随着京东业务的飞速发展, MySQL数据库的使用更加普及、服务器量级飞速增长,这对京东MySQL DBA团队的要求也越来越高。监控系统为数据库管理和维护提供了精确的数据依据,是数据库运维人员的千里眼和顺风耳。
准确、及时、有效的监控,能够使运维人员对生产服务系统运行情况了如指掌。通过分析获得的监控信息,判断被监控数据库的运行状态,对可能出现的问题进行预测,可以及时制定出适当的优化方案,从而保证整个系统正常、高效地运行。这也就在很大程度上保证了数据库的安全性,避免了一些不必要的损失。所以,我们有必要对Zabbix系统有更加深刻的认识和理解。
一、Zabbix功能简介
zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案。zabbix能监视各种网络参数,保证服务器系统的安全运营;并提供灵活的通知机制以让系统管理员快速定位/解决存在的各种问题。这是百度百科上对zabbix上的一段定义,市面上的监控软件很多,为什么选择zabbix呢?我们来看一下它的几个特点:
1、自动发现服务器和网络设备。
这功能有点鸡肋,在多种应用、多种设备混合场景下不实用,给zabbix整体运维管理带来不便。这在实际使用中也存在各种问题,特别是在设备种类繁多、数量较大的情况下,不建议使用这个功能,zabbix监控添加设备结合CMDB来完成,这样定位设备用途和添加模板将会更加准确;
2、底层自动发现。
这点很方便实用,比如自带的自动发现系统分区、自动发现多网卡等。这个功能也是可以自定义的,比如监控一台主机上的MySQL多实例服务,通过这个功能可以轻松搞定;
3、分布式的监控体系和集中式的web管理。
zabbix支持主动监控和被动监控模式(模式是相对于客户端来说的,主动推监控数据给服务器端或是服务器端来拉取监控数据。建议使用主动模式,以便减轻服务器端压力), 并且可以实现秒级监控,这点是一些监控软件达不到的,但对重要业务来说,这点很重要;
4、支持范围广。
支持监控多种设备以及目前市面常见的各种OS、服务、日志等,可以使用自带的agent监控,也有无agent监控等多种监控方法,如SNMP;
5、灵活的监控项设置。
zabbix本身已经支持很多常见的监控项,用户也可以自己写脚本来灵活自定义监控项,可以灵活组合多项报警阈值来准确报警,如监控硬盘的报警阈值可以设置为达到硬盘空间80%并且剩余空间低于50G时报警;
6、高水平的业务视图监控资源,监控情况展示方面可以垂直、水平对比展示。
比如一套数据库的分片,可以把所有主库的某个性能指标做在一个Graphs中,可以方便对比各个主库的负载情况是否均衡。也可以将多个Graphs做成一个Screens,然后在一个Screens中可以看到多种性能指标的各种情况,方便直观的进行对比;
7、灵活的用户权限设置。
支持自定义事件和邮件发送,也支持报警升级及日志审计;
8、基于zabbix报警的故障自愈。
Zabbix具有规范化的故障处理流程,对报警进行分级、分类,可以自动处理一些低级别、固化处理方法的故障,以达到快速恢复故障的效果。这点很重要,做的好可以***限度的保证业务的可用性稳定性,降低人为操作失误风险以及人员成本;
9、强悍的内置API。
几乎所有的zabbix服务器端web页面配置操作,都可以通过他自身的API来完成,用户可以非常方便地对它进行二次开发,以满足自己的自动化运维需求。
Zabbix***的一个缺点应该就是没有合并报警这个功能,在极端的情况下会出现报警风暴。不过很多监控软件应该也没有实现这个功能,用户可以通过对它进行二次开发,以实现合并报警的效果。
二、Zabbix的优化
有不少企业使用zabbix监控的设备数量达到一两百台,运行半年后性能极差,打开监控图需要很长时间,甚至打不开。这个问题比较常见,主要是因为没有对zabbix做到合理的规划和优化。如果能对zabbix做出合理的优化及架构上的规划,zabbix监控几万台设备还是很轻松的。
1、配置文件参数的优化
对于较大量级、海量设备的监控需要对zabbix相关参数进行调整,主要包含进程数量、缓存大小、超时时间三个方面,根据实际监控情况对zabbix自身的参数进行调整,禁用掉如VMware、Java等方面不使用的监控方式:
StartPollers=200
StartPollersUnreachable=100
StartTrappers=200
StartPingers=100
StartTimers=50
StartDBSyncers=100
Timeout=30
TrapperTimeout=30
StartProxyPollers=50
HistoryTextCacheSize=1024M
TrendCacheSize=1024M
HistoryCacheSize=1024M
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
2、监控项和报警项的优化
监控项越多,对zabbix数据库和它本身的性能的考验就越大。精简监控项,只监控必要的监控项,对运维没有帮助的监控项可以取消,以减少系统资源的浪费。最典型的一个MySQL监控模板,是网上比较流行的percona官方出品的zabbix监控模板,监控项高达200多个,基本囊括show global status中的所有项目,好多监控项对运维来说是没有意义的,却对数据库和zabbix自身性能产生严重的影响,当监控量级达到一定程度后,性能之差可想而知。
监控项的类型***使用数字,尽量避免使用字符。字符在数据库中的存储空间使用较大,在设置trigger时也相对麻烦,并且zabbix本身处理数字的效率要相对高。如果业务需要字符类型的监控项,可以适当的降低数据采集的时间间隔以提高处理效率。
Trigger中,正则表达式函数last(),nodata()的速度最快,min()、max()、avg()的速度最慢。在使用过程中,尽量选择速度较快的函数。配置Trigger时,也应注意使用正确的逻辑,错误的逻辑可能导致数据库查询较慢的现象。
3、zabbix数据库的优化
对数据库进行分区是必须要做的,这便于删除历史数据。同时要关闭zabbix自身删除历史数据的设置。如果不做分区和删除规则设置的话,随着时间的推移,zabbix本身查询和二次开发时查询性能都会变得很低,甚至查询不出数据。表分区的相关内容可以参考如下文件:https://www.zabbix.org/wiki/Docs/howto/mysql_partition。
关闭zabbix自身删除历史数据的设置SQL语句如下:
UPDATE config SET hk_events_trigger=60,hk_events_internal=60,
hk_events_discovery=60,hk_events_autoreg=60,hk_audit=60,hk_sessions=60,
hk_history=30,hk_history_mode=0,
hk_history_global=1,hk_trends_mode=0,
hk_trends_global=1,hk_trends=730,hk_services=60;
- 1.
- 2.
- 3.
- 4.
- 5.
在页面上设置位置为:
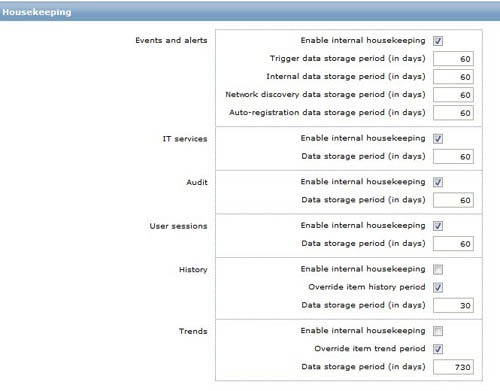
建议对历史表中时间字段添加索引,在二次开发时这个字段用到的几率比较大。建议对历史数据表启用innodb压缩,具体做法如下:
/*启用innodb压缩,设置历史表启用压缩*/
SET GLOBAL innodb_file_format='barracuda';
SET GLOBAL innodb_file_format_max='barracuda';
/*innodb_file_format和innodb_file_format_max要写入my.cnf配置文件中*/
ALTER TABLE history ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
ALTER TABLE history_log ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
ALTER TABLE history_str ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
ALTER TABLE history_str_sync ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
ALTER TABLE history_text ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
ALTER TABLE history_uint ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
ALTER TABLE history_uint_sync ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
ALTER TABLE history_str ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
ALTER TABLE history_uint_sync ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
ALTER TABLE trends ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
ALTER TABLE trends_uint ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
MySQL的版本建议使用PerconaDB5.6,设置thread_handling= pool-of-threads,启用线程池。MySQL配置文件其他参数的优化这里不多说,可以参考如链接中的配置文件:http://wangwei007.blog.51cto.com/68019/1623329。
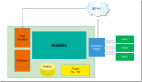
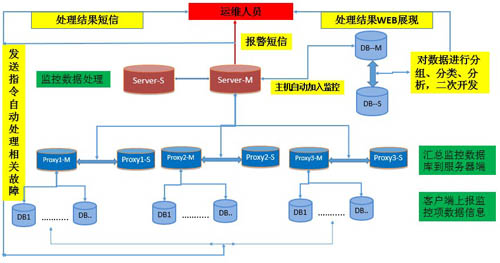
4、zabbix监控系统的架构优化
Zabbix架构的优化,主要原则是server端的压力分担到proxy端,proxy端的压力分担到agent端,监控项采用被动模式server端和proxy端均做高可用,防止单点造成监控不可用。以下是zabbix的架构和流程图,仅供参考:
三、Zabbix自动化
运维自动化的真谛在于解放、简化、方便运维人员的工作,提高效率,减少人为故障,基本运维思路是能自动坚决不手动,运维人员要培养自己“懒”这个好习惯。自动化的基础是基础信息的准确性和各种配置信息规则的规范化。
1、监控自动化规范
约定主机名规范,以期达到见名知意的效果,见到主机名大概知道这个设备是什么业务在使用,角色是什么。出问题时运维也可以快速的知道影响范围和影响的严重性,方便运维。主机规范一般可以包含机房信息、业务信息、业务登记、业务中的角色信息、IP等相关信息;
约定主机组的名字,这点主要是方便相同业务、相同研发查看自己主机的监控,接收报警信息,也方便zabbix本身做组图在screen中展现,做性能对比图。比如数据库的一个sharding集群,可以定义一个主机组,再做成Graphs汇总图时方便研发直观对比各个分片上的性能指标是否均衡;
报警等级的规范,这个主要是用于区分报警发给谁,怎么发,如何做报警升级等,还可以根据等级和监控项进行自动处理,等级较高的优先处理,较低的可以集中处理等;
主机维护暂停报警的规范。报警很重要,暂停监控需谨慎,不建议使用自带的Maintenance预维护,主要是因为处于维护状态的主机依然会显示在监控首页,虽然有标记,但是主机量大的时候不方便运维查看监控。建议进行二次开发,约定处于维护状态的主机关闭trigger,维护结束后自动打开;
不建议手动的修改主机监控的各种配置,这样容易遗忘,而且手工效率低下,容易造成各种设置和规则的混乱,后续问题堆积起来更加复杂,可维护性差。对zabbix进行二次开发时,配置的改动需要记录修改的原因,生效的时间段等信息;监控的增删改都自动完成,各种规范用程序来约束,由程序去自动完成。
2、部署配置的自动化
Zabbix的服务器端和客户端的部署较为简单,网上教程也比较多,把整个部署过程脚本化,然后和CMDB结合,自动批量部署和添加主机到监控中。部署过程可以参考此链接:http://wangwei007.blog.51cto.com/68019/1047953。
3、日常运维自动化
Zabbix自身提供了丰富的API接口,可以通过调用这些API,规范化操作配置zabbix。可以去http://www.zabbix.com/documentation.php查看各个版本的使用说明,包含zabbix的各种操作;
在API的说明中,也讲述了zabbix数据库中表的数据库字典,每个字段代表什么,都有详细说明。zabbix的二次开发和自动化运维主要是调用zabbix的API和读取zabbix的数据库来搞定的,不建议直接对zabbix数据库原表进行直写操作,一般也没有必要。大家可以参考一下这个python写的API:http://wangwei007.blog.51cto.com/68019/1139982。
4、报警的自动化处理
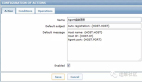
Zabbix可以在action中设置调用系统命令,在保证安全的情况下,可以使用这个功能来自动处理指定报警。设置如下图:
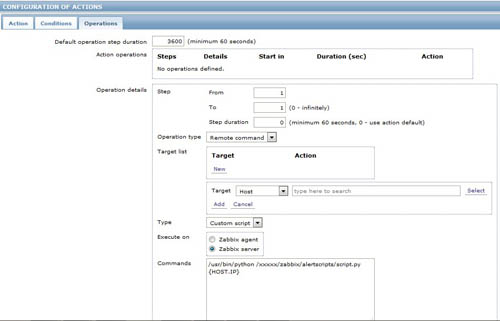
用户可以对常见的报警归纳总结,对一些固定处理方法的报警,把过程脚本化,当达到某个阈值的时候,自动的处理,比如清理固定位置的日志等,达到报警快速恢复的目的。
5、LLD的使用
Zabbix中的LLD是一个非常好的扩展,方便监控主机上多实例MySQL、Redis等服务、端口、硬盘多分区、多网卡等情况。用户可以自定义discovery rules,可以自动的生成指定items、triggers、graphs等,较为灵活,极大地方便了监控的运维。
6、zabbix的二次开发
Zabbix的二次开发主要是对监控数据的二次分析,可以***限度地发挥这些数据的作用,从而更好的服务和指导运维。
Zabbix的详细历史数据按照数据采集的类型存在于以下的表中:
history,history_log,history_str,history_str_sync,history_sync,history_text,history_uint,history_uint_sync,events
- 1.
zabbix的趋势数据存放在trends,trends_uint两张表中。趋势数据是通过详细的监控数据计算而来,每个监控项每个小时会产生最小值、***值和平均值。
利用这些历史数据,可以自动生成一些性能参数的统计汇总报表,比如某个性能指标压力较大的***00等,方便运维排查安全隐患。通过对对报警历史进行分析,可以找出经常报警的监控项,对可用性进行评估等。
***,感谢我们DBA团队老大樊健刚樊总对本文的指导和建议,同时也感谢他对MySQL监控这块一直以来的重视和支持。
【本文是51CTO专栏作者王伟的原创文章,转载请联系作者本人获取授权】