了解“认知心理学”的朋友应该知道:人类对事物的认知,总是由浅入深。然而,每个人思考的深度千差万别,关键在于思考的方式。通过提问三部曲:WHAT->HOW->WHY,可以帮助我们一步步地从事物的表象深入到事物的本质。比如学习一个新的技术框架,需要逐步搞清楚她是什么、如何使用、为什么这样设计,由浅入深。
“WHY+HOW+WHAT”,是笔者最钟爱的一种思维模式。其使用方法不仅限于上述认知过程中的思考方式,通过不同的顺序组合,可以使用在不同的场景。比如,在筹划一个项目时,采用“WHY->WHAT->HOW”的思考方式,先搞清楚为什么要做这个项目,然后是需要做哪些工作来完成这个项目,***考虑怎么做、技术选型。这个思考方式也将被广泛使用在本系列的各个文章中。
在过去的一年里,笔者加入了一家移动互联网创业公司,工作之一便是负责数据业务的建设,陆陆续续完成了一些数据系统的实现,来满足公司的数据需求。在创业公司中做数据相关的事情,而且是从零做起,肯定不像很多大公司那样分工明细,所有的工作都要保证在有限的资源下来满足需求。回想起来也蛮有意思,因此想做些总结分享,结合我们的系统来谈一谈如何做数据分析。如果有写的不好的地方,还请网友指正。
作为系列文章的开篇,本文将按照“WHY->WHAT->HOW”的思考方式来阐述下面三个问题:
- 创业公司为什么需要做数据分析?
- 创业公司做数据分析,需要做哪些事情?
- 如何实现这些数据上的需求?
WHY
随着移动互联网的发展和大数据思维的普及,越来越多的创业者、投资人开始重视数据的作用,而不再是随便拍脑袋。“数据驱动决策”、“精准化运营”、“产品快速迭代”这些概念被越来越多的人提出和使用,其背后都离不开精准的数据分析。对于大多数互联网创业公司来说,其背后没有强大的资源与财主支撑,如何在有限的人力、物力下快速摸索、少走弯路是至关重要的,而基于“数据驱动”来做决策、运营与产品将起到一个关键的作用。让我们来看两个例子。
【例一】
微信公众号早已成为各家运营的主战场之一,利用微信的关系链来转发H5海报页面是众多线上活动和拉新的一个重要方式。然而,不管是做某个线上推广活动,还是通过线下某个渠道引导用户分享、注册,我们都需要指标来衡量活动效果,从而摸清运营的方向。数据,便是关键!该活动带来的浏览量、分享量、新注册用户数、用户留存率都是重要的指标,而这一切都离不开有效的数据追踪与分析。如果同时有100个这样的渠道活动,如何统筹各个数据分析也将是一件无法忽视的事情。(下图呈现的是某次活动的传播网络的一部分)
【例二】
每逢节假日,国内各个旅游景点都是人山人海,尽管大家都知道外出游玩会遭遇这种情况,但是还是抱着一丝侥幸心理出行,毕竟好不容易有了假期嘛。在今年十一时,笔者就曾利用百度景区热力分布图来提前观察,从而避开了一些高峰期和人满为患的景区,大家不妨也试一试。
回到正题,对于很多创业公司,特别基于LBS提供服务的企业来说,都期望搞清楚“用户在哪里”、“哪里是用户感兴趣的地方”,从而摸清早期的投入方向,毕竟全面开花、四处征战的方式是不适于创业公司的。通过位置数据,来分析用户集中在哪些区域,主要分布在商业区还是高校,是否受到交通因素影响等等,当然,具体需要结合业务来做了。另一方面,还可以聚合出用户的常驻位置,可以对用户位置与商户位置的距离进行分析等等,从而形成推荐方案,优化产品与服务。
开篇")
WHAT
对于大多数互联网创业公司,在做数据分析时,一定要结合自己的业务,把握一个度,在投入可控的范围内达到效果即可。数据深度挖掘、机器学习、推荐算法等等,这些技术名词背后都需要投入一定的人力、物力来支撑,即使是大厂来玩,产出也相对有限,而且很多时候实际工程效果不尽人意。举个列子,很多高端的“推荐算法”在投入使用后,其效果远不如“看了又看”来的简单有效。当然,如果你的公司就是做数据这方面的业务,那是另一回事了。
要搞清楚需要做什么,不妨先结合自身业务思考一下,现阶段自己需要什么数据来驱动决策、运营与产品。具体业务方面的数据需求,各家都不一样。从笔者接触的情况来看,早期大部分的数据需求集中在两块:运营数据的统计分析、产品使用情况的统计分析。后期随着产品线的发展,一般会延伸出一些与产品相关的数据业务,比如线上推荐。
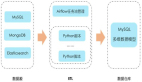
从流程上看,需要做的事情集中在三部分:数据采集、数据处理和数据可视化,伴随着数据的变迁:原始数据->分析结果->图表呈现。首先,基础数据源的建设是做好数据分析的关键,因为如果数据源本身出了问题,那么后面做的所有工作都是没有意义的,而且如果没有提前做好数据采集,后期想做分析时也没有数据可做。
其次,数据分析的最终结果是需要呈现给别人看的,可能是公司高层,也可能是市场业务人员,直接将一堆数据丢给他们显然是不现实的,通常都需要转换为图表的形式,这便是数据可视化的工作。而从原始数据源到分析结果的过程,便归纳为数据处理,其涵盖了数据提取、数据建模、数据分析等多个步骤。
开篇")
HOW
现如今国内的互联网环境发展的越来越好,第三方服务提供商越来越多。所以很多情况下我们都有两个选择:接入第三方、自己做。
数据分析这块,便有很多第三方服务,笔者将其划分为传统数据统计服务与新兴的数据公司。前者以百度统计、google analysis为代表,通过嵌入其SDK在前端采集数据,在后台便可以查看相应的统计数据。这种方式的好处是简单、免费,使用非常普及,是很多初创企业的***。
缺点也很明显,一是这样的统计只能分析一些基本的访问量、点击率、活跃用户量,满足基本需求,无法结合业务数据来做深度分析;二是需要在前端很多地方埋点上报,耦合性较强;三是数据存储在第三方的服务器中,无法直接获取到数据源。
后者以神策、GrowingIO、诸葛IO为代表,这些公司也正是看到了传统数据统计服务的缺点,从而提出相应的解决方案,各有特色。但是,需要不菲的接入费用,私有部署的费用更多,而这笔费用对于一个初创企业来说,还是蛮多的。另一方面他们更加侧重于电商领域的数据分析,因为这个领域的分析模式已经基本成型,适合做成模板来使用。
选择自己做的话,可以结合自身的业务,做的更灵活,同时也可以尽早摸索数据业务,逐步建立相应的数据系统。当然,自己做并不代表是造轮子,而是要充分利用开源框架来实现相应的功能。
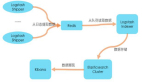
鉴于各家的业务都不同,而抛开业务谈架构都是耍流氓,所以在接下来的文章中,笔者将结合自己接触的业务来探讨一些数据系统的实现。下图所示便是现阶段我们的数据系统架构,主要分为数据采集、数据处理与数据应用三层。
从下往上,数据采集层负责从前端App、H5页面、服务器日志采集数据,通过Kafka接入后存入Elasticsearch与neo4j中,同时业务数据库也是很重要的数据源;数据处理层负责数据的抽取、清洗、建模,然后存入MongoDB与MySQL中,整个过程由Airflow任务调度管理系统来进行管理与监控;产出的数据最终提供给应用层使用。
也许有人要说,连Hadoop都没用到,怎么号称自己在做数据分析呢。笔者曾经也做过考虑和尝试,最终暂时搁置了Hadoop,主要是数据增长相对缓慢并且没有很明显的需求,目前这个架构可以在较长一段时间内应对数据需求了。
开篇")
点击查看:
创业公司做数据分析(三)用户行为数据采集系统
创业公司做数据分析(四)ELK日志系统
创业公司做数据分析(五)微信分享追踪系统
创业公司做数据分析(六)数据仓库的建设