













1.什么是A/B测试
A/B 测试,简单来说,就是为同一个目标制定两个方案,让一部分用户使用 A 方案,另一部分用户使用 B 方案,记录下用户的使用情况,看哪个方案的效果更好,以便全面推广。
A/B 测试在有的公司又称为小流量测试或者灰度发布,原因:
一 是为了统计新功能的效果;
二 是为了在全流量上线前修复可能出现的BUG。
虽然在业务上的含义有所差异,但是在系统设计上却是完全相通的。
2.A/B测试系统的模块
A/B测试有三个主要的功能模块:
一是用户分类
二是效果统计
三是流量分配
3.用户分类模块设计
用户分类是A/B测试的核心。
为了满足不同的业务场景,这里简述两种分类方案:
全用户抽样
这种分类方案的使用场景是新功能是针对全站的。而操作方法也很简单:(userId % X) < n。其中X是抽样的比例,例如按照1%抽样,那么X就等于100。而n是抽样的份数,这里有一个流量从小到大的过程,也就是n从1到X的过程。
按用户特质分类
这种分类的使用场景是新功能是针对某种特定用户的。比如我们针对大学生人群设计了一个新功能,如果采用全用户抽样,那么不是我们的特定用户的统计效果就会冲淡新功能的真实效果,导致统计结果趋于平淡,无法体现真实效果。这时候我们就需要针对特质人群来做抽样。
不同的分类方法模块设计也会不同,这里提出一种比较通用的用户分类模块设计方案:用户标签(tag)系统。
我们把用户的分类用tag来表示,属于某个分类的用户,就给他打上一个对应的tag。怎么找到某个分类的用户需要具体情况具体分析,这里就不深入了。我们需要建立一个用户tag存储模块,这个模块的功能非常简单,就是存取一个用户的tag。这个模块可以仅仅只是一个Redis服务器,也可以是一个数据库,还可以是一个RESTful Service。根据业务需要进行选择。
有了用户tag存储模块后,我们把我们需要抽样的用户打上一个tag,比如大学生。有时候为了更精确的统计效果,我们在统计的时候不是小流量和全流量对比,而是两个对照组对比,那么两个对照组都需要打上tag,比如大学生A,大学生B。有时候我们需要一个流量从小到大的过程,那么我们就把目标人群分成n份,打上不同的tag,比如大学生1…大学生n。这样在测试过程中,我们可以不断增加测试流量。
4.效果统计简述
有了tag系统后,效果统计模块就很好设计了。我们在出报表的时候,根据tag的不同,把用户对应的数据统计到不同的报表里,自然就可以出两组对比报表。至于具体需要统计哪些维度的哪些指标,这个就根据业务的需要来选择,此处暂且不表。
5.流量分配模块设计
流量分配模块针对不同的业务需要也有很多种设计方案,这里简单提几种:
从nginx分流
这种设计方案最简单。首先把不同的代码部署到两组服务器上面,各自独立,然后在nginx上面加载一个模块,根据用户的tag和流量分配规则,把流量转发到不同的服务器。这种方案的缺点很明显,对于小流量,如果上一台服务器就存在单点问题,上两台服务器又存在资源浪费问题,在两组服务器上面的压力会不均匀。以服务器作为最小分配单元粒度显得太大了。
通过配置文件或者硬编码的形式分配流量
这种方案由于对代码不透明,所以开发人员需要完全了解流量分配规则、完全跟进流量从小大到的变化等过程,而且要开发很多相关的代码,在流量完全上线后又要删除这些代码,造成人力资源浪费。
通过独立的模块进行流量分配控制,在业务代码里面通过注解的方式进行流量分配。
这种方案是我们推荐的设计方案,接下来会详细介绍这种设计。
在现代软件开发中,为了避免系统存在单点故障,各种软件都是作为分布式多机部署的。在多机部署的情况下,流量分配模块的数据同步问题就必须考虑。我们推荐采用zookeeper进行基本数据存储,而像用户标签则存储在另外的独立系统中。利用zookeeper的通知机制,我们可以动态的改变流量分配策略。
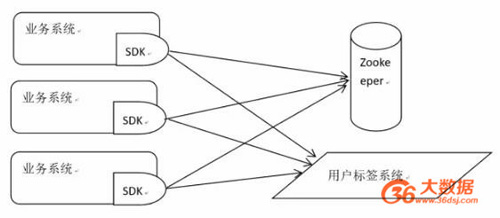
SDK依赖这两个存储系统来进行流量分配。Zookeeper里面存储采用何种策略来分配流量,而用户标签系统只存储用户的标签。业务系统集成SDK只需要在配置里面初始化SDK,然后在需要流量分配的方法上面写上注解就可以:
1)初始化SDK
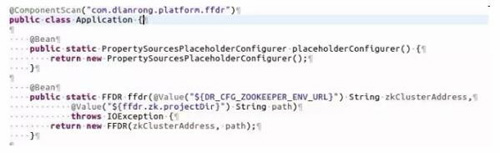
2)添加注解
我们目前支持两种注解级别:
一是类级别,也就是整个类里面的所有方法的调用都涉及到流量分配;
二是方法级别,就是只有这个方法的调用涉及到流量分配。
这里详细说一下方法级别的注解如何使用。
首先创建一个interface,当然也可以使用已有的interface:
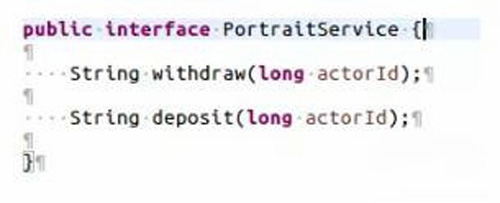
然后针对两种实现创建这个interface的两个实现类,***个是默认的实现类:

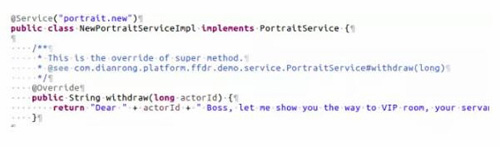
默认的实现类上面需要添加@Primary注解,表示这个是默认实现类。
在需要流量控制的方法上,添加@Switch注解,表示一个动态开关。featureUID表示这个开关的具体策略,alterBean表示开关打开之后需要调用这个bean上面的相应的方法。
接下来是我们第二个实现类:
***是调用这个方法的时候怎么传入环境参数:
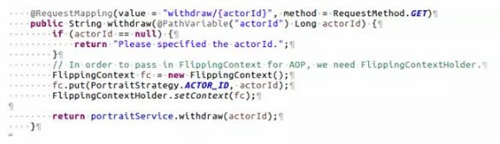
到这里SDK的集成就全部完成了。根据具体的策略和用户的tag,我们会选择正确的方法去执行。





















