作为系列文章的第二篇,本文将首先来探讨应用层中的运营数据系统,因为运营数据几乎是所有互联网创业公司开始做数据的起点,也是早期数据服务的主要对象。本文将着重回顾下我们做了哪些工作、遇到过哪些问题、如何解决并实现了相应的功能。
早期数据服务
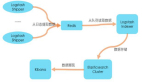
产品上线开始推广后不久,后台研发人员便会经常收到运营同事的私信:“能不能查一下有多少用户注册了,来自哪里?……..”。几次之后,大家便觉得这样的效率太低了:研发人员需要在繁忙的开发任务中抽时间来做数据查询、统计,而运营同事则需要等很久才能拿到数据。于是,大家开始协商更好的方法,最终达成一致:由运营同事提供所需的数据模板,后台研发人员根据模板将数据导入Excel文件,运营同事可根据自身需求自己分析统计。这便是早期的数据服务了,其组成结构如下图所示。
运营数据系统")
这样的做法简单明了,后台研发人员根据数据模板写一个Python脚本,从业务数据库中将数据捞出来,做些分析、整合后,将结果输出到一个Excel文件,然后发送邮件通知运营同事接收文件。然而,随着需求的增加和细化、数据量的增加,暴露的问题越来越多,这里先罗列出来,这些问题有的会在本文提出解决方案,有的则会在后面的文章中陆续提出解决方案。
- Worker越来越多,分布在多个地方,存在很多重复的劳动和代码,某个逻辑的修改需要改很多文件。
- 由于使用ORM来访问数据库,很多代码只考虑逻辑,没考虑到查询数据的效率问题,导致有些报告需要跑十几个小时才能出结果(在循环查询数据的性能问题及优化一文有讲解)。
- 中间计算结果流失,数据没有共享,每个Worker都要跑自己的逻辑去算一遍。
- Woker依靠crontab来控制触发,没有监管,经常由于脏数据导致中断,需要等到运营同事发现后报过来才知道。
运营数据Dashboard
随着业务的发展,以数据报表的形式来提供数据服务逐渐不能满足需求了。一方面,高层期望每天一早便能看到清晰的数据,搞清楚最近的运营效果和趋势;另一方面,虽然数据报表提供了详细的数据,但是还是需要手动去过滤、统计一下才有结果,所有想看数据的人都需要做一遍才行,而业务人员处理Excel的水平层次不齐。
于是,我们开始筹划Dashboard系统,以Web的形式提供数据可视化服务。可是,Dashboard要做成什么样子?由于产品经理和设计人员都忙于产品业务,所以只能自己考虑要做什么、怎么做。好在笔者之前用过百度统计,对那里面的一些统计服务比较清楚,结合公司的业务,形成了一些思路:
数据内容上,包含:核心指标数据和图表分析两部分。前者以曲线图为主,要能快速显示数量和趋势,比如注册日增量趋势图;后者使用各种图表来展现某个时间段内的分析结果,比如10月份的***0用户感兴趣品牌。
数据类型上,包含:C端核心指标、B端核心指标、核心分析和专题活动指标与分析。前两者是分别针对C端和B端的指标数据,核心分析是一些综合的分析,比如转化率分析,专题活动是针对一些特定的大型运营活动。
数据维度上,包含:时间维度、城市维度和B端品牌维度。时间是最基本最重要的维度,城市维度可以分析各个运营大区的状态,B端品牌维度主要是针对B端上的业务。
整理后便形成了下图所示的Mockup(简化版),基本涵盖了上述的思路。虽然在美观上相对欠缺,但是毕竟是内部使用嘛,重要的数据显示要能准确、快速。
运营数据系统")
搞清楚了要做什么,接下来就是要将想法落地,考虑如何实现了。
整体架构
系统的整体架构如下图所示,主要基于这么几点考虑:
前后端分离。前端只负责加载图表、请求数据并显示,不做任何数据逻辑处理;后端负责产出数据,并提供REST API与前端交互。
离线与实时计算并存。为了提高数据获取的速度,曲线指标数据采用离线计算的方式,提供历史数据供前端展示;图表分析类数据采用实时计算的方式,其速度取决于所选时间段内的数据量,必要时进行缓存。
运营数据系统")
前端实现
Dashboard系统的前端并不复杂,前面也提到我们不会做太多样式上的工作,重点是数据的显示。那么,***件事就是要寻找一款图表库。笔者这里选择的是百度ECharts,其提供了丰富的图表类型,可视化效果很棒,对移动端的支持很友好,重要的是有详细的示例和文档。事实证明ECharts确实很强大,很好的满足了我们的各种需求。
选好了图表库,接下来的问题是如何优雅的加载几十个图表,甚至更多。这就需要找到图表显示共性的地方(行为和属性),进行抽象。通常,使用ECharts显示一个数据图表需要四步(官方文档):***步,引入ECharts的JS文件;第二步,声明一个DIV作为图表的容器;第三步,初始化一个echart实例,将其与DIV元素绑定,并初始化配置项;第四步,加载图表的数据并显示。可以发现,行为上主要分为初始化和更新数据两个,属性上主要是初始配置项和数据。
基于此,笔者使用“Pattern+Engine”的思想来实现前端数据加载。首先,在JS中使用JSON对每个图表进行配置,即写Pattern。例如,下面的配置便对应了一个图表,elementId是DIV的id,title是图表的标题,names是图表的曲线名称,url提供了获取数据的API,loader表示要加载的图表Engine。而一个页面的图表便由一组这样的配置项组成。
运营数据系统")
页面加载时,根据Pattern中的配置项生成相应的Loader Engine实例,用来初始化图表和更新数据。每个Loader对应一个ECharts图表类型,因为不同图表类型的初始化和加载数据的方法不同。程序类图如下所示。
运营数据系统")
后端实现
前面提到在早期的数据服务中,存在很多重复劳动和代码,因此在Dashboard系统的后端实现中,笔者开始考虑构建数据分析的公共库,这块占据了很大一部分工作量。底层公共库不针对任何特殊业务需求,主要负责三件事:***,封装数据源连接方法;第二,封装时间序列的生成方法,产生以天、周、月为间隔的时间序列;第三,封装基础的数据查询、清洗、统计、分析方法,形成格式化的数据,这部分是最重要的。
完成了底层公共库的构建后,整个代码结构一下子就清爽了很多。在其基础上,开始构建上层的Analyzer。Analyzer用于完成具体的数据分析需求,每个Analyzer负责一个或多个数据指标的产出,每个曲线图/图表的数据由一个Analyzer来负责。离线计算与实时计算,则是分别在Schedule和Web请求的触发下,调用对应的Analyzer来完成数据产出。因此,整个后台系统分为三层来实现,如下图所示。
运营数据系统")
***谈一谈离线数据的问题。目前离线计算是由Schedule来触发,每日零点计算前一日的数据,数据按照“每个指标在不同维度上每天一个数据点”的原则来生成,由上述的Analyzer来负责产出格式化的数据,存入MongoDB中。由于查询规则简单,只需建立一个组合索引就可以解决效率问题了。目前数据量在500W左右,暂时没有出现性能问题,后期可以考虑将部分历史数据迁移,当然这是后话。
数据报表
Dashboard上线后,我们开始考虑将早期的数据报表服务逐步停下来,减少维护的成本。而运营同事希望能继续保留部分报表,因为Dashboard虽然提供了很多数据指标和分析,但是有些工作需要更精细的数据信息来做,比如给带来微信注册的校园代理结算工资、对新注册用户电话回访等等。经过一番梳理和协商,最终保留了六个数据报表。另一方面,B端的商家期望能在后台导出自己的相关数据。综合两方面需求,笔者构建了新的数据报表系统。
运营数据系统")
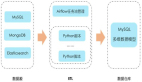
新的数据报表系统,按照流程来划分为三部分:触发、执行与通知。内部数据报表依旧由Schedule触发,启动相应的Worker进程来执行;而提供给外部的报表由Web前端通过REST API来触发,将相应的任务加入Celery任务队列中执行。执行体由一组Exporter来完成,Exporter负责获取数据、生成适合写入Excel的数据格式、写Excel文件,数据获取部分依赖前面所述的底层公共库。***,统一发送邮件通知。
考虑到早期数据服务中经常遇到异常导致生成报表失败的问题,笔者在新的数据报表系统中做了两点与异常相关的处理:
使用Airflow对Schedule触发的任务进行监控(后续文章会有详细介绍),手动触发的任务则由Celery进行监控,遇到异常便发送邮件通知到开发人员。
如果一个Excel数据文件由多个Sheet组成,当某个Sheet出现异常时,通常由两种处理方法:一是丢弃整个文件,二是保留其他Sheet信息继续生成Excel文件。这里,内部报告使用了第二种处理方法,外部报告相对严谨,使用了***种。
以上便是笔者所在公司的运营数据系统的发展历程和现状,目前Dashboard与数据报表两个系统已经趋于稳定,基本提供了90%以上的运营数据服务。当然,随着数据量的增长、业务需求的发展,一定会面临更多新的挑战。
点击查看:
创业公司做数据分析(三)用户行为数据采集系统
创业公司做数据分析(四)ELK日志系统
创业公司做数据分析(五)微信分享追踪系统
创业公司做数据分析(六)数据仓库的建设