IO调度发生在Linux内核的IO调度层。这个层次是针对Linux的整体IO层次体系来说的。从read()或者write()系统调用的角度来说,Linux整体IO体系可以分为七层,它们分别是:
- VFS层:虚拟文件系统层。由于内核要跟多种文件系统打交道,而每一种文件系统所实现的数据结构和相关方法都可能不尽相同,所以,内核抽象了这一层,专门用来适配各种文件系统,并对外提供统一操作接口。
- 文件系统层:不同的文件系统实现自己的操作过程,提供自己特有的特征,具体不多说了,大家愿意的话自己去看代码即可。
- 页缓存层:负责真对page的缓存。
- 通用块层:由于绝大多数情况的io操作是跟块设备打交道,所以Linux在此提供了一个类似vfs层的块设备操作抽象层。下层对接各种不同属性的块设备,对上提供统一的Block IO请求标准。
- IO调度层:因为绝大多数的块设备都是类似磁盘这样的设备,所以有必要根据这类设备的特点以及应用的不同特点来设置一些不同的调度算法和队列。以便在不同的应用环境下有针对性的提高磁盘的读写效率,这里就是大名鼎鼎的Linux电梯所起作用的地方。针对机械硬盘的各种调度方法就是在这实现的。
- 块设备驱动层:驱动层对外提供相对比较高级的设备操作接口,往往是C语言的,而下层对接设备本身的操作方法和规范。
- 块设备层:这层就是具体的物理设备了,定义了各种真对设备操作方法和规范。
有一个已经整理好的[Linux IO结构图],非常经典,一图胜千言:
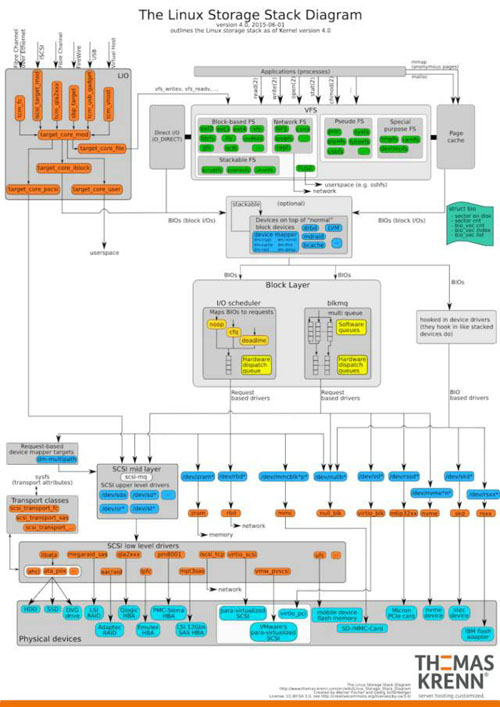
我们今天要研究的内容主要在IO调度这一层。
它要解决的核心问题是,如何提高块设备IO的整体性能?这一层也主要是针对机械硬盘结构而设计的。
众所周知,机械硬盘的存储介质是磁盘,磁头在盘片上移动进行磁道寻址,行为类似播放一张唱片。
这种结构的特点是,顺序访问时吞吐量较高,但是如果一旦对盘片有随机访问,那么大量的时间都会浪费在磁头的移动上,这时候就会导致每次IO的响应时间变长,极大的降低IO的响应速度。
磁头在盘片上寻道的操作,类似电梯调度,实际上在最开始的时期,Linux把这个算法命名为Linux电梯算法,即:
如果在寻道的过程中,能把顺序路过的相关磁道的数据请求都“顺便”处理掉,那么就可以在比较小影响响应速度的前提下,提高整体IO的吞吐量。
这就是我们为什么要设计IO调度算法的原因。
目前在内核中默认开启了三种算法/模式:noop,cfq和deadline。严格算应该是两种:
因为***种叫做noop,就是空操作调度算法,也就是没有任何调度操作,并不对io请求进行排序,仅仅做适当的io合并的一个fifo队列。
目前内核中默认的调度算法应该是cfq,叫做完全公平队列调度。这个调度算法人如其名,它试图给所有进程提供一个完全公平的IO操作环境。
请大家一定记住这个词语,cfq,完全公平队列调度,不然下文就没法看了。
cfq为每个进程创建一个同步IO调度队列,并默认以时间片和请求数限定的方式分配IO资源,以此保证每个进程的IO资源占用是公平的,cfq还实现了针对进程级别的优先级调度,这个我们后面会详细解释。
查看和修改IO调度算法的方法是:
![]()
cfq是通用服务器比较好的IO调度算法选择,对桌面用户也是比较好的选择。
但是对于很多IO压力较大的场景就并不是很适应,尤其是IO压力集中在某些进程上的场景。
因为这种场景我们需要更多的满足某个或者某几个进程的IO响应速度,而不是让所有的进程公平的使用IO,比如数据库应用。
deadline调度(最终期限调度)就是更适合上述场景的解决方案。deadline实现了四个队列:
其中两个分别处理正常read和write,按扇区号排序,进行正常io的合并处理以提高吞吐量。因为IO请求可能会集中在某些磁盘位置,这样会导致新来的请求一直被合并,可能会有其他磁盘位置的io请求被饿死。
另外两个处理超时read和write的队列,按请求创建时间排序,如果有超时的请求出现,就放进这两个队列,调度算法保证超时(达到最终期限时间)的队列中的请求会优先被处理,防止请求被饿死。
不久前,内核还是默认标配四种算法,还有一种叫做as的算法(Anticipatory scheduler),预测调度算法。一个高大上的名字,搞得我一度认为Linux内核都会算命了。
结果发现,无非是在基于deadline算法做io调度的之前等一小会时间,如果这段时间内有可以合并的io请求到来,就可以合并处理,提高deadline调度的在顺序读写情况下的数据吞吐量。
其实这根本不是啥预测,我觉得不如叫撞大运调度算法,当然这种策略在某些特定场景差效果不错。
但是在大多数场景下,这个调度不仅没有提高吞吐量,还降低了响应速度,所以内核干脆把它从默认配置里删除了。毕竟Linux的宗旨是实用,而我们也就不再这个调度算法上多费口舌了。
1、cfq:完全公平队列调度
cfq是内核默认选择的IO调度队列,它在桌面应用场景以及大多数常见应用场景下都是很好的选择。
如何实现一个所谓的完全公平队列(Completely Fair Queueing)?
首先我们要理解所谓的公平是对谁的公平?从操作系统的角度来说,产生操作行为的主体都是进程,所以这里的公平是针对每个进程而言的,我们要试图让进程可以公平的占用IO资源。
那么如何让进程公平的占用IO资源?我们需要先理解什么是IO资源。当我们衡量一个IO资源的时候,一般喜欢用的是两个单位,一个是数据读写的带宽,另一个是数据读写的IOPS。
带宽就是以时间为单位的读写数据量,比如,100Mbyte/s。而IOPS是以时间为单位的读写次数。在不同的读写情境下,这两个单位的表现可能不一样,但是可以确定的是,两个单位的任何一个达到了性能上限,都会成为IO的瓶颈。
从机械硬盘的结构考虑,如果读写是顺序读写,那么IO的表现是可以通过比较少的IOPS达到较大的带宽,因为可以合并很多IO,也可以通过预读等方式加速数据读取效率。
当IO的表现是偏向于随机读写的时候,那么IOPS就会变得更大,IO的请求的合并可能性下降,当每次io请求数据越少的时候,带宽表现就会越低。
从这里我们可以理解,针对进程的IO资源的主要表现形式有两个:进程在单位时间内提交的IO请求个数和进程占用IO的带宽。
其实无论哪个,都是跟进程分配的IO处理时间长度紧密相关的。
有时业务可以在较少IOPS的情况下占用较大带宽,另外一些则可能在较大IOPS的情况下占用较少带宽,所以对进程占用IO的时间进行调度才是相对最公平的。
即,我不管你是IOPS高还是带宽占用高,到了时间咱就换下一个进程处理,你爱咋样咋样。
所以,cfq就是试图给所有进程分配等同的块设备使用的时间片,进程在时间片内,可以将产生的IO请求提交给块设备进行处理,时间片结束,进程的请求将排进它自己的队列,等待下次调度的时候进行处理。这就是cfq的基本原理。
当然,现实生活中不可能有真正的“公平”,常见的应用场景下,我们很肯能需要人为的对进程的IO占用进行人为指定优先级,这就像对进程的CPU占用设置优先级的概念一样。
所以,除了针对时间片进行公平队列调度外,cfq还提供了优先级支持。每个进程都可以设置一个IO优先级,cfq会根据这个优先级的设置情况作为调度时的重要参考因素。
优先级首先分成三大类:RT、BE、IDLE,它们分别是实时(Real Time)、***效果(Best Try)和闲置(Idle)三个类别,对每个类别的IO,cfq都使用不同的策略进行处理。另外,RT和BE类别中,分别又再划分了8个子优先级实现更细节的QOS需求,而IDLE只有一个子优先级。
另外,我们都知道内核默认对存储的读写都是经过缓存(buffer/cache)的,在这种情况下,cfq是无法区分当前处理的请求是来自哪一个进程的。
只有在进程使用同步方式(sync read或者sync wirte)或者直接IO(Direct IO)方式进行读写的时候,cfq才能区分出IO请求来自哪个进程。
所以,除了针对每个进程实现的IO队列以外,还实现了一个公共的队列用来处理异步请求。
当前内核已经实现了针对IO资源的cgroup资源隔离,所以在以上体系的基础上,cfq也实现了针对cgroup的调度支持。关于cgroup的blkio功能的描述,请看我之前的文章Cgroup – Linux的IO资源隔离。
总的来说,cfq用了一系列的数据结构实现了以上所有复杂功能的支持,大家可以通过源代码看到其相关实现,文件在源代码目录下的block/cfq-iosched.c。
1.1 cfq设计原理
在此,我们对整体数据结构做一个简要描述:首先,cfq通过一个叫做cfq_data的数据结构维护了整个调度器流程。在一个支持了cgroup功能的cfq中,全部进程被分成了若干个contral group进行管理。
每个cgroup在cfq中都有一个cfq_group的结构进行描述,所有的cgroup都被作为一个调度对象放进一个红黑树中,并以vdisktime为key进行排序。
vdisktime这个时间纪录的是当前cgroup所占用的io时间,每次对cgroup进行调度时,总是通过红黑树选择当前vdisktime时间最少的cgroup进行处理,以保证所有cgroups之间的IO资源占用“公平”。
当然我们知道,cgroup是可以对blkio进行资源比例分配的,其作用原理就是,分配比例大的cgroup占用vdisktime时间增长较慢,分配比例小的vdisktime时间增长较快,快慢与分配比例成正比。
这样就做到了不同的cgroup分配的IO比例不一样,并且在cfq的角度看来依然是“公平“的。
选择好了需要处理的cgroup(cfq_group)之后,调度器需要决策选择下一步的service_tree。
service_tree这个数据结构对应的都是一系列的红黑树,主要目的是用来实现请求优先级分类的,就是RT、BE、IDLE的分类。每一个cfq_group都维护了7个service_trees,其定义如下:
![]()
其中service_tree_idle就是用来给IDLE类型的请求进行排队用的红黑树。
而上面二维数组,首先***个维度针对RT和BE分别各实现了一个数组,每一个数组中都维护了三个红黑树,分别对应三种不同子类型的请求,分别是:SYNC、SYNC_NOIDLE以及ASYNC。
我们可以认为SYNC相当于SYNC_IDLE并与SYNC_NOIDLE对应。idling是cfq在设计上为了尽量合并连续的IO请求以达到提高吞吐量的目的而加入的机制,我们可以理解为是一种“空转”等待机制。
空转是指,当一个队列处理一个请求结束后,会在发生调度之前空等一小会时间,如果下一个请求到来,则可以减少磁头寻址,继续处理顺序的IO请求。
为了实现这个功能,cfq在service_tree这层数据结构这实现了SYNC队列,如果请求是同步顺序请求,就入队这个service tree,如果请求是同步随机请求,则入队SYNC_NOIDLE队列,以判断下一个请求是否是顺序请求。
所有的异步写操作请求将入队ASYNC的service tree,并且针对这个队列没有空转等待机制。
此外,cfq还对SSD这样的硬盘有特殊调整,当cfq发现存储设备是一个ssd硬盘这样的队列深度更大的设备时,所有针对单独队列的空转都将不生效,所有的IO请求都将入队SYNC_NOIDLE这个service tree。
每一个service tree都对应了若干个cfq_queue队列,每个cfq_queue队列对应一个进程,这个我们后续再详细说明。
cfq_group还维护了一个在cgroup内部所有进程公用的异步IO请求队列,其结构如下:
![]()
异步请求也分成了RT、BE、IDLE这三类进行处理,每一类对应一个cfq_queue进行排队。
BE和RT也实现了优先级的支持,每一个类型有IOPRIO_BE_NR这么多个优先级,这个值定义为8,数组下标为0-7。
我们目前分析的内核代码版本为Linux 4.4,可以看出,从cfq的角度来说,已经可以实现异步IO的cgroup支持了,我们需要定义一下这里所谓异步IO的含义,它仅仅表示从内存的buffer/cache中的数据同步到硬盘的IO请求,而不是aio(man 7 aio)或者linux的native异步io以及libaio机制,实际上这些所谓的“异步”IO机制,在内核中都是同步实现的(本质上冯诺伊曼计算机没有真正的“异步”机制)。
我们在上面已经说明过,由于进程正常情况下都是将数据先写入buffer/cache,所以这种异步IO都是统一由cfq_group中的async请求队列处理的。
那么为什么在上面的service_tree中还要实现和一个ASYNC的类型呢?
这当然是为了支持区分进程的异步IO并使之可以“完全公平”做准备喽。
实际上在***的cgroup v2的blkio体系中,内核已经支持了针对buffer IO的cgroup限速支持,而以上这些可能容易混淆的一堆类型,都是在新的体系下需要用到的类型标记。
新体系的复杂度更高了,功能也更加强大,但是大家先不要着急,正式的cgroup v2体系,在Linux 4.5发布的时候会正式跟大家见面。
我们继续选择service_tree的过程,三种优先级类型的service_tree的选择就是根据类型的优先级来做选择的,RT优先级***,BE其次,IDLE***。就是说,RT里有,就会一直处理RT,RT没了再处理BE。
每个service_tree对应一个元素为cfq_queue排队的红黑树,而每个cfq_queue就是内核为进程(线程)创建的请求队列。
每一个cfq_queue都会维护一个rb_key的变量,这个变量实际上就是这个队列的IO服务时间(service time)。
这里还是通过红黑树找到service time时间最短的那个cfq_queue进行服务,以保证“完全公平”。
选择好了cfq_queue之后,就要开始处理这个队列里的IO请求了。这里的调度方式基本跟deadline类似。
cfq_queue会对进入队列的每一个请求进行两次入队,一个放进fifo中,另一个放进按访问扇区顺序作为key的红黑树中。
默认从红黑树中取请求进行处理,当请求的延时时间达到deadline时,就从红黑树中取等待时间最长的进行处理,以保证请求不被饿死。
这就是整个cfq的调度流程,当然其中还有很多细枝末节没有交代,比如合并处理以及顺序处理等等。
1.2 cfq的参数调整
理解整个调度流程有助于我们决策如何调整cfq的相关参数。所有cfq的可调参数都可以在/sys/class/block/sda/queue/iosched/目录下找到,当然,在你的系统上,请将sda替换为相应的磁盘名称。我们来看一下都有什么:

这些参数部分是跟机械硬盘磁头寻道方式有关的,如果其说明你看不懂,请先补充相关知识:
back_seek_max:磁头可以向后寻址的***范围,默认值为16M。
back_seek_penalty:向后寻址的惩罚系数。这个值是跟向前寻址进行比较的。
以上两个是为了防止磁头寻道发生抖动而导致寻址过慢而设置的。基本思路是这样,一个io请求到来的时候,cfq会根据其寻址位置预估一下其磁头寻道成本。
设置一个***值back_seek_max,对于请求所访问的扇区号在磁头后方的请求,只要寻址范围没有超过这个值,cfq会像向前寻址的请求一样处理它。
再设置一个评估成本的系数back_seek_penalty,相对于磁头向前寻址,向后寻址的距离为1/2(1/back_seek_penalty)时,cfq认为这两个请求寻址的代价是相同。
这两个参数实际上是cfq判断请求合并处理的条件限制,凡事复合这个条件的请求,都会尽量在本次请求处理的时候一起合并处理。
fifo_expire_async:设置异步请求的超时时间。
同步请求和异步请求是区分不同队列处理的,cfq在调度的时候一般情况都会优先处理同步请求,之后再处理异步请求,除非异步请求符合上述合并处理的条件限制范围内。
当本进程的队列被调度时,cfq会优先检查是否有异步请求超时,就是超过fifo_expire_async参数的限制。如果有,则优先发送一个超时的请求,其余请求仍然按照优先级以及扇区编号大小来处理。
fifo_expire_sync:这个参数跟上面的类似,区别是用来设置同步请求的超时时间。
slice_idle:参数设置了一个等待时间。这让cfq在切换cfq_queue或service tree的时候等待一段时间,目的是提高机械硬盘的吞吐量。
一般情况下,来自同一个cfq_queue或者service tree的IO请求的寻址局部性更好,所以这样可以减少磁盘的寻址次数。这个值在机械硬盘上默认为非零。
当然在固态硬盘或者硬RAID设备上设置这个值为非零会降低存储的效率,因为固态硬盘没有磁头寻址这个概念,所以在这样的设备上应该设置为0,关闭此功能。
group_idle:这个参数也跟上一个参数类似,区别是当cfq要切换cfq_group的时候会等待一段时间。
在cgroup的场景下,如果我们沿用slice_idle的方式,那么空转等待可能会在cgroup组内每个进程的cfq_queue切换时发生。
这样会如果这个进程一直有请求要处理的话,那么直到这个cgroup的配额被耗尽,同组中的其它进程也可能无法被调度到。这样会导致同组中的其它进程饿死而产生IO性能瓶颈。
在这种情况下,我们可以将slice_idle = 0而group_idle = 8。这样空转等待就是以cgroup为单位进行的,而不是以cfq_queue的进程为单位进行,以防止上述问题产生。
low_latency:这个是用来开启或关闭cfq的低延时(low latency)模式的开关。
当这个开关打开时,cfq将会根据target_latency的参数设置来对每一个进程的分片时间(slice time)进行重新计算。
这将有利于对吞吐量的公平(默认是对时间片分配的公平)。
关闭这个参数(设置为0)将忽略target_latency的值。这将使系统中的进程完全按照时间片方式进行IO资源分配。这个开关默认是打开的。
我们已经知道cfq设计上有“空转”(idling)这个概念,目的是为了可以让连续的读写操作尽可能多的合并处理,减少磁头的寻址操作以便增大吞吐量。
如果有进程总是很快的进行顺序读写,那么它将因为cfq的空转等待***率很高而导致其它需要处理IO的进程响应速度下降,如果另一个需要调度的进程不会发出大量顺序IO行为的话,系统中不同进程IO吞吐量的表现就会很不均衡。
就比如,系统内存的cache中有很多脏页要写回时,桌面又要打开一个浏览器进行操作,这时脏页写回的后台行为就很可能会大量***空转时间,而导致浏览器的小量IO一直等待,让用户感觉浏览器运行响应速度变慢。
这个low_latency主要是对这种情况进行优化的选项,当其打开时,系统会根据target_latency的配置对因为***空转而大量占用IO吞吐量的进程进行限制,以达到不同进程IO占用的吞吐量的相对均衡。这个开关比较合适在类似桌面应用的场景下打开。
target_latency:当low_latency的值为开启状态时,cfq将根据这个值重新计算每个进程分配的IO时间片长度。
quantum:这个参数用来设置每次从cfq_queue中处理多少个IO请求。在一个队列处理事件周期中,超过这个数字的IO请求将不会被处理。这个参数只对同步的请求有效。
slice_sync:当一个cfq_queue队列被调度处理时,它可以被分配的处理总时间是通过这个值来作为一个计算参数指定的。公式为:time_slice = slice_sync + (slice_sync/5 * (4 - prio))。这个参数对同步请求有效。
slice_async:这个值跟上一个类似,区别是对异步请求有效。
slice_async_rq:这个参数用来限制在一个slice的时间范围内,一个队列最多可以处理的异步请求个数。请求被处理的***个数还跟相关进程被设置的io优先级有关。
1.3 cfq的IOPS模式
我们已经知道,默认情况下cfq是以时间片方式支持的带优先级的调度来保证IO资源占用的公平。
高优先级的进程将得到更多的时间片长度,而低优先级的进程时间片相对较小。
当我们的存储是一个高速并且支持NCQ(原生指令队列)的设备的时候,我们***可以让其可以从多个cfq队列中处理多路的请求,以便提升NCQ的利用率。
此时使用时间片的分配方式分配资源就显得不合时宜了,因为基于时间片的分配,同一时刻最多能处理的请求队列只有一个。
这时,我们需要切换cfq的模式为IOPS模式。切换方式很简单,就是将slice_idle=0即可。内核会自动检测你的存储设备是否支持NCQ,如果支持的话cfq会自动切换为IOPS模式。
另外,在默认的基于优先级的时间片方式下,我们可以使用ionice命令来调整进程的IO优先级。进程默认分配的IO优先级是根据进程的nice值计算而来的,计算方法可以在man ionice中看到,这里不再废话。
2、deadline:最终期限调度
deadline调度算法相对cfq要简单很多。
其设计目标是:
在保证请求按照设备扇区的顺序进行访问的同时,兼顾其它请求不被饿死,要在一个最终期限前被调度到。
我们知道磁头对磁盘的寻道是可以进行顺序访问和随机访问的,因为寻道延时时间的关系,顺序访问时IO的吞吐量更大,随机访问的吞吐量小。
如果我们想为一个机械硬盘进行吞吐量优化的话,那么就可以让调度器按照尽量复合顺序访问的IO请求进行排序,之后请求以这样的顺序发送给硬盘,就可以使IO的吞吐量更大。
但是这样做也有另一个问题,就是如果此时出现了一个请求,它要访问的磁道离目前磁头所在磁道很远,应用的请求又大量集中在目前磁道附近。
导致大量请求一直会被合并和插队处理,而那个要访问比较远磁道的请求将因为一直不能被调度而饿死。
deadline就是这样一种调度器,能在保证IO***吞吐量的情况下,尽量使远端请求在一个期限内被调度而不被饿死的调度器。
2.1 deadline设计原理
为了实现上述目标,deadline调度器实现了两类队列,一类负责对请求按照访问扇区进行排序。这个队列使用红黑树组织,叫做sort_list。另一类对请求的访问时间进行排序。使用链表组织,叫做fifo_list。
由于读写请求的明显处理差异,在每一类队列中,又按请求的读写类型分别分了两个队列,就是说deadline调度器实际上有4个队列:
- 按照扇区访问顺序排序的读队列;
- 按照扇区访问顺序排序的写队列;
- 按照请求时间排序的读队列;
- 按照请求时间排序的写队列。
deadline之所以要对读写队列进行分离,是因为要实现读操作比写操作更高的优先级。
从应用的角度来看,读操作一般都是同步行为,就是说,读的时候程序一般都要等到数据返回后才能做下一步的处理。
而写操作的同步需求并不明显,一般程序都可以将数据写到缓存,之后由内核负责同步到存储上即可。
所以,对读操作进行优化可以明显的得到收益。当然,deadline在这样的情况下必然要对写操作会饿死的情况进行考虑,保证其不会被饿死。
deadline的入队很简单:当一个新的IO请求产生并进行了必要的合并操作之后,它在deadline调度器中会分别按照扇区顺序和请求产生时间分别入队sort_list和fifo_list。并再进一步根据请求的读写类型入队到相应的读或者写队列。
deadline的出队处理相对麻烦一点:
- 首先判断读队列是否为空,如果读队列不为空并且写队列没发生饥饿(starved < writes_starved)则处理读队列,否则处理写队列(第4部)。
- 进入读队列处理后,首先检查fifo_list中是否有超过最终期限(read_expire)的读请求,如果有则处理该请求以防止被饿死。
- 如果上一步为假,则处理顺序的读请求以增大吞吐。
- 如果第1部检查读队列为空或者写队列处于饥饿状态,那么应该处理写队列。其过程和读队列处理类似。
- 进入写队列处理后,首先检查fifo_list中是否有超过最终期限(write_expire)的写请求,如果有则处理该请求以防止被饿死。
- 如果上一步为假,则处理顺序的写请求以增大吞吐。
整个处理逻辑就是这样,简单总结其原则就是,读的优先级高于写,达到deadline时间的请求处理高于顺序处理。正常情况下保证顺序读写,保证吞吐量,有饥饿的情况下处理饥饿。
2.2 deadline的参数调整
deadline的可调参数相对较少,包括:
![]()
read_expire:读请求的超时时间设置,单位为ms。当一个读请求入队deadline的时候,其过期时间将被设置为当前时间+read_expire,并放倒fifo_list中进行排序。
write_expire:写请求的超时时间设置,单位为ms。功能根读请求类似。
fifo_batch:在顺序(sort_list)请求进行处理的时候,deadline将以batch为单位进行处理。
每一个batch处理的请求个数为这个参数所限制的个数。在一个batch处理的过程中,不会产生是否超时的检查,也就不会产生额外的磁盘寻道时间。
这个参数可以用来平衡顺序处理和饥饿时间的矛盾,当饥饿时间需要尽可能的符合预期的时候,我们可以调小这个值,以便尽可能多的检查是否有饥饿产生并及时处理。
增大这个值当然也会增大吞吐量,但是会导致处理饥饿请求的延时变长。
writes_starved:这个值是在上述deadline出队处理***步时做检查用的。用来判断当读队列不为空时,写队列的饥饿程度是否足够高,以时deadline放弃读请求的处理而处理写请求。
当检查存在有写请求的时候,deadline并不会立即对写请求进行处理,而是给相关数据结构中的starved进行累计。
如果这是***次检查到有写请求进行处理,那么这个计数就为1。如果此时writes_starved值为2,则我们认为此时饥饿程度还不足够高,所以继续处理读请求。
只有当starved >= writes_starved的时候,deadline才回去处理写请求。可以认为这个值是用来平衡deadline对读写请求处理优先级状态的,这个值越大,则写请求越被滞后处理,越小,写请求就越可以获得趋近于读请求的优先级。
front_merges:当一个新请求进入队列的时候,如果其请求的扇区距离当前扇区很近,那么它就是可以被合并处理的。
而这个合并可能有两种情况:
- 是向当前位置后合并
- 是向前合并。
在某些场景下,向前合并是不必要的,那么我们就可以通过这个参数关闭向前合并。默认deadline支持向前合并,设置为0关闭。
3、noop调度器
noop调度器是最简单的调度器。它本质上就是一个链表实现的fifo队列,并对请求进行简单的合并处理。调度器本身并没有提供任何可疑配置的参数。
4、各种调度器的应用场景选择
根据以上几种io调度算法的分析,我们应该能对各种调度算法的使用场景有一些大致的思路了。
从原理上看,cfq是一种比较通用的调度算法,它是一种以进程为出发点考虑的调度算法,保证大家尽量公平。
deadline是一种以提高机械硬盘吞吐量为思考出发点的调度算法,尽量保证在有io请求达到最终期限的时候进行调度。非常适合业务比较单一并且IO压力比较重的业务,比如数据库。
而noop呢?其实如果我们把我们的思考对象拓展到固态硬盘,那么你就会发现,无论cfq还是deadline,都是针对机械硬盘的结构进行的队列算法调整,而这种调整对于固态硬盘来说,完全没有意义。
对于固态硬盘来说,IO调度算法越复杂,额外要处理的逻辑就越多,效率就越低。
所以,固态硬盘这种场景下使用noop是***的,deadline次之,而cfq由于复杂度的原因,无疑效率***。
作者简介:
邹立巍
Linux系统技术专家。目前在腾讯SNG社交网络运营部 计算资源平台组,负责内部私有云平台的建设和架构规划设计。
曾任新浪动态应用平台系统架构师,负责微博、新浪博客等重点业务的内部私有云平台架构设计和运维管理工作。