作为系列文章的第三篇,本文将重点探讨数据采集层中的用户行为数据采集系统。这里的用户行为,指的是用户与产品UI的交互行为,主要表现在Android App、iOS App与Web页面上。这些交互行为,有的会与后端服务通信,有的仅仅引起前端UI的变化,但是不管是哪种行为,其背后总是伴随着一组属性数据。对于与后端发生交互的行为,我们可以从后端服务日志、业务数据库中拿到相关数据;而对于那些仅仅发生在前端的行为,则需要依靠前端主动上报给后端才能知晓。用户行为数据采集系统,便是负责从前端采集所需的完整的用户行为信息,用于数据分析和其他业务。
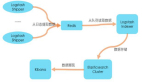
举个例子,下图所示是一次营销活动(简化版)的注册流程。如果仅仅依靠后端业务数据库,我们只能知道活动带来了多少新注册用户。而通过采集用户在前端的操作行为,则可以分析出整个活动的转化情况:海报页面浏览量—>>点击”立即注册”跳转注册页面量—>>点击“获取验证码”数量—>>提交注册信息数量—>>真实注册用户量。而前端用户行为数据的价值不仅限于这样的转化率分析,还可以挖掘出更多的有用信息,甚至可以与产品业务结合,比如笔者最近在做的用户评分系统,便会从用户行为中抽取一部分数据作为评分依据。
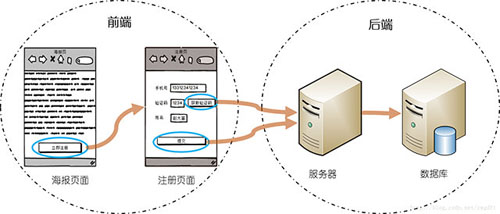
在早期的产品开发中,后端研发人员每人负责一个摊子,虽然也会做些数据采集的事情,但是基本上只针对自己的功能,各做各的。通常做法是,根据产品经理提出的数据需求,设计一个结构化的数据表来存储数据,然后开个REST API给前端,用来上报数据;前端负责在相应的位置埋点,按照协商好的数据格式上报给后端。随着业务的发展,这样的做法暴露了很多问题,给前后端都带来了混乱,主要表现在:前端四处埋点,上报时调用的API不统一,上报的数据格式不统一;后端数据分散在多个数据表中,与业务逻辑耦合严重。
于是,我们考虑做一个统一的用户行为数据采集系统,基本的原则是:统一上报方式、统一数据格式、数据集中存储、尽可能全量采集。具体到实现上,归纳起来主要要解决三个问题:
采什么。搞清楚需要什么数据,抽象出一个统一的数据格式。
前端怎么采。解决前端如何有效埋点、全量采集的问题。
后端怎么存。解决数据集中存储、易于分析的问题。
采什么
用户在前端UI上的操作,大多数表现为两类:***类,打开某个页面,浏览其中的信息,然后点击感兴趣的内容进一步浏览;第二类,打开某个页面,根据UI的提示输入相关信息,然后点击提交。其行为可以归纳为三种:浏览、输入和点击(在移动端,有时也表现为滑动)。其中,浏览和点击是引起页面变化和逻辑处理的重要事件,输入总是与点击事件关联在一起。
因此,浏览和点击便是我们要采集的对象。对于浏览,我们关注的是浏览了哪个页面,以及与之相关的元数据;对于点击,我们关注的是点击了哪个页面的哪个元素,与该元素相关联的其他元素的信息,以及相关的元数据。页面,在Android与IOS上使用View名称来表示,在Web页面上使用URL(hostname+pathname)来表示。
元素,使用前端开发中的UI元素id来表示。与元素相关联的其他元素信息,指的是与“点击”相关联的输入/选择信息,比如在上面的注册页面中,与“提交”按钮相关联的信息有手机号、验证码、姓名。元数据,是指页面能提供的其他有用信息,比如URL中的参数、App中跳转页面时传递的参数等等,这些数据往往都是很重要的维度信息。
除了这些页面中的数据信息,还有两个重要的维度信息:用户和时间。用户维度,用来关联同一用户在某个客户端上的行为,采用的方案是由后端生成一个随机的UUID,前端拿到后自己缓存,如果是登录用户,可以通过元数据中的用户id来关联;时间维度,主要用于数据统计,考虑到前端可能延迟上报,前端上报时会加上事件的发生时间(目前大多数正常使用的移动端,时间信息应该是自动同步的)。
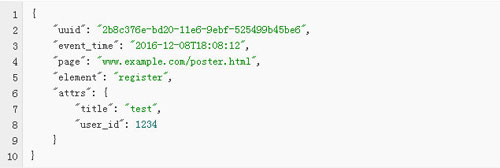
综合起来,将前端上报的数据格式定义如下。uuid、event_time、page是必填字段,element是点击事件的必填字段,attrs包含了上述的元数据、与元素相关联的其他元素的信息,是动态变化的。
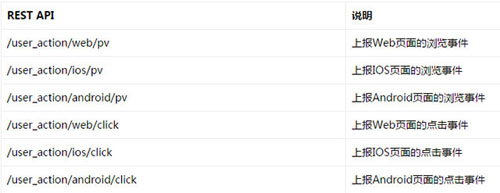
而针对不同客户端的不同事件,通过不同的REST API来上报,每个客户端只需调用与自己相关的两个API即可。
前端怎么采
整理好数据格式和上报方式后,前端的重点工作便是如何埋点。传统的埋点方式,就是在需要上报的位置组织数据、调用API,将数据传给后端,比如百度统计、google analysis都是这样做的。这是最常用的方式,缺点是需要在代码里嵌入调用,与业务逻辑耦合在一起。近几年,一些新的数据公司提出了“无埋点”的概念,通过在底层hook所有的点击事件,将用户的操作尽量多的采集下来,因此也可以称为“全埋点”。这种方式无需嵌入调用,代码耦合性弱,但是会采集较多的无用数据,可控性差。经过一番调研,结合我们自己的业务,形成了这样几点设计思路:
hook底层的点击事件来做数据上报,在上报的地方统一做数据整理工作。
通过UI元素的属性值来设置是否对该元素的点击事件上报。
通过UI元素的属性值来设置元素的关联关系,用于获取上述的“与元素相关联的其他元素的信息”。
我们首先在Web的H5页面中做了实践,核心的代码很简单。***,在页面加载时绑定所有的click事件,上报页面浏览事件数据。第二,通过user_action_id属性来表示一个元素是否需要上报点击事件,通过user_action_relation属性来声明当前元素被关联到哪个元素上面,具体代码实现不解释,很简单。

上述代码可以嵌入到任何HTML页面,然后只要在对应的元素中进行申明就好了。举个例子,

后端怎么存
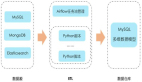
数据进入后台后,首先接入Kafka队列中,采用生产消费者模式来处理。这样做的好处有:***,功能分离,上报的API接口不关心数据处理功能,只负责接入数据;第二,数据缓冲,数据上报的速率是不可控的,取决于用户使用频率,采用该模式可以一定程度地缓冲数据;第三,易于扩展,在数据量大时,通过增加数据处理Worker来扩展,提高处理速率。
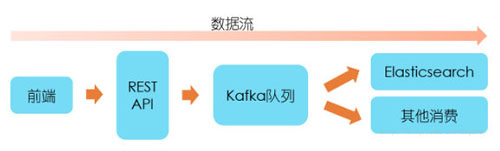
除了前端上报的数据内容外,我们还需要在后端加入一些其他的必要信息。在数据接入Kafka队列之前,需要加入五个维度信息:客户端类型(Web/Android/IOS)、事件类型(浏览/点击)、时间、客户端IP和User Agent。在消费者Worker从Kafka取出数据后,需要加入一个名为event_id的字段数据,具体含义等下解释。因此,***存入的数据格式便如下所示:

再来看event_id的含义。前端传过来的一组组数据中,通过page和element可以区分出究竟是发生了什么事件,但是这些都是前端UI的名称,大部分是开发者才能看懂的语言,因此我们需要为感兴趣的事件添加一个通俗易懂的名称,比如上面的数据对应的事件名称为“在海报页面中注册”。将page+element、事件名称进行关联映射,然后将相应的数据记录id作为event id添加到上述的数据中,方便后期做数据分析时根据跟event id来做事件聚合。做这件事有两种方式:一种是允许相关人员通过页面进行配置,手动关联;一种是前端上报时带上事件名称,目前这两种方式我们都在使用。
***,来看看数据存储的问题。传统的关系型数据库在存储数据时,采用的是行列二维结构来表示数据,每一行数据都具有相同的列字段,而这样的存储方式显示不适合上面的数据格式,因为我们无法预知attrs中有哪些字段数据。象用户行为数据、日志数据都属于半结构化数据,所谓半结构化数据,就是结构变化的结构化数据(WIKI中的定义),适合使用NoSQL来做数据存储。我们选用的是ElasticSearch来做数据存储,主要基于这么两点考虑:
Elasticsearch是一个实时的分布式搜索引擎和分析引擎,具有很强的数据搜索和聚合分析能力。
在这之前我们已经搭建了一个ELK日志系统,可以复用Elasticsearch集群做存储,也可以复用Kibana来做一些基础的数据分析可视化。
Elasticsearch的使用方法可以参考Elasticsearch使用总结一文,这里不做过多讲解。使用Elasticsearch来做数据存储,最重要的是两件事:建立Elasticsearch的映射模板、批量插入。Elasticsearch会根据插入的数据自动建立缺失的index和doc type,并对字段建立mapping,而我们要做的创建一个dynamic template,告诉Elasticsearch如何自动建立,参考如下。批量插入,可以通过Elasticsearch的bulk API轻松解决。