一拍而合,京东分布式存储起航
在项目中你经常会遇到,有一些图片、视频或者文本需要存储,你希望它不丢失的同时还要能提供高速读写的能力。对于京东来说,这样的需求每天都在发生着,而且要求会更高,因为这些可能是用户的订单数据,你希望即使在写的时候断电了、磁盘坏了,你的数据还在;你希望即使服务器故障了、交换机坏了甚至机房挂了,用户还能正常访问;你希望在大促来临时即使用户访问量倍级增长,它依然能提供高速读写。没错,现在很多人都会告诉你,用JFS京东文件系统,它能满足你的需求。
时间回到2013年,海锋哥刚来到京东,很快地他发现京东对存储有强烈的需求,既有海量小文件的在线存储,又有大量离线数据的存储,当前公司内部在这块做的并不好,各个业务部门自己做自己的,很多慢慢开始满足不了业务增长的需要了。一个想法油然而生,他决定做京东统一的分布式存储平台,满足公司各个业务线的需要。
有另外一个存储的小团队,成员只有6,7个人,虽然工作年限普遍不长,有几个还是刚毕业,但也都想着在存储方向做出一番业绩。同样的愿景,很快大家走到了一起。在海锋哥的领导下,系统技术部存储组正式成立,开始京东分布式存储的研发。
从2013年到2016年,这一做就是三年,当年的小鲜肉都成为了公司存储方向的中坚力量,成为了存储专家,而JFS也成为了京东业务核心底层存储,支撑了公司1000多个业务。一路走来,踩过很多坑,也有一些体会,给大家分享下。
艰难抉择,分布式存储技术选型
京东有各种各样的数据存储需求,有大小10KB的订单数据,每天以上亿的速度增长;有大小90k-200k的图片数据,总量超过几十亿,且每天还在以千万的速度增长;也有几十兆的App客户端文件,每次更新都伴随着巨量的用户访问;还有1GB甚至10GB以上的内部日志文件存储。各个业务部门使用的存储方式也五花八门,有用Mysql的Blob类型存储,也有用开源的FastDFS和Hdfs。诚然,这些软件在京东的快速发展中起了至关重要的作用,但随着业务规模的持续增长,也开始暴露出来了各种各样的问题。摆在我们面前的路有两条:一种是在开源系统的基础上做定制开发,还有一种是自研。两种方式各有优缺点,最终经过一轮轮调研下来,我们还是决定走自研之路。这里以大家熟知的Hdfs及其生态为例,回顾下当时抉择的过程。
毫无疑问,Hdfs是一个相当优秀的开源存储项目,但它毕竟是为离线大文件设计,对于京东海量的在线小文件无能为力,二次开发需要对整个架构动手术。还有一种考虑,使用Hdfs存储大文件,使用HBase存储小文件。当然,这种方案也不适合京东,主要有两点:***、HBase读取文件时,请求先打到RegionServer上,由RegionServer去Hdfs取数据,再返回,相当于一次IO请求经过了两次网络传输,这对于追求***速度的很多应用场景是不合适的;第二、HBase在做Split的时候会导致服务短暂的不可用,这对很多要求提供7*24小时无间断服务的业务则更是不可接受。
虽然自研的周期会更长,但它灵活可控,且从长期来看,也能获得技术收益。
日夜挑灯,JFS小文件存储
厨师到位,菜已洗净,接下来就是从哪里下手了。要做京东统一的分布式存储,这是一件非常困难的事情,因为即便是现在,也没有见到能同时很好的支持海量在线小文件和离线大文件的开源解决方案。很庆幸的是,当时我们并没有选择一步到位的***解决方案,而是紧扣业务,高度定制,分期展开这条路。
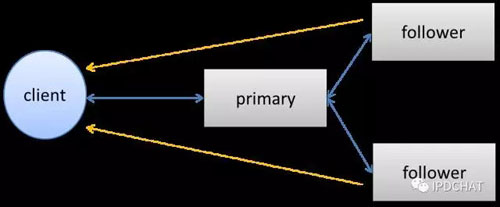
小文件存储则被选为了桌上的***道菜。无论是商品图片、交易订单,还是库房订单,这些电商数据都需要非常强的可靠性、可用性和一致性。在复制协议上,我们采取了三副本强一致性复制,由1Primary +2Followers构成,如下图所示。写操作时,由Client将数据发送到主上,然后由主同时发给两个从副本,三副本都写入成功后才返回给用户成功。而在读取时,优先在从上读取,来提高系统的并发能力。
在数据存储上,考虑到文件比较小,如果用户上传一个文件,对应在服务器上建一个文件存储数据的话,那么一块2T的盘上面将存放几千万甚至上亿个文件,给服务器带来沉重的负担。我们采取了事先建好大文件,然后不停的追加写入方式,使用偏移量和大小来访问数据。当然为了避免单个大文件集中读写造成文件锁资源竞争激烈,我们采取了多文件追加方式,如下图所示:
现在已记不清经过多少个日日夜夜的挑灯夜战,慢慢地加班餐的小姑娘因为熟识了,会有意给我们多舀一些菜;团队的年轻小伙伴白净的脸上多了一圈黑眼圈。终于,在4个月后的一天,我们迎来了***个孩子,京东小文件存储系统终于正式落地。当然,它也没令大家失望,在与同类的开源软件对比测试中,性能等各项指标都占优。
一个新系统的推广总是很艰难的,最初我们开始推广给在一些非核心业务的数据存储上,慢慢的应用起来。当然,我们也一直在准备着一条大鱼的到来。
小试牛刀,京东新图片系统
时间回到了2014年,老一些的员工可能还有印象,随着图片数据量和访问量的暴增,老的图片服务已经达到了性能瓶颈。客服每天都会收到大量用户投诉图片访问速度慢,IO异常、多副本数据不一致的情况也时有发生,告警邮件都快塞满了相关业务部门的邮箱。
老的图片系统最早可以追溯到好多年前,当时也是选择了一个业内使用广泛的开源存储方案。最初的一两年一直相安无事,但随着数据量的暴增,开始暴露各种各样的问题。最开始业务部门还能通过修改配置,加一些缓存策略来解决,到了后来,这些完全不起作用了,需要从整体存储架构上优化。
这时候的JFS在一些非核心的业务上获得了较好口碑,于是,图片的业务部门找到我们,希望能将图片业务迁移到JFS上来。
时间已经到了14年的4月份,离京东上市的日期也就一个月了。我们需要在JFS存储之上开发一个新的图片系统,还需要在不影响现有的业务情况下,完成20亿历史图片的迁移,这其中蕴藏的巨大风险大家都心知肚明,但并没有经过太多复杂的权衡,我们很快应允了下来。
再接下来就是一段与时间赛跑的历程,团队成员快速分工,几个同事用了一周的时间完成新图片系统搭建,同时另几个同事完成了数据双写、迁移和校验方案的实现,然后再用了三个星期完成了全部20亿存量数据迁移和校验。最终在公司上市前夕,完成了新老图片系统的切换,彻底解决了图片访问慢的问题。
京东的图片规格很多,同一副图片可能有10多种不同的规格,因此我们在源站只存一副原图,CDN没有***的图片回源站进行实时压缩,这样不仅节约了存储空间,也满足了业务不断变化的需求。如下图所示:
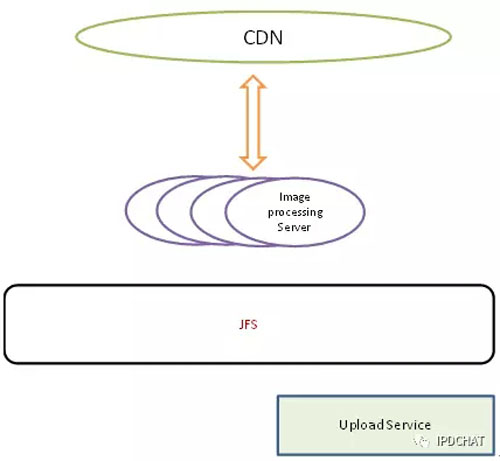
当然,在解决最核心的图片存储和简单图片处理后,我们也做了一些工作推动了京东图片技术的发展。在缩放效率上,我们和Intel进行了紧密合作,通过代码重构、ICC编译、IPP编译将图片缩放速度提升到最初的3倍以上。在2014年我们创新性的将图片Webp格式引入京东,与无线部门紧密合作,将移动端的图片全部替换成Webp格式。图片整体大小下降了50%,给CDN节约了30%的流量,也给用户节约了巨大的下行流量,让用户访问速度更快,大大提升了用户体验。
继续前行,JFS大文件存储
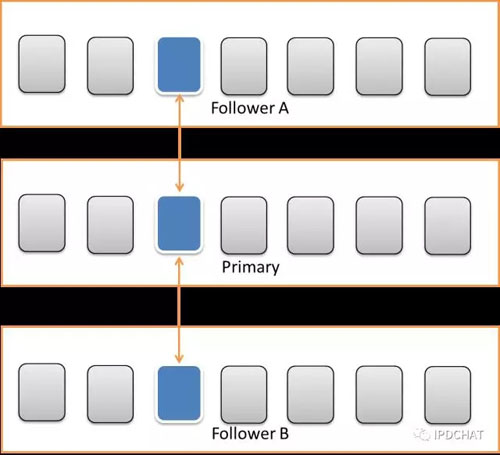
对于大文件来说,单客户端的上传和下载性能同样是一个重要的指标。小文件的复制协议1Primary+2Followers方式已不再是***的,Primary拿到数据后同时发送给两个从副本,这样,Primary的带宽资源将成为系统的瓶颈。因此,在大文件存储复制协议的选择上,JFS采取了链式复制来***限度利用系统的带宽资源。链式复制结构如下图所示。而在数据发送和接受上,我们使用了流式处理,大大提高大文件的传输效率。

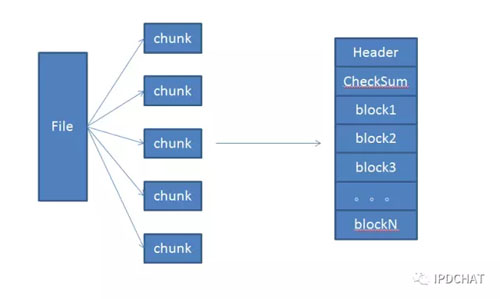
在数据存储上,恰恰与小文件相反,我们将一个大文件分成多个块来存储,这样可以规避局部过热的文件造成了单机磁盘IO过载,同时,分成多块后也更利于整个系统资源的调度。
快速发展,京东对象存储
前面的小文件存储和大文件存储,从可靠性、可用性和稳定性方面,已经满足了大部分的业务需求,但使用起来不是很方便,上传和下载都需要通过SDK,用户排查问题不是那么便捷,且对多语言的支持也不好。接下来我们瞄准了亚马逊的S3产品形态。
简单对象存储,支持Http协议;支持文本、图片、视频等任何类型数据的存储;支持1个字节到1TB大小的数据存储;支持list操作,用户数据可以有层次结构。这对于业务场景众多、应用复杂的京东来说,太合适了。
于是,我们决定在JFS上面构建对象存储,提供用户更便捷的访问。
对象存储包含几个部分,除了前面我们已经提到的大小文件存储,还需要构建Gateway、账户和Bucket管理、日志处理等等,当然还有最复杂的元数据管理。
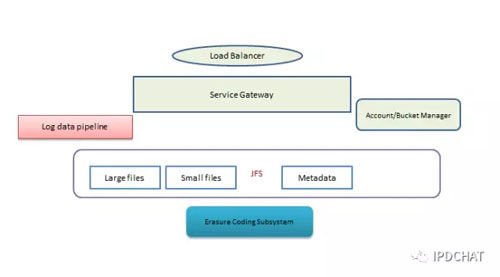
对象存储的元数据管理是一个业内难题。虽然对象存储并无目录的概念,但要支持按前缀进行List操作,即能通过Prefix和Delimiter的结合,实现层次查询。在数据量不大时,类似于Hdfs的NameNode将全部用户Key都存在内存中就能满足需求,但当对象的数量过亿或者十亿时,将会耗尽内存,无法做到横向扩展。很多KV存储能做到随意横向扩展,但不能很好的支持对象存储List请求。
我们的方案也不是一个***的解决方案,但已经能满足京东百亿级别元数据管理,这里发出来供大家探讨下。我们采取Mysql+Jimdb(京东自研的高速KV缓存系统),将元数据扁平化持久存储在Mysql中,同时借助于Mysql的B树结构实现元数据的List层次查询。使用Jimdb作为缓存,提供高并发能力。当然,仅仅Mysql并不能做到***横向扩展,我们在Mysql之上做了一个自动分库分表的系统ET,能在不影响业务的情况下,实现Mysql的分裂和数据在线迁移。如下图所示:
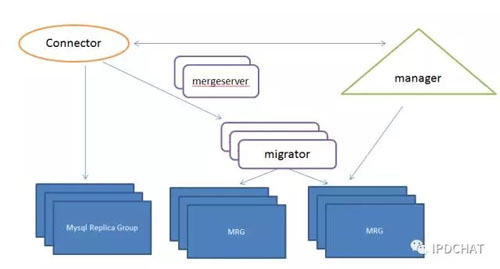
正常情况下,Client直接连到对应的Mysql复制组。当某组Mysql记录数目达到一定限度后,Manager触发分裂,启动一个Migrator作为Mysql代理,和Manager紧密配合完成实时数据处理和历史数据迁移。
对象存储一经推出就受到业务部门的广泛欢迎,目前已经支持了京东1200多个业务数据的存储,双十一***峰值每秒同时25000个对象实时读写,存储的对象达到百亿级别,数据量超过10PB。
持续创新,电子签收后台系统
电子签收小票的存储就是对象存储的一个重要应用。
京东一天的订单量就有成百上千万,以前每天都要保留几百万张的纸质小票,堆积在仓库里面。出现纠纷时,还需要从上亿张纸质小票中找到用户当时签收的小票,这无疑是一项繁琐、费时费钱、又不环保的工作,且大大提升了京东物流的管理成本。从环保维度和成本维度考量,运营系统青龙研发部创新性的提出了使用电子签收。
整个电子签收产生的海量签名图片需要高安全性、高稳定性、高持久性的保存。且根据国家的快递管理办法规定,物流的签收保存是一年,再加上签收的金融小票,意味着系统需要能够存储百亿级别的用户签收图片。海量的数据存储也给青龙研发带来了一些困难。
这无疑是对象存储很好的一个应用场景,但其定制化的加解密、文字转图片、图片合成也给对象存储提出了更高的要求。为了更好的支持业务创新,我们在对象存储的基础上,研发了电子签收后台系统。能够根据传回来的签收信息,按照指定样式生成签收小票图片,并与用户签名图片合成;按照业务高安全性要求,加密存储数据,保护用户数据的绝对安全;对经POS机加密传回来的数据,在用户查看时解密展示给用户。
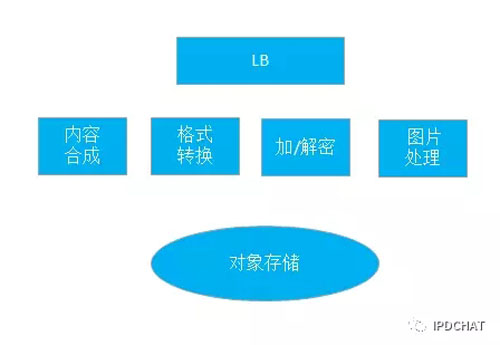
初衷未改,JFS统一存储
JFS小文件和大文件存储的实现,已经能够解决京东大量应用场景。但离我们的One team,One storage的愿景还很远。接下来我们开始了小文件和大文件存储的整合。同样的三副本强一致性复制,在复制协议上,我们进行了统一,同时兼顾到小文件和大文件性能,采取了链式复制。而在文件存储上,大小文件处理迥异,无法强行统一起来,因此我们将大小文件存储作为可插拔的不同存储引擎,分管集群中不同类型文件的存储。
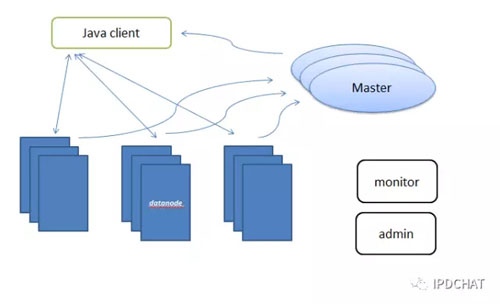
面向未来,京东分布式存储展望
对于未来,我们也在规划着让JFS支持共享存储,可以直接挂载在容器上。这样,应用的非结构化数据直接存到了分布式存储上,减少了日志等数据先存在本地磁盘,再收集到分布式存储上的环节。同时,和容器技术的结合更紧密,也支持了容器故障的快速调度和转移。
【本文来自51CTO专栏作者张开涛的微信公众号(开涛的博客),公众号id: kaitao-1234567】