如果说奥巴马当年的连任证明了大数据的威力,那么特朗普的当选则戳破了当前大数据的短板。
2012年11月,奥巴马击败罗姆尼再次当选美国总统。其背后的功臣是奥巴马的数据挖掘团队,他们一直在搜集、分析和储存庞大的数据,从而为他制定了精准的广告购买决策,比罗姆尼少花了1亿美金的竞选资金。显然,大数据通过过程可视化达到了更为精准的营销。

但是,2016年12月,特朗普的当选却给了大数据一记重击。微软Bing以及有“数据巫师”之称的美国统计学家纳特·西尔弗(Nate Silver)通通预测失败,尽管拥有大数据意义上的高胜率,希拉里仍然在现实中败北。
是大数据根本不足以被采信,还是它到达了一个亟待升级的转捩点?
大数据的作用在于寻找规律
在互联网和大数据出现之前,我们通过经验来判断事务并采取行动。而经验在本质上,就是过去所积累的全部大数据在人脑中的反映。
受益于计算机的发明,我们对于数据的处理能力越来越强,处理速度也越来越快;紧接着,互联网的出现通过打破空间藩篱而提高了时间的利用率,我们对数据的搜索和收集变得无远弗届,数据广度与深度呈现裂变式增长。
这两大技术的发展将带来哪些变化?
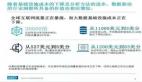
基于过去大数据收集与处理的下一步,就是帮助判断和预测未来,从而促进当下的行动。在这方面最典型的例子就是Google。作为全球***搜索引擎,Google拥有以太级别的数据和遍布全球的36个数据中心。比如:Google趋势图应用可以通过用户对于搜索词的关注度,很快发现和理解社会上的热点趋势。而Google Instant则会在用户输入关键词的过程中,迅速预测可能的搜索结果。据称,大数据为谷歌每天带来近2300万美元的收入。
那么,对于营销来说,大数据的价值又如何体现?
商业环境受制于诸多不可控的外部因素,宏观方面比如政策、经济大环境、社会文化等,微观层面则涉及行业走向、竞争对手、潜在替代者、消费者需求甚至企业内部管理等各方面。因此,商业对于大数据的依赖性更强。商业互联网化之后,提出的***个口号就是 Data Drive Business(数据驱动商业)。
就营销这一细分领域来说,大数据的价值更为明显。比如:如何发现消费者需求?如何圈定准确的目标受众?如何在正确的时间、正确的地点、以正确的方式传达给正确的消费者正确的内容?如何促使消费者行动?如何以销定产并实现柔性生产?如何设计制造***市场潜力的产品?如何提高营销的效率和投入产出比?……
要回答这些问题,就必须对涉及营销的整个过程甚至外部环境,都要有全面和透彻的了解。而大数据的作用就在于:通过结构化和非结构化的数据收集,将以往不可见不可描述的部分,变得可视化,从而通过分析处理来寻找规律、预测未来、帮助判断和采取行动。
毫无疑问,大数据的价值显而易见。但是,要想充分发挥大数据的威力,要做到两方面的***化:“对更加垂直化、细分化的小数据的纵深挖掘”以及“对更加广泛、甚至转瞬即逝的整体样本的全面覆盖”。
对更加垂直化、细分化的小数据的纵深挖掘
罗辑思维创始人罗振宇曾经说过这样一句话:“ 共享经济这件事其实遮盖了人类经济发展的总趋势。这个总趋势是不可逆的,叫分工再合作。”
技术的发展带动分工的细化,而分工的细化保证了每个环节的专业化。精细化分工如同一个个齿轮,带动整个机器不断自我进化。
在互联网领域也同样如此。跑马圈地的草莽时代在2016年渐渐谢幕,地推、并购等粗放增长方式呈现乏力迹象,互联网公司开始专心打磨产品,向纵深的垂直化和精细化运营进化。
各细分领域开始出现新的独角兽,比如一些小而美的app:美食生活类app Enjoy、精品短视频app Eyepetizer等,都拥有了一批忠实粉丝。
此外,诸如BAT这样的大平台也开始了精细化、垂直化的探索。而他们的追赶者们也在垂直化的路上走得更远一些。例如搜狗,除了常规的图片、视频、音乐等垂直搜索之外,搜狗结合自身技术特点,先后与腾讯、知乎、微软、丁香园等展开合作,推出微信搜索、知乎搜索、英文搜索、学术搜索、明医搜索等更加精细化、差异化的独家特色搜索产品,通过满足不同需求,增强用户黏性。
在垂直领域的深挖,使搜狗创造了一系列差异化、垂直化的产品,聚拢了拥有差异化需求的用户群体,根据这些用户在垂直产品上的多方网络行为,建立了行业标签、商业标签、人群属性标签、地理位置标签等完整的一套标签体系,进而提高大数据营销的精准度,帮助企业进行更加精准的投放。
对更加广泛、甚至转瞬即逝的整体样本的全面覆盖
目前,几乎所有大数据营销产品和服务都是基于数据集市(data mart)的概念。简单来说,它基于某一需求,定向搜集相关数据构成大数据样本库。好处是目的和方向比较明确,如同一个人先产生问题再去寻求答案一样;但缺点在于,这种收集方式会在前期遗漏部分有价值的数据,或者忽视掉一些转瞬即逝的数据——正因为目标明确,反而只见树木不见森林。
举个例子:如果利用大数据来进行用户画像,这就产生了一大问题:先入为主的定向切入,使用于用户画像的数据并不完善,从而会影响到分析的精度,进一步误导营销决策。
在特朗普大数据民调失误这一案例中,分析师就是在希拉里必胜新闻的刺激下,错估了形势,预设立场,通过先入为主的定向切入,忽视了特朗普在佛罗里达和其他摇摆州的巨大领先优势,从而在数据搜集上有意无意地遗漏了一些重要数据。大数据的蝴蝶在收集端挥了挥翅膀,结论端差之毫厘谬以千里。
正是因为注意到了这一问题,现在业内开始有人重新提起数据湖泊(data lake)的概念。
数据湖泊***出现在2011年Forbes杂志James Dixon所写的《大数据需要一个大的新型架构》一文中。与目标明确的数据集市不同,数据湖泊带来了更大的弹性。
简单地讲,数据湖泊倡导存储每一个可能有用的细节数据,把忽视的、遗漏的数据重新挖掘和存储起来,当需要时再进行一站式统一的、交叉的分析。这样做的好处是不遗漏任何有价值的数据,即使它非常微小、转瞬即逝、或当时看起来没有价值。
比如:在之前的大数据采集中,可能会漏掉潜在消费群的信息,忽略掉可能的销售机会。而尽可能采集更多更全面(哪怕是看起来不相关的数据,也可能内部存在一定的关联)的大数据,则有利于企业制定更精准的营销策略。
因此,数据湖泊的成立有赖于两个维度的拓展:上一节提到的垂直纵深数据的收集,以及更为广泛的全域数据的收集。
举个比较微观的例子:欧洲某大银行每年有650个直邮营销推广项目,发放将近6,000万封电子直邮,但是他们的营销效率却逐年下降。这家银行发现问题在于:虽然公司有不同的渠道接触客户,但是每个渠道都有自己的客户接触策略,这就造成客户资料和历史数据信息分散,没有形成客户关系的全貌。全域数据的缺失,使得公司无法根据客户特性来制定更为精准的个性化营销方案。
如今,媒介碎片化和人群移动化的趋势,使收集全域数据面临着新的挑战:如何收集移动数据?如何实现跨屏数据打通?如何搜集更多形式各异的非结构化数据?
对于***个问题,目前的解决方案一般是尽***可能覆盖更多的移动流量入口。再以搜狗搜索为例,不仅拥有移动端的QQ浏览器、搜狗浏览器、腾讯网、搜狐网等强势入口,2016年搜狗还与华为、三星、OPPO等大部分主流手机厂商达成合作。据悉,每天有超2亿台手机默认使用搜狗搜索。
在移动时代,人们不光在行为上呈现碎片化的特征,使用的设备也日趋丰富多元,这就带来了第二个问题:跨屏数据的收集。搜狗的无线端和PC端可以依托搜狗自有帐号体系、合作伙伴数据以及第三方数据,实现跨屏打通,进行无缝数据跟踪,在场景上将用户搜索、浏览和输入的跨屏数据进行融合,提供更有价值的投放依据。
目前,即使在非结构化数据的搜集上,也仅仅局限在文字、图片等简单表现形式上,但搜狗对于数据的搜集还跨越到了语音领域。2016年7月,搜狗推出知音引擎,不仅可以搜集语音数据,还可以进行理解和思考,进而提高语音识别准确率,再次丰富了数据搜集的类型。
更加细分的垂直化数据+跨屏多元化的全域数据,在源头上确保了数据的准确与全面;同时,借助人工智能日益增强的计算和分析能力,大数据将为企业决策提供更为精准的指引,使营销步入真正的智能时代。