身处人工智能的风口,ISSCC也不能幸免地将本次大会主题定为「Intelligent chips for a smarter world」。


同时,大会还在研究论文报告中设立了专门讨论深度学习处理芯片的论文session,在SPR海报session中,也有两篇来自复旦大学(与华盛顿大学合作)和清华大学的研究,分别针对RNN和CNN的处理器芯片设计。除此之外,大会也安排了探讨神经网络相关课题的tutorialsession(面向初学者)和forum session(面向专业人士)。
本次ISSCC中关于深度学习的论文集中出现在session 14。
作为有深度的专业人工智能公众号,矽说将从各个技术报告中进行深度归纳、刨析在这些论文引导下的AI芯片发展趋势。
趋势一:更高效的大卷积解构/复用
在《脑芯编(四)》中,我们曾提到,在标准SIMD的基础上,CNN由于其特殊的复用机制,可以进一步减少总线上的数据通信。而复用的这一概念,在超大型神经网络中的显得格外重要。对于AlexNet/VGG这些模型中的中后级卷积核,卷积核的参数量可以达3x3x512之巨大,合理地分解这些超大卷积到有效的硬件上成为了一个值得研究的问题。
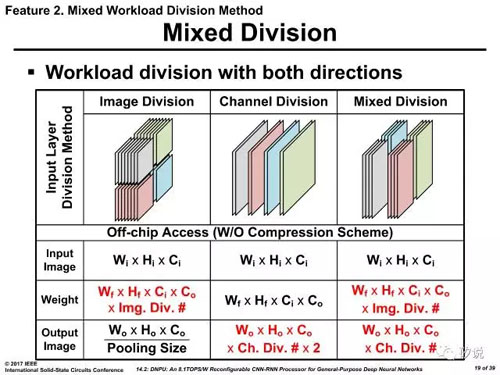
在14.2 中,韩国KAIST学院分析了集中不同的分解方法,包括输入图像/卷积核分解,及其混合模式,得到了最终的方案。
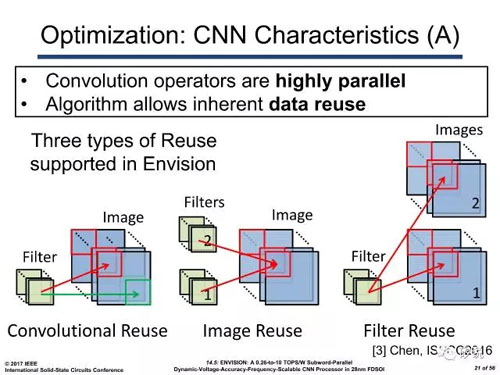
而来自比利时的IMEC在报告14.5中对该问题也有涉及。其方案在Eyeriss的基础上,沿用了其在2016年VLSI提出的2D SIMD方案。轮流复用输入与参数,达到高效的数据分解。
趋势二:更低的Inference计算/存储位宽
在过去的一年,对AI芯片最大的演进可能就是位宽的迅速衰减。从32位fixed point,16位fixed point,8位fixedpoint,甚至4位fixed point的位宽。在CS的理论计算领域,2位甚至2进制的参数位宽。在ISSCC上,这些“传说”都已经逐渐进入实践领域。
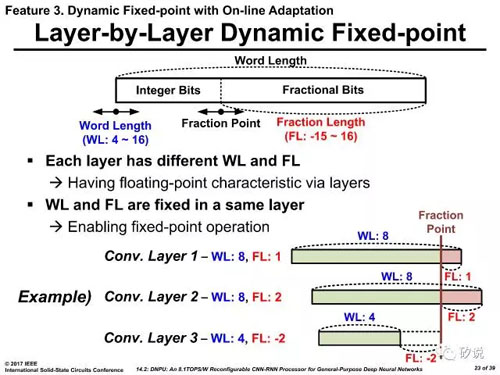
KAIST采用了类似传说中Nervana的flexpoint方案,在定点系统中采用可浮动的定点进制方案。该方案的前提是在某一固定层的前提下,所有该层的卷积核均服从一个由训练确定的进制方案,但是在层和层之间是可以变化的。
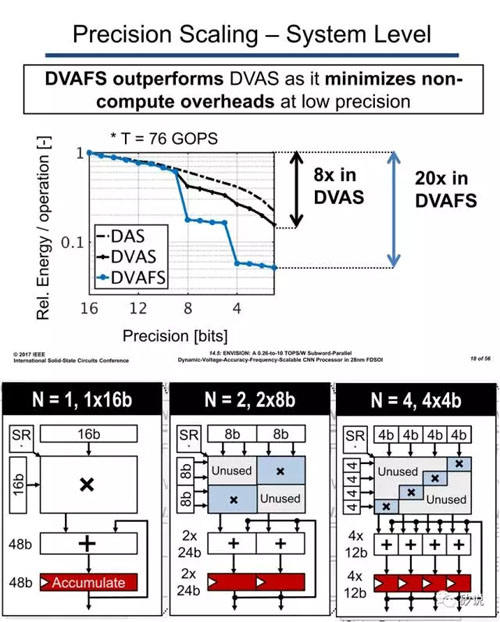
其实,这类方法也不是近年来的创举,在《脑心编(四)》中我们提到的ARM SIMD指令集——NEON就已经采取了这些办法,只是最小位宽没有到达4位罢了。而报告14.5中IMEC的方案在变化进制的基础上,进一步采用的通过改变电压和频率的方法得到更优的能效值。
另外,指的一提的是参数的非线性映射以减少参数读取时的位宽也成为了一个新的关注点。其理论基础由Stanford 大学Bill Dally课题组提出,目前已经出现了类似的芯片实现,详见14.2。

趋势三:更多样的存储器定制设计
当乘加计算(MAC,Multiplier and accumulation)不再成为神经网络加速器的设计瓶颈时,一个新的研究方向就冉冉而生——如何减少存储器的访问延时。在《脑心编(六)》里,我们提到过,离计算越近的存储器越值钱。于是新型的存储结构也应运而生。
首先是密歇根大学提出了面向深度学习优化的协处理器多层高速缓存机制,通过数据的重要性对数据位置进行定义。
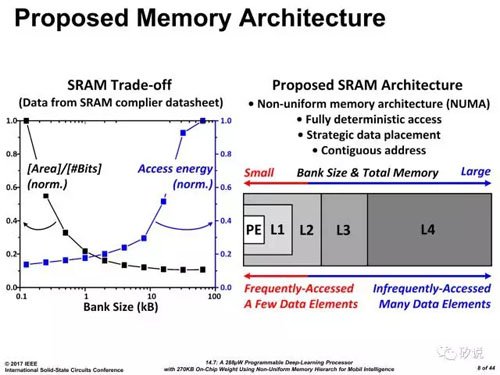
在KAIST的另外一篇文章14.6里,作者提出了一种可转置(transpose)的SRAM架构,即数据的写入与读出可以是通向的,也可以是垂直的。该方法能省去卷积网络中额外的数据整理,并且就大卷积的解构提供了芯思路。

趋势四:更稀疏的大规模向量乘实现
神经网络虽然大,但是,实际上的有非常多以零为输入的情况(Relu输出或者系数为0)此时稀疏计算可以高校地减少无用能效。来自哈佛大学的团队就该问题优化的五级流水线结构,在最后一级输出了触发信号,见14.3。
在Activation层后对下一次计算的必要性进行预先判断,如果发现这是一个稀疏节点,则触发SKIP信号,避免乘法运算的功耗,以达到减少无用功耗的问题。
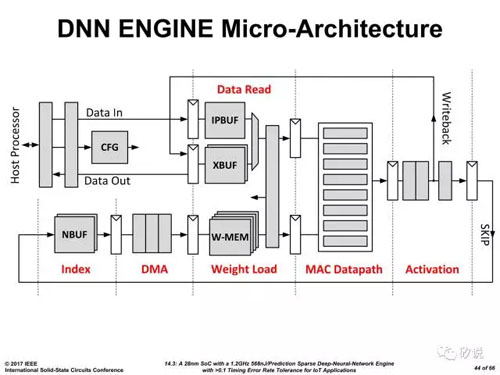
这一问题甚至受到了Bill Dally老人家的关注,在其Forum的演讲中提到了它们尚未发表的稀疏加速架构。
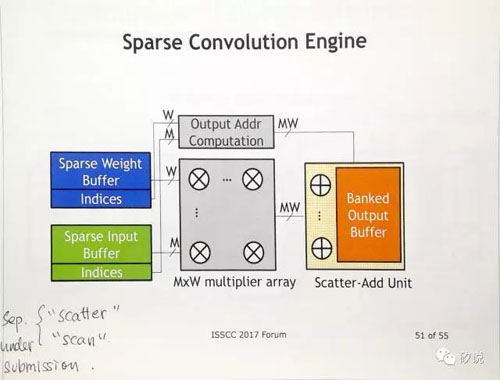
只可惜,我们要直到九月份才能读到paper。
最后,我们总结下这四个趋势的关键词——复用、位宽、存储、稀疏。要做 AI 芯片的你,有关注到的么?
【本文是51CTO专栏机构机器之心的原创文章,微信公众号“机器之心( id: almosthuman2014)”】