有5年没有做报表取数了,但现在总是会想起取数的事,想到了现在还在欢乐运行着的自助取数系统,亲切的叫它”取数快点吧”,今天就来谈一谈这个系统 。

一、总体思路
在活字印刷出现以前,要印一本书很困难,需要根据书的内容刻成雕版,由于每本书的内容各不一样,需要为每本书单独刻成雕版,这样做既费事又费力。但是后来发现虽然每本书的内容千变万化,但是构成书的基本单元“字”是不变的,常用的中文字也就几千个,书无非是这些字的组合。后来毕昇发明的活字印刷术将每个字雕刻下来,形成活字,通过对活字的排版和组合来印刷书籍,大大提高了效率。
我们的临时统计取数需求也面临着同样的问题,每个需求千变万化,口径各不一样,BI人员需要为其单独开发代码,效率低下。但是通过仔细分析可以发现,虽然业务口径各不一样,但是业务口径基本上是客户信息、各种业务量、产品订购关系和各种费用等条件的组合,也就是说构成业务口径的基本单元是有限的,只要具备了这些基本能力,就可以通过对这些基本能力的组合来满足各种业务需求。
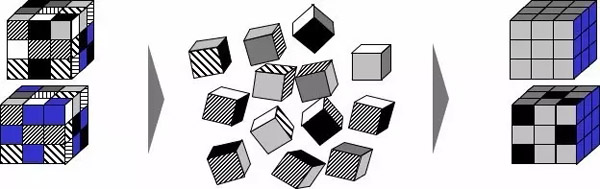
取数快点吧正是基于这样的思想,通过梳理出一系列原子的取数模型,每个取数模型对应一种基本的数据提取能力,然后采用向导式的、图形化的方式,通过对各个取数模型的组合来满足一个复杂的业务取数需求,改变过去依赖人工的方式,使得业务人员能够直接按需从数据仓库获取分析数据,包括以下几点:
- 构建统一取数模型库,丰富基础的、单元性的数据提供能力
- 打造向导式的数据机器人自助取数引擎,使得业务人员能够直接操作
- 实现灵活的自助分析,满足业务人员更深层次的统计分析需求
- 形成学习型的取数社区,通过不断的知识沉淀和共享来提升智能化数据提取能力
二、取数模型
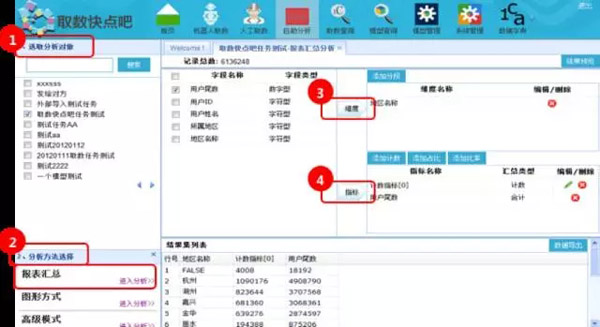
一个取数模型由三大部分组成,分别是数据模型、业务筛选条件和输出业务指标。数据模型对应于数据库中的一个或者多个物理实体表,业务筛选条件是在数据模型基础上定义的条件参数,输出业务指标定义了取数模型最终能够输出的结果信息。取数模型本质上是对数据模型的一种封装,业务筛选条件是数据模型的输入,输出业务指标则是数据模型的输出。
为了方便业务人员理解和使用,数据模型配置器中的“业务-数据转换配置”起到了数据向业务进行映射的作用,从而达到向业务人员隐藏技术细节,以业务语言进行展现的目的。以数据模型中的“套餐编号”这个属性为例,如果业务人员直接对“套餐编号”这个属性进行配置会觉得非常困难,而通过“业务-数据转换配置”可以将“套餐编号”重定义成“套餐类型”这个筛选条件,这个筛选条件下可以选择“动感校园套餐”、“动感社会套餐”等条件值,使得业务人员使用起来更为简单。
在构建模型库的过程中,为提升业务人员的可用性和易用性,遵循了如下原则:
可配置性原则:为了提高取数模型的灵活性,取数模型中的数据模型、业务筛选条件和输出业务指标均是可配置,可根据实际需求灵活调整,例如新增业务筛选条件等。
业务指标相近性原则:通过分析历史的需求,将经常需要同时获取的信息放在一个模型中,使得模型更符合业务人员的使用习惯,例如模型同时提供客户最近三个月的ARPU信息等。
筛选条件业务化原则:所有的筛选条件均需定义成业务人员可理解的形式,降低使用人员门槛。
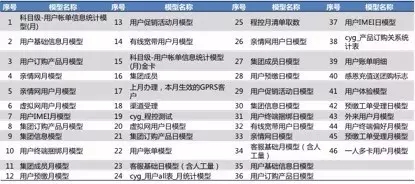
基于上述原则,对最近6个月的所有取数需求进行了分析和梳理,最终确定了近50个统一的取数模型,取数模型覆盖了业务人员常用的各种业务场景,以下是示例:
三、自助向导
如果说取数模型库解决了活字印刷术中制作活字问题的话,那么数据机器人引擎就用来解决对活字进行排版及印刷的问题。数据机器人引擎为业务人员提供了三个方面的核心能力:
- 提供了一个公用的取数模型展现和对其操作的平台:数据机器人就像一个容器,允许取数模型库中的所有模型在这个平台上进行展示,并向业务人员提供了一个友好的操作界面,可以按照业务人员能够理解的方式对取数模型进行操作。
- 提供了一个根据业务需求对取数模型进行自由组合的能力:单个取数模型的能力有限,无法满足一些复杂的业务需求,数据机器人允许业务人员对取数模型进行组合,从而具备了灵活应对各种业务需求的能力。
- 提供了一个将业务操作结果转化为技术语言并提供最终结果的能力:数据机器人中的SQL解析和执行器负责将业务人员对取数模型的操作转化成机器能够识别的SQL语言,并提交数据库执行,最终将得到的取数结果反馈给业务人员。
为了使得业务人员能够方便地完成自助取数,构建了一个向导式的、图形化的数据机器人引擎,通过自助数据机器人五步法即可快速地获取数据:
***步,基本信息填写:填写取数的基本信息,包括业务目的、业务口径等信息。
第二步,选取合适的取数模型:可以通过标签及搜索的方式从取数模型库中选取合适的模型。
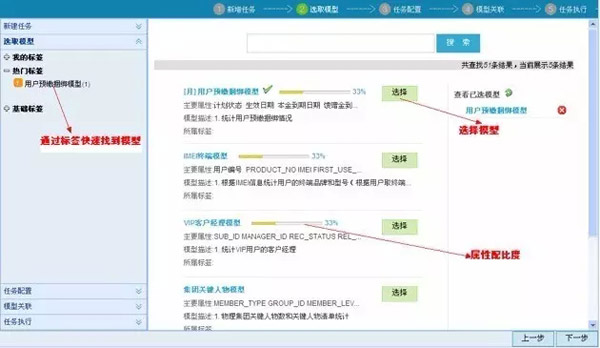
第三步,取数模型配置:对取数模型的配置主要包括三个方面,一是对模型输出结果的勾选,二是业务筛选条件的配置,三是外部数据的配置,允许导入外部数据,以及对取数结果进行特殊剔除等。
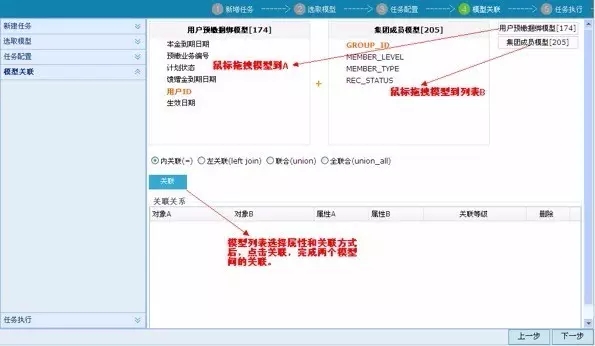
第四步,模型间组合(可选):选择两个以上的模型,可以通过拖拽的方式对模型进行自由组合。
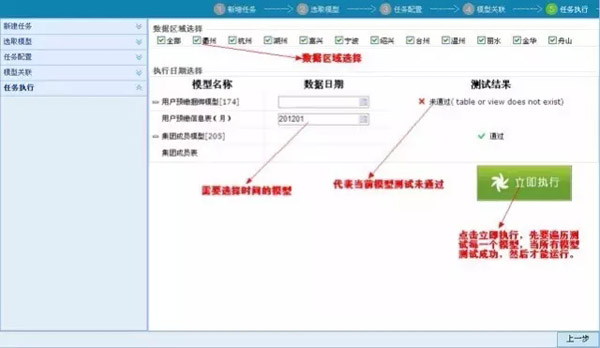
第五步,取数任务执行:配置完数据的地域和时间范围之后即可提交取数。
当然,除了可视化配置,SQL高级模式也必然是要支持的。
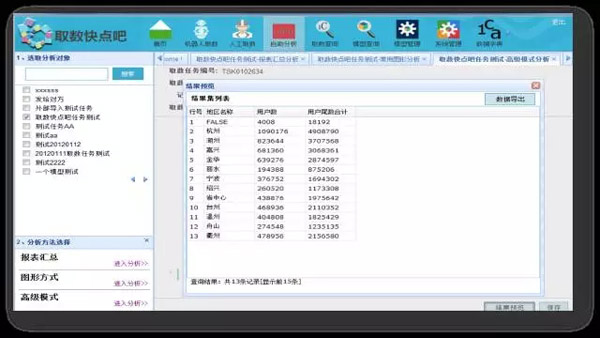
四、自助分析
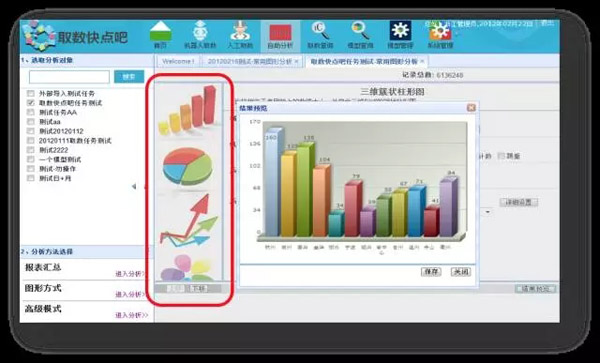
基于数据机器人自助取数结果,业务人员可以根据系统提供的自助分析功能进行灵活的、自由的分析,可以对结果按多个维度对指标进行汇总和分析,同时提供了图形分析和基础统计学分析能力,满足业务人员更深层次的分析需要。业务人员还可以将自助分析结果发布成周期性的统计报表,改变传统依靠技术人员手工开发报表的模式。
五、取数社区
取数快点吧同时是一个全省性的取数社区,大家的模型可以共享有无,系统对每次取数的业务口径、技术口径等信息进行了结构化,同时允许使用人员通过标签的方式对取数知识进行沉淀,以实现取数知识的全省共享。
六、效果情况
取数快点吧是一个相对比较简单的系统,但的确可以有效的提升取数效率,首先,人工取数量会下降,降幅达到30%左右,其次,业务人员潜在的需求得到释放,取数量增长了10倍,再次,取数需求的处理时间由原来人工方式的1-2天下降到30分钟左右 ,***,取数可配置化后,错误会降低,知识会有传承,这是实实在在的好处。
七、几点体会
BI自助取数系统是否建设依赖企业自身的情况,取数到达一定规模都可以考虑,但不是必须的,建设相对简单但运营困难,后续的优化迭代很重要。
BI自助取数系统适用场景是有限的,针对一线清单类取数需求最为合适,支撑的比例可以超过70%,探索类的复杂统计分析并不适用,但要相信一个企业主要的取数需求其实是非常简单的,要靠机器替代它。
这里提的方式对于很多企业并不适用,更好的方式肯定是教会业务人员写简单的代码+提供租户能力,那个才是真正的搭台唱戏,但这个又有赖于企业的数据文化。
BI自助取数系统要尽量开放,特别是模型一块,可以让一线自主导入或开发,建系统的是无法理解一线的奇思妙想的数据需求的。
BI自助取数的后台引擎如果是ORACLE啥的,可以考虑大数据解决方案了,关联一下要30分钟跟几秒钟那是几何级的差距,对于一线体验影响是巨大的。
BI自助取数是只是取数的一种方式,需要与人工取数协同,让用户有多种选择,抢占入口,这样流量总会有的,初期对于提升用户很重要。
这类系统前期***定制建设,因为跟业务强相关,没人持续的呵护肯定会死的,大家都懂得。
取数是BI最为重要的数据支撑手段,如果你从事取数相关工作,无论是新手还是老手,在疲惫的完成取数的时候,还是要留点时间给自己,想想有没有更好的支撑方法,这对于BI很重要。