VR的广泛传播对于数据视觉化具有着可算是屈指可数的地位并因VR发生了天翻地覆的改变。但重点是如何改变?现如今的数据视觉化又发生了哪些问题?这篇文章就此深挖传统视觉化所存在的问题和理解抽象信息中的困难以及VR如何使之改变。
Evan就任一家VR数据视觉化公司Kineviz的项目经理。曾作为数据科学家就职于HID Global,并且毕业于加利福利亚大学伯克利分校认知学。除了平时为Kineviz工作和探索VR之外,Evan还深醉于研究人类的决议过程。
在1983年,Amos Tversky 和 Daniel Kahneman问了大学生如下几个问题:
Linda是一个31岁坦率个性阳光的单身并学习哲学专业的女生。作为一名学生,她深切的关注歧视和社会司法所存在的问题并投身于反原子能游行中。这可能是因为:
1. Linda是名小学老师?
2. Linda在书店工作并参加瑜伽课?
3. Linda积极参与女权运动?
4. Linda是一名精神病院的社工?
5. Linda是妇女选民联盟的一员?
6. Linda是一名银行柜员?
7. Linda是保险销售员?
8. Linda是银行柜员并积极投身女权运动?
他们发现86%的大学生认为#8 (Linda是银行柜员并积极投身女权运动)比#6更有可能发生。虽然很容易联想Linda是支持女权且是一名柜员,但女权主义柜员仅是柜员中的一种,所以女权主义柜员的数量远少于所有柜员,(所以Linda是柜员的可能性还是应该大于她是女权主义柜员的可能性)。
不仅是这个例子非常有名,大多数人发现这让人困惑,然而视觉化让这一切一目了然简单易懂。
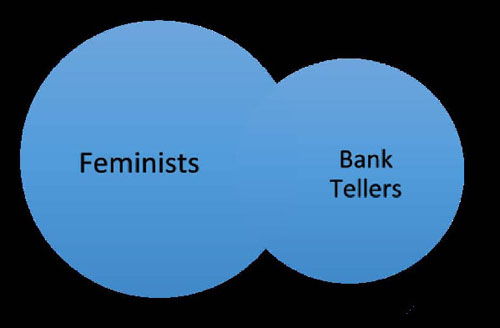
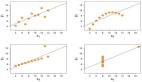
哪一个更有可能发生:Linda是一个银行柜员或女权主义柜员?假设圆圈大小与现实成比例。
虚拟现实使得概率推理变得异常简单,就如图表使得所谓的“Linda问题”变的简单。
谈及数据和虚拟现实的关系就如鸡与鸡蛋的问题-若不知道VR数据工具会被如何使用,组建一系列VR工具是相当困难的。虽然如此,虚拟现实能够有解决
a)概率思维(上述)
b)高维数据视觉化
c)高密度信息
d)提供场景便于透彻理解来龙去脉
高维数据视觉化
图像对于优质的统计分析至关重要- F.J. Anscombe
如果提供的数据集是两维或者更少,这数据相对容易用图像或者表格视觉化:
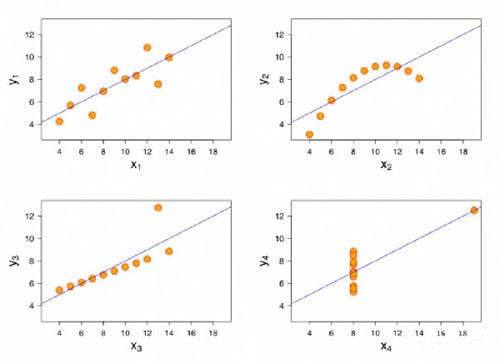
Anscombe的著名四重奏,取自维基百科。四个数据组有相同的平均值,相关性,方差和最优拟合线。
上述的每个数据集,所有X坐标的平均值都是9,Y坐标的平均值为7.5, X坐标的方差是11,X与Y的相关性是0.816, 且最优拟合线的公式是Y = 3 + 5x。
换句话说,这四组数据在统计上是完全一样的,视觉化把它们的真实特性被“出卖”。不过,这次当然轻松,因为我们要处理的只不过是二维的数据。
如果谈及三维数据,则需要使用三维图。如果想要演示更高维度的数据(比如说你的excel表格中有大量列)是不大可能的。想象二维图像当然容易,但当数据集中有很多列(比如10,000列,只要多于3列)问题就会来了,三维以上的视觉化是不可能的任务。
然而,还有其他方法诠释维度。 比如一个三角形,可以用于表现三维数据,如果每个维度对应着三角形的每一条边长。如果你愿意,甚至可以用红蓝光谱或者深浅光谱来为三角中心上色,这样就会有五个维度可供观察。对比每个三角形,你或者就可以发现异常或在此隐藏的规律和关系。当然,这只是个理论。
Herman Chernoff 在70年代探索了这理论的一个变种-有别于到三角形边长,他用不同的卡通人物的脸映射数据的维度。
以下我会让你判断L.A. 时代的信息图做的如何;
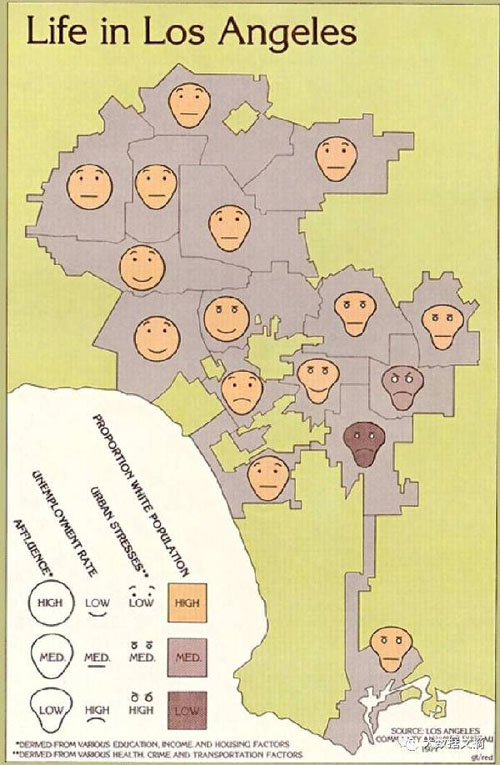
Eugne Turner -洛杉矶的生活 (1977),L.A. 时代。有四种面部维度,每个脸的地理分布和社区区块信息,这就意味这是一个有六个维度的数据。
你的本能反应对这个方法的数据表现嗤之以鼻,它们看起来可笑,带有一点种族歧视,和难以理解。 但我劝你不妨再尝试一次-能发现贫富社区间的缓冲带吗?
切尔诺夫脸谱图不能得到广泛利用的其中一个原因是它们太卡通了(科学通常都是严谨商业的,可能不太适合卡通脸谱图)。现实的切尔诺夫脸谱虽然可以解决太卡通的问题,他却存在另一个问题:貌似他们直观就可以理解,但我们对脸和情感太有经验,反而难以去评估编造的脸谱。
在下面的描绘中,Tim Cook 脸的参数-如眉毛的斜率-被用来映射Apple每年的财务数据多个问题点。

Christo Allegra的作品, Tim Cook 脸部的不同形态展现了每年Apple的财务数据不同的问题。他鼻子的宽度用来表现Apple贷款额;他嘴巴的开合度表现营业额;眼睛的大小表现每股收益等等。更多切尔诺夫脸谱图的应用,详见Dan Darling的成果。
很显然,这种方法也有一些问题。首当其冲的就是,脸部不是在任何情况都能传达同等程度的情感信息的,“笑”这个动作就是如此。换句话说,你对不同面部的感知的不同不能等同于实际数据的差值。这就是能够让图表如此有用的众多特质之一。这也是为什么用可视化的方法解决Linda问题会更加直观。这就是现今多维度的数据可视方法存在的缺陷。
虚拟现实技术可以解决上面所提及的众多问题。将面部取代,切尔诺夫类似的技术可以应用于控制中性对象观察、行动、交流和被分配。举例来说,下面所有桌子的属性能够被用来表示不同的数据维度:高度、桌面的面积、颜色、腿长、桌子磨光度以及斑点和焊补的位置和种类。如果你有15个维度的数据,你可以将维度转化成能够控制桌子外形的各种参数。

每一个测量值都会被用来可视化数据的另一个维度,来自mycarpentry.com
VR的优势就是能够让你感受到桌子真实、直观的意义,比方说它是另一张桌子的2倍高;抑或是桌面不同的摩擦系数。一些试验可以保证不同维度下相同的感知权重。
除此之外,相关的方法论已经在精神物理学和色彩感知领域得到了深度的研究---研究人员已经花费很多时间在测量人们如何通过不同的知觉感知微弱和巨大的差异。换句话说,VR和一些心理物理学能够使了解复杂的数据变得像走进宜家一样简单。
高密度图表
因为一些出现在数学历史中的不幸,那些由一堆点和连接组成的物体集同样也被称为图表。
这类的图表大致长这样:
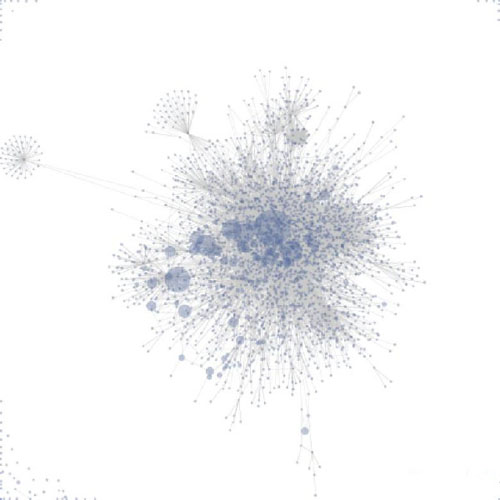
维基百科的Prefuse视觉图,来自维基百科
上面的每一个点表示一个维基页面,每一条线代表着页面之间的联系。
图表对于通过抽象的方法看见物体或者数据点有着重要意义,特别是当联系的类别和数量不可忽视的时候。
举例来说,下列的图表表示着在啤酒酵母细胞中基因间的每一次相互作用。
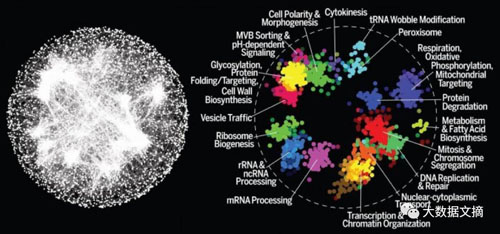
左:表示酵母基因组的节点和边缘图。右:重要的基因群。
尽管这个图表看起来很有意思,你肯定已经注意到2张图在中部都很密集。如果你去探索巴拿马的这个数据集,你会发现一些类似的事情发生---这个连接的图表会变得密集和迅速。
由于在图表中心重叠的连接的数量太多,图表会变得非常难以理解,同时这也会成为理解物体间相互关系的难题,而这又是使用图表的最初目的。
你可以想象,3D的图表的可视化不会显得如此复杂:
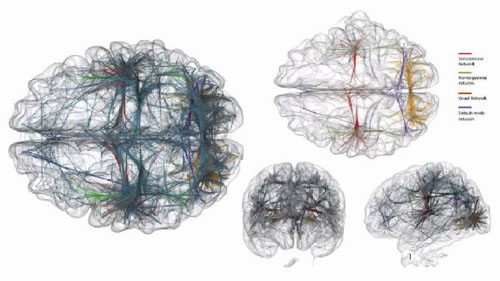
人脑中不同的相互连接的网络的3D可视化图表
然而,你需要注意这些可视化也会遭遇“混乱”的问题;尽管作者正用算法来将这些连接线“捆绑”在一起,搞清楚现实状况仍然很难。然而,想象一下,如果你能够飞进这些大脑的中心位置,并且可以迅速改变大脑的大小---数据就会更容易地解读了。
提供场景
比较下列的图表:

这俩个图表用的是相同的数据集。左边的图表被提名2015年年度最误导人的图表之一。
我承认,尽管上面的图表的表示很有误导性,但它至少因为是静态图形原因。如果能够改变数据的大小,形状和范围可以防止数据被误导,因为环境因素会直接影响体验。
用虚拟现实技术来可视化信息的最大优势是它能够分享不仅仅只是静态的VR展示;每一个VR的展示都是一次无意识的体验。这意味着观看者可以按照自己的意愿去探究它。
尽管VR数据工具仍然是处在初期阶段,但是我可以推荐你3个具备上述功能的工具。
CalcFlow
最开始我想介绍下CalcFlow,这个工具是由UCSD的数学系为了可视化3D数学概念时研发出来的。现在,它已经推出一些列具备互动性的演示,能够让人对二重积分或纳维尔-斯托克斯方程有直观的了解。在每个演示中,你可以体验到我之前所提到的一些VR功能:改变尺度并且在数据中间“穿行”,这也意味着数据会被更加容易解读。由于这个演示具备很强的操作性,用户可以在飞行中不断调整数据可视方式,探究这种改变如何影响多维度的图表。
DeathTools
DeathTools将数据可视化从抽象的数字带向一个真实、可触碰的世界,在这个世界不同于图形和表格,我们能够更加深入地理解数据。用这个工具可以看到近期中东冲突的累计尸体数量。不同于图表,你是真实地站在一行行装尸袋中间,这样可以准确地了解死亡的数量。
就如DeathTools的创建者Ali Eslami说:
我们的智慧所缺的就是运算大数的能力。我们很难去理解和接受大量的死亡。举例来说,像1;2;14;20;50这些是我们会经常碰到的数字,并且我们能通过我们自己内心记住的模型来理解它们。但是后来我们遇见如1000;10000;20000这样的数字。这些数字会变得越来越难用概念来衡量,但是我们仍然能够通过用可视化模型去理解这些数据的大致含义。
Kineviz
最后,Kineviz正在研发具VR功能的3D图形探索工具。这个工具被设计成用来解决高信息密度的问题,并非切能够让用户直接地体验数据意义上的不同。自己去看看吧:
VR的最主要的优势就是它能够被用来更容易地感知数据微妙的差别。除此之外,VR能够使数据表达更具操作性,意味着想要去改变数据表达来迎合一个特定的故事会越来越难。最终,一个人在VR中可以用他们空间意识来迅速改变能够让一个人去改变比范围,同时也允许那些以前难以想象的数据范围被感知到。