1. 大数据安全现状分析
基于Hadoop生态系统的大数据平台随着企业的不断采用及开源组织的持续的优化、增强,已逐渐成为大数据平台建设的标准产品。然而Hadoop最初的设计并未考虑其安全性,这些平台专注于发展数据处理能力,忽视了其他能力的发展,但Hadoop生态系统作为一个分布式系统,承载了丰富的应用,集中了海量的数据,如何管理和保护这些数据充满了挑战,当前市场上,大数据平台在数据本身的安全管控方面普遍存在严重缺失和较大的漏洞。
从企业内部来说,大数据平台的安全管控能力缺失,使得平台在数据存储、处理以及使用等各环节造成数据泄露的风险较大,安全风险面广,且缺乏有效的处理机制;另一方面,企业敏感数据的所有权和使用权缺乏明确界定和管理,可能造成用户隐私信息的泄露和企业内部数据的泄露,直接造成企业声誉和经济的双重损失。
2. 方案目标
(1)针对大数据敏感数据信息,设计并落实敏感数据安全解决方案,实现敏感数据的模糊化,确保敏感数据信息安全可靠;
(2)通过大数据平台安全方案的建设,填补大数据平台数据安全防护方面的空缺,有效降低大数据安全管控方面的风险。
3. 大数据脱敏方案
本方案适用于基于开源Hadoop架构的大数据平台环境,包括Mapreduce、HDFS、Hive、HBse等大数据组件。
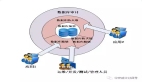
3.1大数据脱敏设计架构
大数据平台脱敏及模糊化模块主要包括两大功能:敏感数据发现和敏感数据脱敏。架构设计如下图所示:
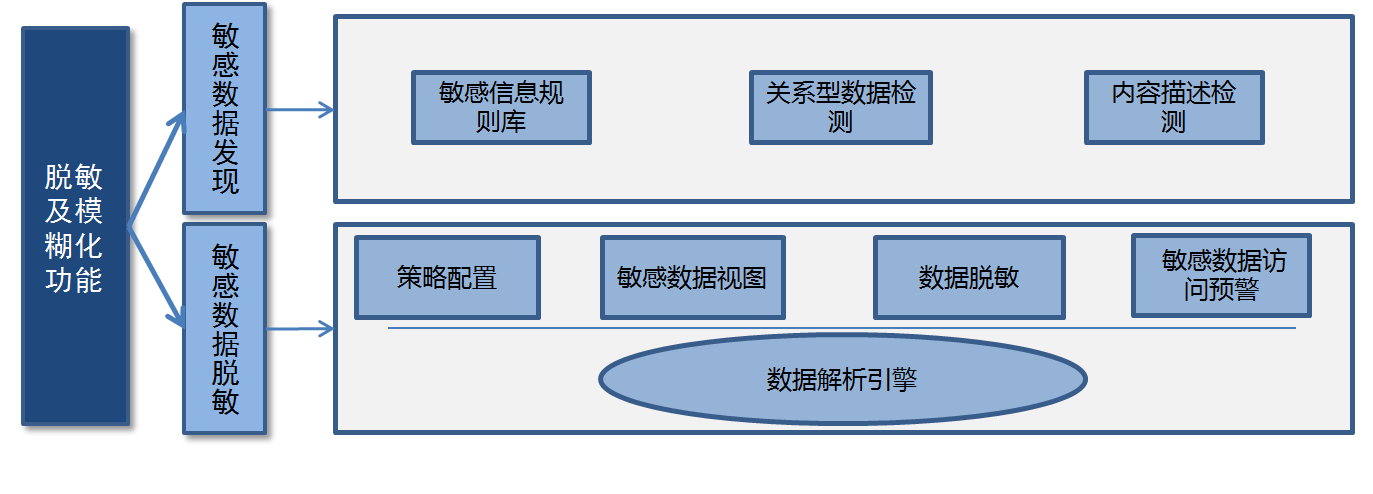
(1)敏感数据发现:通过设置敏感数据发现策略,平台自动识别敏感数据,发现敏感数据后产生报警,保障数据在产生阶段安全。敏感数据发现功能包括如下内容:
- 敏感信息规则库建立
- 关系型数据检测
- 敏感内容描述检测
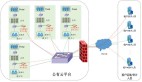
(2)敏感数据脱敏:针对Hadoop平台Hive、Hbase大数据存储组件结合用户权限提供动态数据脱敏功能,保障敏感数据访问安全,同时基于大数据安全分析技术,发现敏感数据访问的异常行为,并提供敏感数据视图,实现全局化数据管理和对各种类别敏感数据脱敏的精细化管理。
数据脱敏及模糊化功能模块是在数据库层面对数据进行屏蔽、加密、隐藏、审计或封锁访问途径的方式。该模块作为一个网关形式部署,所有需要进行敏感数据动态脱敏的应用系统需通过该产品实现对数据库的访问。
3.3大数据脱敏方法
数据脱敏方法可根据用户需求的不同而进行定制,我们在系统中默认提供了最常见的两种脱敏方法示例如下:
- 方法一:随机值替换脱敏
本方式采用随机值替换(字母变为随机字母,数字变为随机数字)的方式来改变查询返回的结果,该方案的优点是可以在一定程度上保留数据的格式,且用户在不知情的情况下无法发现查询返回的数据是经过脱敏操作的。
- 方法二:特殊字符替换脱敏
与随机值替换不同,该方式在处理待脱敏的数据时是采用特殊字符(如“*”)替换的方式,该方式更好的隐藏敏感数据,但缺点是用户无法得知原数据的格式,在涉及到一些数据统计工作的时候会有影响。
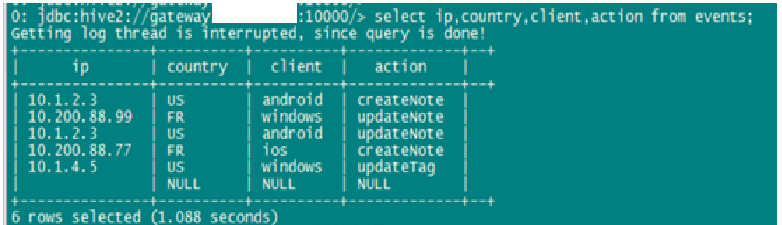
在实际使用过程中,多种脱敏方法经常需要配合使用,对一张数据表中不同资源使用不同的脱敏方法进行数据脱敏,示例如下:
脱敏前:
脱敏后:
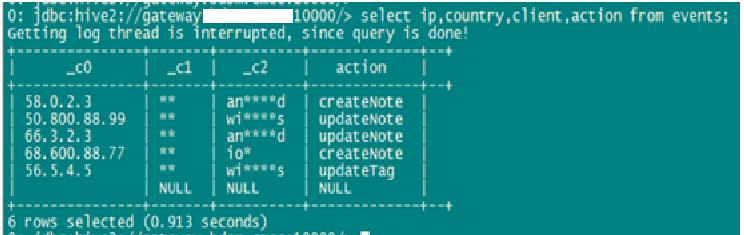
在这个示例中,我们对此表的三个字段分别用不同的脱敏方法进行了处理:
***个字段采用随机数替换,替换范围为前IP地址前两个值。
第二个字段采用特殊字符替换,替换范围为所有字符。
第三个字段采用特殊字符替换,替换范围为第3-6个字符。