近些年,深度学习在语音识别、图像处理、自然语言处理等领域都取得了很大的突破与成就。相对来说,深度学习在推荐系统领域的研究与应用还处于早期阶段。
携程在深度学习与推荐系统结合的领域也进行了相关的研究与应用,并在国际人工智能***会议AAAI 2017上发表了相应的研究成果《A Hybrid Collaborative Filtering Model with Deep Structure for Recommender Systems》,本文将分享深度学习在推荐系统上的应用,同时介绍携程基础BI团队在这一领域上的实践。
一、推荐系统介绍
推荐系统的功能是帮助用户主动找到满足其偏好的个性化物品并推荐给用户。推荐系统的输入数据可以多种多样,归纳起来分为用户(User)、物品(Item)和评分(Ratings)三个层面,它们分别对应于一个矩阵中的行、列、值。对于一个特定用户,推荐系统的输出为一个推荐列表,该列表按照偏好得分顺序给出了该用户可能感兴趣的物品。

图1. 推荐系统问题描述
如图1右边所示,推荐问题一个典型的形式化描述如下:我们拥有一个大型稀疏矩阵,该矩阵的每一行表示一个User,每一列表示一个Item,矩阵中每个“+”号表示该User对Item的Rating,(该分值可以是二值化分值,喜欢与不喜欢;也可以是0~5的分值等)。
现在需要解决的问题是:给定该矩阵之后,对于某一个User,向其推荐那些Rating缺失的Item(对应于矩阵中的“?”号)。有了如上的形式化描述之后,推荐系统要解决的问题归结为两部分,分别为预测(Prediction)与推荐(Recommendation)。
“预测”要解决的问题是推断每一个User对每一个Item的偏爱程度,“推荐”要解决的问题是根据预测环节所计算的结果向用户推荐他没有打过分的Item。但目前绝大多数推荐算法都把精力集中在“预测”环节上,“推荐”环节则根据预测环节计算出的得分按照高低排序推荐给用户,本次分享介绍的方案主要也是”预测”评分矩阵R中missing的评分值。
二、基于协同过滤的推荐
基于协同过滤的推荐通过收集用户过去的行为以获得其对物品的显示或隐式信息,根据用户对物品的偏好,发现物品或者用户的相关性,然后基于这些关联性进行推荐。
其主要可以分为两类:分别是memory-based推荐与model-based推荐。其中memory-based推荐主要分为Item-based方法与User-based方法。协同过滤分类见图2。

图2. 协同过滤分类
Memory-based推荐方法通过执行最近邻搜索,把每一个Item或者User看成一个向量,计算其他所有Item或者User与它的相似度。有了Item或者User之间的两两相似度之后,就可以进行预测与推荐了。

图3. 矩阵分解示意图
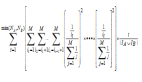
Model-based推荐最常见的方法为Matrix factorization,其示意图见图3左边。矩阵分解通过把原始的评分矩阵R分解为两个矩阵相乘,并且只考虑有评分的值,训练时不考虑missing项的值,如图3右边所示。R矩阵分解成为U与V两个矩阵后,评分矩阵R中missing的值就可以通过U矩阵中的某列和V矩阵的某行相乘得到。矩阵分解的目标函数见图3,U矩阵与V矩阵的可以通过梯度下降(gradient descent)算法求得,通过交替更新u与v多次迭代收敛之后可求出U与V。
矩阵分解背后的核心思想,找到两个矩阵,它们相乘之后得到的那个矩阵的值,与评分矩阵R中有值的位置中的值尽可能接近。这样一来,分解出来的两个矩阵相乘就尽可能还原了评分矩阵R,因为有值的地方,值都相差得尽可能地小,那么missing的值通过这样的方式计算得到,比较符合趋势。
协同过滤中主要存在如下两个问题:稀疏性与冷启动问题。已有的方案通常会通过引入多个不同的数据源或者辅助信息(Side information)来解决这些问题,用户的Side information可以是用户的基本个人信息、用户画像信息等,而Item的Side information可以是物品的content信息等。例如文献[1]提出了一个Collective Matrix Factorization(CMF)模型,如图4所示。

图4. Collective Matrix Factorization模型
CMF模型通过分别分解评分矩阵R,User的side information矩阵,Item的side information矩阵,其中User或者Item出现在多个矩阵中,其所分解的隐向量都是一致的。
三、深度学习在推荐系统中的应用
Model-based方法的目的就是学习到User的隐向量矩阵U与Item的隐向量矩阵V。我们可以通过深度学习来学习这些抽象表示的隐向量。
Autoencoder(AE)是一个无监督学习模型,它利用反向传播算法,让模型的输出等于输入。文献[2]利用AE来预测用户对物品missing的评分值,该模型的输入为评分矩阵R中的一行(User-based)或者一列(Item-based),其目标函数通过计算输入与输出的损失来优化模型,而R中missing的评分值通过模型的输出来预测,进而为用户做推荐,其模型如图5所示。

图5. Item-based AutoRec模型
Denoising Autoencoder(DAE)是在AE的基础之上,对输入的训练数据加入噪声。所以DAE必须学习去除这些噪声而获得真正的没有被噪声污染过的输入数据。因此,这就迫使编码器去学习输入数据的更加鲁棒的表达,通常DAE的泛化能力比一般的AE强。Stacked Denoising Autoencoder(SDAE)是一个多层的AE组成的神经网络,其前一层自编码器的输出作为其后一层自编码器的输入,如图6所示。

图6. SDAE
文献[3]在SDAE的基础之上,提出了Bayesian SDAE模型,并利用该模型来学习Item的隐向量,其输入为Item的Side information。该模型假设SDAE中的参数满足高斯分布,同时假设User的隐向量也满足高斯分布,进而利用概率矩阵分解来拟合原始评分矩阵。该模型通过***后验估计(MAP)得到其要优化的目标函数,进而利用梯度下降学习模型参数,从而得到User与Item对应的隐向量矩阵。其图模型如图7所示。

图7. Bayesian SDAE for Recommendation Sysytem
在已有工作的基础之上,携程基础BI算法团队通过改进现有的深度模型,提出了一种新的混合协同过滤模型,并将其成果投稿与国际人工智能***会议AAAI 2017并被接受。该成果通过利用User和Item的评分矩阵R以及对应的Side information来学习User和Item的隐向量矩阵U与V,进而预测出评分矩阵R中missing的值,并为用户做物品推荐。
")
图8. Additional Stacked Denoising Autoencoder(aSDAE)
该成果中提出了一种Additional Stacked Denoising Autoencoder(aSDAE)的深度模型用来学习User和Item的隐向量,该模型的输入为User或者Item的评分值列表,每个隐层都会接受其对应的Side information信息的输入(该模型灵感来自于NLP中的Seq-2-Seq模型,每层都会接受一个输入,我们的模型中每层接受的输入都是一样的,因此最终的输出也尽可能的与输入相等),其模型图见图8。
结合aSDAE与矩阵分解模型,我们提出了一种混合协同过滤模型,见图9所示。该模型通过两个aSDAE学习User与Item的隐向量,通过两个学习到隐向量的内积去拟合原始评分矩阵R中存在的值,其目标函数由矩阵分解以及两个aSDAE的损失函数组成,可通过stochastic gradient descent(SGD)学习出U与V,详情大家可以阅读我们的paper《A Hybrid Collaborative Filtering Model with Deep Structure for Recommender Systems》[4]。

图9. 混合协同过滤模型
我们利用RMSE以及RECALL两个指标评估了我们模型的效果性能,并且在多个数据集上和已有的方案做了对比实验。实验效果图如图10所示,实验具体详情可参看我们的paper。

图10. 实验效果对比
在今年的推荐系统***会议RecSys上,Google利用DNN来做YouTube的视频推荐[5],其模型图如图11所示。通过对用户观看的视频,搜索的关键字做embedding,然后在串联上用户的side information等信息,作为DNN的输入,利用一个多层的DNN学习出用户的隐向量,然后在其上面加上一层softmax学习出Item的隐向量,进而即可为用户做Top-N的推荐。

图11. YouTube推荐模型图
此外,文献[6]通过卷积神经网络(CNN)提出了一种卷积矩阵分解,来做文档的推荐,该模型结合了概率矩阵分解(PMF)与CNN模型,图见图12所示。该模型利用CNN来学习Item的隐向量,其对文档的每个词先做embedding,然后拼接所有词组成一个矩阵embedding矩阵,一篇文档即可用一个二维矩阵表示,其中矩阵的行即为文档中词的个数,列即为embedding词向量的长度,然后在该矩阵上做卷积、池化以及映射等,即可得到item的隐向量。User的隐向量和PMF中一样,假设其满足高斯分布,其目标函数由矩阵分解以及CNN的损失函数组成。

图12. 卷积矩阵分解模型
四、总结
本文介绍了一些深度学习在推荐领域的应用,我们发现一些常见的深度模型(DNN, AE, CNN等)都可以应用于推荐系统中,但是针对不同领域的推荐,我们需要更多的高效的模型。随着深度学习技术的发展,我们相信深度学习将会成为推荐系统领域中一项非常重要的技术手段。
本文由携程技术中心投递,ID:ctriptech。作者:董鑫,携程基础业务部BI团队高级算法工程师,博士毕业于上海交通大学计算机科学与技术系。