格来操作大数据,数据可以是存储到HDFS或HBase中的。
下面,我们从不同的角度来认识和理解Cloudera Impala:
设计目标
官网给出的介绍是,使用Impala来实现SQL on Hadoop,实现对海量数据的实时查询分析,它的优势有如下几点:
- 快速
可以方便地执行SQL语句,在数秒内返回查询分析结果。
这一点,其实还要依赖于你在HDFS或HBase上存储的数据的规模,依赖于你对Impala系统的配置调优情况,可能还依赖于你写的SQL语句的执行效率。
- 灵活
可以直接查询存储在HDFS上的原生数据,也可以查询经过优化设计而存储的数据,只要数据的格式它们能够兼容MapReduce、Hive、Pig等等。
- 整合&开放
可以非常容易地与Hadoop系统整合,并使用Hadoop生态系统的资源和优势,也不需要将数据迁移到特定的存储系统就能满足查询分析的要求。
- 可伸缩性
可以很好地与一些BI应用系统协同工作,如Microstrategy、Tableau、Qlikview,等等。
支持特性
Impala支持的特性,主要包括如下几点:
- 对 ANSI-92 SQL标准的支持
Impala支持ANSI-92 SQL所有子集,包括CREATE、ALTER、SELECT、INSERT、JOIN、GROUP BY以及子查询。它还支持分区JOIN、常用的聚合函数(SUM、COUNT、MAX、MIN、AVG等等)、topN查询。你使用这些语句时,可以像使用关系数据库中使用的SQL语句一样去设计,很容易上手。
- 数据来源与数据格式
Impala可以操作HDFS、HBase中存储的数据,支持如下HDFS的支持文件格式:Text file、SequenceFile、RCFile、Avro file、Parquet,支持的压缩格式有:Snappy、GZIP、Deflate、BZIP,其中Snappy压缩格式的性能更好一些。
- 支持的数据访问接口
主要包括Hive所支持的如下接口:JDBC Driver、ODBC Driver、Hue Beeswax、Cloudera Impala Query UI.,另外,还可以通过CLI接口(也就是Impala Shell)访问。
架构设计要点
Impala的架构设计视图,如图所示:
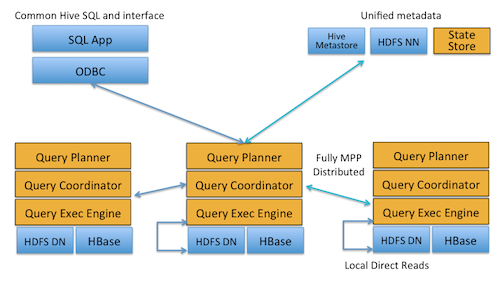
上面可以看出,位于Datanode上的每个impalad进程,都具有Query Planner、Query Coordinator、Query Exec Engine这几个组件,每个Impala节点在功能集合上是对等的,也就是说,任何一个节点都能接收外部查询请求。当有一个节点发生故障后,其他节点仍然能够接管,这还要得益于,在HDFS上,数据的副本是冗余的,只要数据能够取到,某些挂掉的impalad进程所在节点的数据,在整个HDFS中只要还存在副本(impalad进程正常的节点),还是可以提供计算的。除非,当多个impalad进程挂掉了,恰好此时的查询请求要操作的数据所在的节点,都没有存在impalad进程,这是肯定是无法计算了。
Cloudera Impala在实际应用场景中所处的位置,如图所示:
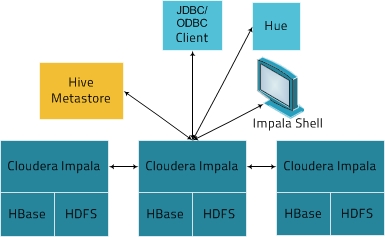
上图展示了Impala方案的相关的各种组件,简单说明如下:
- 客户端
有三类客户端可以与Impala进行交互:基于驱动程序的客户端(ODBC Driver和JDBC Driver,其中JDBC Driver支持Hive1与Hive2风格的驱动形式);Hue接口,可以通过Hue Beeswax接口来与Impala进行交互;Impala Shell命令行接口,类似关系数据库提供一些命令行即可,可以直接使用SQL语句与Impala交互。
- Hive Metastore
Impala使用Hive Metastore来存储一些元数据,为Impala所使用,通过存储的元数据,Impala可以更好地知道整个集群中数据以及节点的状态,从而实现集群并行计算,对外部提供查询分析服务。
- Cloudera Impala
Impala会在HDFS集群的Datanode上启动进程,协调位于集群上的多个Impala进程(impalad),以及执行查询。在Impala架构中,每个Impala节点都可以接收来自客户端的查询请求,然后负责解析查询,生成查询计划,并进行优化,协调查询请求在其他的多个Impala节点上并行执行,最后有负责接收查询请求的Impala节点来汇总结果,响应客户端。
- HBase和HDFS
HBase和HDFS存储着实际需要查询的大数据。
总结
Cloudera官网所言,使用Impala比使用Hive能提高3~90的效率,我们可以参考Cloudera的官网博客。我相信,使用Impala比使用Hive能大大提升计算性能,这是真实的。Impala从发布到现在也不过一年左右时间,它还在发展之中,能有这样的表现我还是感觉很欣慰,至少让我们看到了一些商业系统能够实现的功能已经在开源项目中落地。
在我们使用Impala的过程中,我总结一下遇到的相关问题:
- SQL解析
我发现Impala目前在SQL解析方面还有优化的余地,当前的问题,一个是SQL解析速度很慢,另一个是如果SQL比较复杂的话存在硬解析的问题,非常耗时。虽然和现在更加成熟的关系数据库Oracle、MySQL等还有一定差距,但是我相信这些只是时间问题。
- 稳定性
可能是因为依赖于Hive的原因,通过Thrift接口来与后端进行交互,并发性比较差。当并发稍微高一点点的时候,就会出现impalad进程挂掉的问题,有时候可能还会出现类似的僵尸进程。


















