经过了十个城市的路演,华为HDG线下沙龙终于来到了首都。在北京,开发人员之多,关注的技术领域之广,讨论的话题之深入,堪称HDG历届参与讨论者之最。

吴建林是华为PaaS高级工程师,在他《华为全球IT系统基于PaaS的实践分享》的主题演讲中,绝大部分内容都是之前没有公开过的,例如FusionStage在流程IT内部的跨数据中心解决方案、华为全球分布式路由方案、万级容器管理规模设计等等。在演讲中,针对开发者在传统IT领域开发、测试、运维所遇到的各种问题,以及在新一代PaaS架构下的解决方案,吴建林详细阐述了云化、容器化能给企业、个人带来的价值。
以下是他的现场演讲实录:
首先在这里代表华为公司感谢大家今天过来参加HDG的北京站。在开始讲之前我想先问大家几个问题,因为我后面讲的内容可能会跟这个内容有关系,大家能举个手让我看一下用过Kuberentes和docker的人吗。这么少,4个。还是说我要问一下没有用过的人。
刚才赵阳已经介绍了我们在公有云场景的一些应用,早上的话题主要还是偏应用。我们知道最牛逼的技术如果没有应用场景,还是成就不了生产力。所以我这边要讲的是一个私有云的场景,私有云的场景主要是介绍华为内部IT。华为内部IT系统是相对比较复杂一点的。我先简单介绍一下,我叫吴建林,现在是PaaS落地华为IT落地的主要负责人。
今天主要介绍几个内容,相信应该有一些是企业用户过来的。所以我想讲的是,对于我们这种大型的企业,传统的IT,是怎么往云化做一些迁移,以及我们在这个迁移过程中会遇到什么样的问题,我们是怎么样解决的。
这里先简单介绍一下华为的IT系统。华为的IT系统非常复杂,主要以流程和办公两个为主。其中办公大家相对比较容易理解一点,就是正常的E-mail,或者大家在沟通通讯的esbas(音),还有公司内部自己会自研一些办公的软件。第二个是流程,流程有一个公司比较大的,号称公司内部业务的五朵云,像供应链、财经、销售这些的。基本可以这样理解,华为所有这些业务的运转全部都是靠整个华为IT支撑起来的,如果说用一句话来描述,华为IT应该就算是华为公司背后的那个男人,当然还有人种。
因为这样复杂的系统,现在的部署规模非常大,已经有8个数据中心,单虚拟机的个数就达到数10万台。应该在座的企业,你们企业跟这个规模是一样的,数10万台的虚拟机规模。总共的用户,就是固定的用户,因为是服务华为内部的,现在固定用户差不多有17万家左右。如果再算上一些合作方和一些其他的外部用户,就更多了。应用总共有800多个,当然这个应用是我们重新抽象过的一层。举个例子,刚才像赵阳讲的华为商城的应用,在这边最多就是1到5个应用,所以说它总共有800多个,中间这个系统是非常的大。
正是因为这么复杂的系统,所以它在整个云化的过程会遇到很多的挑战,或者说在传统的IT领域里面有很多的问题。这里面我只举了六点。第一点就是传统IT的模式不够敏捷。我们都知道很多传统的IT领域都是走人工流程的,你可能做一件事情需要很多的审批流程,包括你去申请一些资源,你做开发,都需要很多的审批流程。所以正是因为这些流程,包括你这个过程中,可能非常复杂,在整个申请过程,或者包括开发迭代过程没有快速的迭代。
第二个问题是资源规模的问题,因为涉及到八大数据中心。大家知道一旦涉及跨数据中心的系统,都是非常复杂的,因为它要解决数据中心给大家带来的很多问题。
第三个问题也是我们今天下午要介绍的应用微服务化。微服务化会带来一个比较大的挑战,就是原有的系统变成微服务以后,就会非常的多。差不多现在统计过的有将近3倍以上,因为我们传统的很多IT都是基于openstack,这种IaaS的弹性扩缩,这种速度已经没有办法完成这种微服务的改造了。
第四个问题也是很多企业关注的点,就是它自有利用率很低。我们正常的一个企业可能一台虚拟机上面就布一个应用,而且还是独占的,可能就是搭一个(05:40),这样你整个资源是没有达到一个充分的利用。而且虚拟机的虚拟化成本还是相对比较高的,可以占到15%到25%之间。
第五个问题是全球的应用访问体验,因为我们知道八大数据中心,但是你的业务又必须有一个集中点,所以很多对于路由上的一些控制会比较复杂一点。以前传统的IT可能就是每个立方做一个自己的。
第六个是平台异构,对于我们来说很多的企业可能已经有原有的很多系统,或者很多语言,包括它底下的平台都是不一样的。所以给PaaS的支撑带来很大的问题。
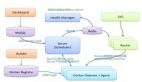
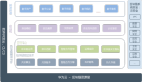
接下来要讲一下整个完整的,就是华为IT,现在PaaS在整个华为IT的内部架构。可以先从上面开始看起,最上层这层是属于业务层,也就是企业内部会有很多自己的应用,自己的内部应用是部署在TaaS层的。再下来的这一层是属于(07:06)流水线,就是说这一曾是整个开发过程中最核心的内容。这一层的保障是由PaaS的核心层,我们这边也称3+1的能力。所谓3+1,第一个叫做应用调度与安排,下午还会详细再讲,第二个是微服务,也是下午会讲,开发流水线,刚好这三个记录框架都是下午的议题。这三个基础的框架,再加上一组中间键服务。这里中间键服务起到非常关键的作用,就是可以把整个基础框架,把整个TaaS-Por的核心层全部都串在一起。下面底层主要还是涉及到跟I层对接。我们以前传统IaaS就是VMware、openstack应用比较多。但是(08:01)这一块是属于混合云的东西,现在我们正在构建。。
上层,对接I层这层的东西,会有很多企业级的应用他要求做同城生活、异地灾备。所以在这个地方,Kuberentes我们是做很多扩展。前面这一层基本是属于一个PaaS的核心部件。因为有很多SB的用户,他可能自己在TaaS的基础上,自己再封装一层能力出去,自己做一些流量统计,计费要怎么计,比如底下要拿虚拟机卖钱,或者拿容器卖钱,怎么计。每个企业都有自己的一套统计方式,所以这一块的能力是我们开放出去的接口,可以允许用户自己再做一个自定义的过程。
在这里分享一下对这种复杂的大型系统,包括跨数据中心架构设计的解决方案。这里我总结了一下,中央集权,地方自治和层级管理。这是什么意思呢?因为我们要管理的数据中心非常多,像华为里面有八大数据中心,如果你没有一个统一管理点,就会变得很分散。很少一个管理者要看的话,可能就要通过不同数据中心的东西去汇总,或者去看,没有一个统一的汇集点。这样会导致你没有一个非常好的大的视角,去看你所有的资源。地方自治指的是,因为我们有很多东西,举个例子,路由,比如在英国的用户你肯定更希望我直接住在英国,访问我英国的应用就好了,不要跳到深圳过来,网络时延就很长。所以自己的地方需要有一套自己自治的机构,也就是说能把你整个应用自维护。他可能知道的这个概念比较浅一点,就是一个简单的执行者,再加上一个故障恢复的人。但是往后到最后我们会有一个真正的大脑,也就是我们中央集权主站点的地方会做所有的任务,包括我们整个完整的东西,一个统筹。
底下就是介绍几个,要做到这个程度我们需要做的几件事情。第一件事情是资源的抽象化,我们知道像AWS内部会有很多资源的概念,比如说哪块区域,哪个(11:06)。因为中间你要做很多的应用调度和编排,这一层能力都是要基于你现有的平台,你把你底下的这些资源全部都抽象化成你的概念,所以这个地方你要对所有的资源做一层建模。这一块的建模能力是要非常清晰的。而且建模可能每一个公司也会建的不一样,对于我们来说中间建了很多,比如说最上层可能就是一个区域,区域比如说是大中华区,下来有分多个数据中心,哪一个里面的,你到时候要做很多的调度,这是一个资源的抽象化。
第二件事情就是任务的消息化,我们知道任务一定要是非常可靠的,不然你任务发过去最后都没有回来,或者这个任务没有被你不同的数据中心接收到,就会导致你整个平台数据是不一致的。这是任务的消息化。
消息要异步化,就是说我们不可能,比如在这个地方发一条信息,发一个任务到巴西那边,因为它时延非常长,不能同步的等待。如果你同步等待的话,会遇到很多问题,中间有可能直接堵塞在那儿了。
往下是整个管理的模块全部都要模块化,就是你所有的东西全部都是要按模块来的,这个跟我们微服务框架是有点像的。往下的话是运用一体化,对于一个运维来说他想要看到的一定是全局的视角,而不是简单单纯的我单看一个数据中心,或者我看一个机房之间的监控情况,所以一定要有一个非常全局的观念。
这是我们fusionstage整个在华为内部IT的上线情况,我们这个做的也相对比较晚一点,是去年2月份才开始做一些试点。一开始做的话主要还是做一些改造,10月份的时候上生产环节,规模相对比较小一点,有1千台虚拟机左右。今年的10月份是开始大规模的推广,现在所有的虚机情况有将近4千台。当然这个地方有很多集群,不是一套集群管4千台。现在这块的东西,能力上我们验证到的就是内部的集群可以达到2千台左右的规模,单集群的。
接下来我会根据不同的角色,今天在座的大部分都是这上面的一些角色,比如说业务开发、测试运维。像业务这边,对业务来说他最想的一件事情是什么,他可能每次直接去跟客户交流,或者跟外面其他人交流,就突然来了一个idea,回去就告诉研发这个idea一定要马上给我实现,所以他要求的就是一个字,快。开发这边,很多开发像我们传统的这样,把时间浪费在有点像后台的资源申请,或者你自己还要搞很多的环境。其实你更应该专注于,你既然是开发,就需要把功能和特性能够做出来,这样能提高很多的生产力。然后是测试,因为我们有很多自动化手动的测试能力,或者自己有时候要写,非常的繁杂。然后是运维,运维就看刚才的那个数10万台的虚拟机,每天手机收到的就像运维人员每天收到的报警有上千条,就是上千条的报警会发到你手机或者E-mail上。所以一旦你整个规模大上去以后,运维是非常大的问题。
为了解决现有这些角色用户的问题,这个地方fusionstage有一些需求的实践。就是在做云化的过程中,从个人理解到的,至少在华为内部IT做的第一件事情就是先把流量统一了。为什么先把流量统一了,因为我们都知道业务在一定的情况下,显示的是以流量的方式来给大家展示的,因为你所有的流量对于业务来说都是非常重要的。所以只有你把流量给统一了,你底端要怎么改,随便你怎么改。原因是我们中间这个地方有一个ELB,我们提供了很多的特性,就是你的路由怎么走,全部都由我们PaaS来控制,中间我们做一些灰度发布的功能。这个功能做出来以后,你以前比如说已经有一些很老的系统,或者跑在虚拟机上面,跑在其他地方的应用,可以原封不动,你可以保留着,只是我中间在路由层这一块给你做控制,你到底是要切到新的系统,还是继续往老的继续迁。中间这一层我做了控制以后,当然很多用户可能一开始的时候不愿意这样做微服务化改造,或者容器改造,原因就是因为怕影响我们的应用。但是我们做了这一层路由的切换灰度发布以后,你再新增出来一个新的应用,如果你挂了,大不了你路由我帮你切回去以前老的。所以这样子对于应用来说他其实是无感知的。
中间我们主要是用Nginx、Lua和redis来做的,redis主要是存一些配置信息,比如说我们正常的策略,比如你这个应用允许哪一个用户访问,后台对接到哪一些服务器,这些数据全部传到redis。Nginx里面的Lua的插件会往redis里面把这些所有的数据都读走,读走完了之后就可以做负载。中间这个地方我们做了一些很多像Nginx里面上用版本的功能,比如说像名信、健康保持等等非常多。还有一个比较大的特性,它能做到动态生效,就是动态路由,你不用重启Nginx,因为我所有的配置都在redis。比如说你现在新增了一个容器,我只需要把新增的容器的实验感知,最后把这个地址刷到redis上面去,Lua会自己把Nginx上面的数据拿过来,放到Nginx上面去,自动绘帮你做负载,这一块是完全无感知的,而且是全自动化的。
现在中间键在华为内部IT已经上线了260多位了,基本上华为内部IT所有的流量,大部分还是用现有的ESB来做的,所以我们中间要怎么做,策略还是比较简单一点的。平均的访问流量能够达到1亿次每天,但是1亿次每天跟我们正常的抢购,华为商城抢购的场景,这个流量还是有些不能比。因为像在企业内部里面,更多要求是它的可靠性,而不是一些访问流量非常大的,或者是防攻击、防牛这种的,相对要求会比较低一点,因为毕竟都是内部的客户。
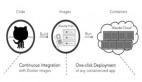
讲一下第二个需求,这个刚才有人提问到这个问题,我们这边是有一个应用的概念。刚才说了开发其实很多不想去解决你后台的问题,所以这个地方我们做了一个一键式应用发布的特性。一键式应用发布就是你应用开发或者是应用本身,你自己只需要做你的应用就行了,不用去管后台的。比如你拿一个java的万包(音)或者拿一个降包传给我,完事之后我会跟你做一些自动化构建,打成一个docker的容器镜像。这个镜像会发布到我们对应的,像测试或者是生产的镜像仓库上面去,做一层保留。到用户那边你可以选择部署,或者也可以选择用流水线的方式自动触发你构建的应用去自动部署到生产环境、测试环境,或者是开包环境。中间还有两个比较大的特性,一个是安全扫描,因为我们知道很多镜像,你在内部用户随便给你传了一个镜像,上面打了很多bug上去,或者上面有很多的病毒。这种中间我们会有一个安全中心,但是这个安全中心现在只能是扫描一些现有已经知道的漏洞库。
后面还有一个比较大的,就是全球的镜像同步,因为我的应用要部署到海外的BC上去。所以这个地方你必须在本地构建的镜像能够直接发到不同的数据中心。这个地方是用MQ来保证它的可靠的。中间正是做了这一层一键式应用发布,再加上流水线的结合,所以整个我们原有以前部署效率,以前我第一次申请资源的时候花了接近我5周的时间,到最后面我茶不5分钟,我的应用就可以完成,资源什么的直接是一键式就能申请下来的。
第二个需求刚才赵阳已经有讲过了,就是一个混合编排。我们在Kuberentes这边做了一个比较大的摆动,就是多增加了一个抽象概念,这块主要是为了兼容以前像进程的管理。比如以前大家都是软件包直接部署在虚拟机上面的,所以你这边可以创建pro在里面。一个pro里面可以管理很多进程,现在只支持一个。底下是可以支持容器、物理机、虚拟机上面的应用和部署。但是这个地方我们需要提供一个软件仓库的功能,因为我们的软件包全部都是统一放在一个地方的。
下面这个主要涉及到刚才讲到了webIDE,就可以通过拖拽的方式,整个部署一个环境,这个刚才已经讲过了,我就不讲了。再下来讲一下我们这种监控,我们知道你的虚拟机跟容器一旦量大上去以后,监控对于大家来说都非常的重要,而且也非常的慢。主要有几点问题,一点是正常我们底下采集端的能力有点问题,因为我们以前传统大家都觉得,可能把采集到的监控信息,包括日日信息,一股脑的直接往你的服务端算。但是你的服务端是没有办法去控制的,因为你的服务端那边不知道底下会有多少人给你刷,这是有点向客户端主动上报,所以这个会带来一些问题。
这个地方我们做了几层改造,第一层改造是它的采集端,采集端我们采用像普罗米修斯,能够兼容普罗米修斯,能够自动往每一台服务器上面拉的方式。就不是底下自己报给我的,当然报给我的方式在这里也是支持的,就是给用户提供更多的支持力度。这是第一个问题。第二个问题是大家以前旧的系统肯定都打了很多的azen,azen是非常麻烦的问题,因为你azen还要解决它的升级版本管理,很多的问题,包括你到时候可能azen要卸载,或者要更新,问题非常多。 我这边基于原本(28:17),去做了一个叫(24:21)的东西,就是可以管理你底下所有的azen,包括比如你监控的日志,还有一些部署的azen,所有的azen都按照一定的架构把它放到一起,升级更新管理这些统一由X-lind来管理。
还有一个是我们服务端的压力比较大,所以我们把服务端这一块的消息全部都扔到kafika上面去了,kafika这边你后台的服务端就变成可扩展的,你可以随便的读。读完之后,这边主要做几个处理,一个是存储,存储的话这边监控是用openTSDB,日志这一块主要还是用Hbes和ES,后台会做一些展示,展示这边主要还是对接这些数据库去拿数据。
后面还有一个是策略中心,因为我们要做告警和自预,所以你所有监控的信息最后都必须要报出来。而且这个地方大家会发现告警非常的多,因为这个地方只是做一个比较简单的告警。简单一点的告警就是正常预知的告警,到最后会到我们的大数据平台里面去做一些智能分析,就是把你整个告警聚合到一起,最后再形成一定的事件,去做自动扩缩容,或者是抬。
现在已经能承受到整个,因为我们现在容器的数量是非常大的,包括以前已有的虚拟机的方案,整个可以达到万级的级别,都是没有问题的。
这个是我们整个页面的展示情况,就是一些我们自有资源展示的页面,还有CPU内存。
再讲一下调度方面的,调度方面有做一些亲和和反亲和的,主要是跨数据中心的。在跨数据中心外会做一层,到单数据中心内部还会再做一层。数据中心内部做的这一层,主要是像以前的CPU余量和内存余量,主要是fusionstage它原生支持的。我们新增的几个比如说像镜像缓存,因为我们部署的时候要更快,所以一定是要先把它尽量往已有的镜像缓存的机器上面做调度。
再讲一下应用的灰度发布和弹性扩缩的事情。我们这边的扩缩容可以做到几点,一点是对接IaaS做扩缩容,一点是容器自己做的一层容器的扩缩容个。应用的升级基本上都是灰度升级,两种方式。一种是替换式的,比如说你多个版本,你先构建出一套新的版本,把路由接上,接完之后,再把老的版本全干掉。还有一种是滚动式的升级,就是你起来一个新的,干掉一个老的,你可以体验一下新的到底怎么样。然后再起来一个新的,再干掉一个老的,这个策略是可以垂直的。
这个地方还有几个我们对docker做的改造,刚才看了一下用docker的人比较少一点,我就简单掠过就好了。我们这个地方私人云场景里面会做一个类似于容器里面,你能跟传统的虚拟机一样,直接用sh登录下去,但是这一块不是用shd来做的。因为我们容器里面要打一些业务,还有监控之类的,所以它是多进程。日志的持久化是通过挂盘的方式存储到外面。还有一些docker可以设定独立的IP。包括hosd,容器会给它做一端口分配。
这是整个fusionstage云化改造完之后,能给传统IT带来多大的价值,虚拟机个数直接降下去了,但是容器的个数上去了,容器对于我们来说相对更容易一点运维一点。然后虚拟化成本降低了将近一半。还有一个是弹性时间现在可以到5分钱,以前真的是1周,我一开始过去申请的话就是1周。下面就是一个CBD还有一些跨站点的支持,这个对于我们来说产生的效力还是比较高的。
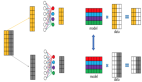
下来是几个遇到的问题。第一KBS原本的service性能会相对比较差一点,因为它每次去创建一个service的话,后台都会去创建4条Iptable,而且还是在每一个虚拟机上都会创建相应的Iptale。之前我们在线上的问题是1千个节点,600个service,4千个cord,所以导致我们后面每一台机器上面有1万8条的Iptale,更新一次需要接近5秒到10秒的时间,这个时间对于业务来说是不可忍受的。所以后来我们做了一层改造,这个也是在KBS上面改的,基于KBS我们做了一层端口的管理,也就是说把原有的service的方式尽量少用它,改成这种服务志发现的模式。在每一台机器上我做原有docker端口的管理,管理完之后我会把它对应的IP地址直接刷到容器里面。如果你应用在容器里面启动的话,你可以拿黄金变量,直接拿自己的IP和端口做服务发现,放到你自己的服务注册中心上面去,这样你所有的容器可以跟以前虚拟机的方案全部都打通了。因为你以前部署在虚拟机上面,所以容器这边变成我们用了它虚拟机上面这一层网络的影射。
第二个问题是我们遇到的也算比较大的问题,这一块是一个优化。大家不管你写代码写的多牛逼,到最后肯定会有一定的bug。或者你的OS太就没有启动了,没有重启了,也可能带来很多的问题。所以我们这里做了一个重启的特性,所谓的就是重启大法。你以前的那些操作系统很多,比如说要涉及到操作系统,要升级,或者你的容器都要升级。这个地方也是需要把虚机去重启一下的,所以我们这边做了一个试练场。以前像KBS这边我们会让它先把容器迁走,迁完之后,再把虚拟机重启掉。所以我们所有的机器一直是在重启的,这样能减少很多的问题。有时候代码跑久了,会有很多奇奇怪怪的问题,可能再牛的人也解决不了这样的问题。所以这层是我们做的一层运维上面的优化。
今天要讲的内容差不多就是这么多,下面是我们华为开发者社区的LOGO和我个人的二维码。如果有问题,后面要做交流的,也都可以加我的微信。我今天就讲这么多。
(结束)