本文主要谈及大数据系统如何做系统迭代,以及大规模系统因为其大规模没有可能搭建对等的测试环境,需要进行在线测试方面的内容,更有在线测试需要的必要条件等等。
阿里巴巴大数据计算平台需要每天不间断的跑在上万台机器集群上,上面承担阿里核心分析计算任务,有着很高的可靠性和SLA的要求,但是我们同时需要持续不断提高系统的性能,降低成本,提供更多功能来满足日益增长的业务需求,这样就要求持续不断的升级正在服务的系统。如何能够保证系统迭代中系统的高可用性对于阿里大数据计算平台是个很大的挑战。本次我们主要分享在大规模计算平台中发布迭代中挑战和阿里在MaxCompute系统中的解决方案。
MaxCompute
MaxCompute(大数据计算服务)是一种快速、完全托管的PB/EB级数据仓库解决方案,具备万台服务器扩展能力和跨地域容灾能力,是阿里巴巴内部核心大数据平台,支撑每日***作业规模。MaxCompute向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有效降低企业成本,并保障数据安全。
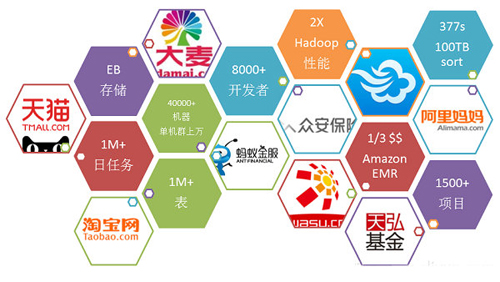
整个系统存储几百个EP的数据,每天处理***的任务量,具备上万台单集群,具有多集群跨地域的规模。我们内部有8000多个开发数据工程师,在这个平台上进行数据开发,性能上我们做社区的两倍,成本是Amazon的三分之一。
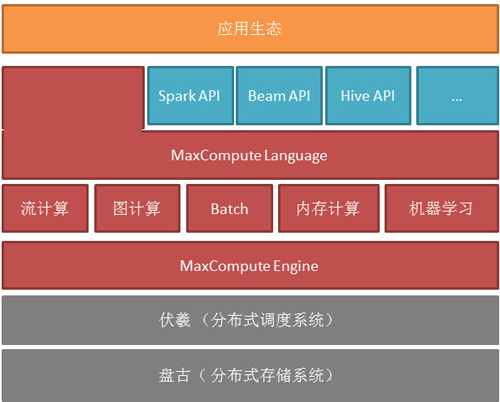
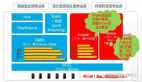
MaxCompute整体架构如图所示,最下层为分布式的存储系统和调度系统来统一的管理所有集群的资源,包括CPU、内存磁盘,在此上有一层执行引擎来支撑不同种的运算方式。我们提供统一的语言让数据工程师能够无缝的在多种计算方式进行整合,我们同时也提供兼容开源接口去对接外面现有的生态。
我们要把MaxCompute打造成一个数据计算的服务,而不是解决方案。所谓服务,首先需要提供统一的数仓,打通不用应用用户中的数据访问, 打破阿里内部各个部门的数据壁垒,使得所有的数据汇集到一点,可以去跨地跨部门访问这些数据,让数据在一起产生一些化学反应,从而把相关的数据关联起来,挖掘出数据背后的价值;再者需要提供一个365(天)x24(小时)的高可靠,高可用的,共享的大数据计算服务,以此来做到细粒度的统一的资源调度,使得各种业务之间能够做到相互资源填补从而做到低成本,高使用效率;***服务的方式能够让用户从运维、监控中解放出来,把这些工作交给计算系统来完成,从而大大降低使用大数据计算服务的门槛。而相对应的解决方案,则仅仅提供大数据的计算系统的安装包,用户需要自己去找相应的资源拉起,需要自己搭建运维和监控系统,需要自己管理平台升级等等工作。而这些用户定义的集群(或者是虚拟机组成集群)往往是割裂的,并不能将各个用户数据汇聚在一起进行更大范围的计算。
MaxCompute持续改进和发布中的挑战
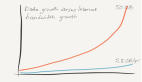
MaxCompute需要是不间断的服务,所以从高可用的角度,我们希望系统***没有更新,因为更新就有风险,这样才能更好持续不断的服务客户,能够提供给计算任务的用户四个九甚至十个九的可靠性。但是我们业务是在不停的成长,对于计算平台每天都会有新的需求,需要计算平台跟着发展,同时业务的成长速度远远快于机器采购的系统,这也推动我们的系统一定要持续提高其核心性能,从而能够去匹配业务的成长。因为以上两个理由,逼着计算平台需要持续不断的去变更。更加困难是计算平台有别于其他服务,其他服务基本上狠心节点是单机的,通过负载平衡等手段把某些流量切到新的机器上进行验证即可,但是计算平台跑的都是分布式的运算,有的任务需要用到是成千上万台机器,并且计算节点的耦合是比较紧密的,所以不能通过传统的负载平衡等手段来验证新版本。再者因为计算平台管理上万台机器,坏的变更产生的破坏是巨大的。所以我们怎么才能做到稳定和变更的平衡呢,如何能够控制变革的风险对于一个计算平台的成功是非常重要的。
打个比方,我们就像一个以高速飞行的飞机,在飞行的过程中我们需要保证安全和稳定,同时需要给飞行引擎换一个更加强大的引擎,能够飞得更高和更快。在大数据计算上面,我们的挑战具体有哪些呢?然后我们会谈谈阿里在处理这些挑战采取的解决办法。
MaxCompute每天都有***作业, 如何能够保证新的功能不会造成线上故障?
MaxCompute从***天就强调安全性,如何处理可测性和安全性之间的矛盾?
MaxCompute Playback
在阿里内部,绝大部分计算任务是批处理任务,批处理的基本流程是用户会用我们的语言写一个分布式关系代数的查询优化,通过前端提交到后端,通过编译器和优化器,生成物理执行计划会和后端的执行引擎进行绑定,在调度到后面万台规模集群进行计算。
编译器Playback工具是什么呢?我们每天有***的jobs,每天都在变,在有新功能的时候,往往需要增强我们的语言,比如支持一些迭代计算的语法,又比如提供新的UDF。再者我们内在要有非常强大的需求驱动,需要持续不断的提高优化器的表达能力,性能优化水平,从而满足业务迅速发展的需要。如何能够保证升级过程中没有大的Regression?如果我们采用人工的方式一个个用户任务去验证我们新的计算引擎,就算都是专家,可以2分钟看出是否有风险,那也需要要近4年的时间。那怎么办呢?我们的方案是利用我们自己大规模运算平台的并行运算能力来验证兼容性测试,将编译查询作为一个MaxCompute的UDF,然后执行一个并行DAG执行来并行执行上百万查询的编译优化,然后在智能分析结果得到新功能的潜在风险。
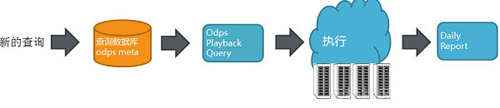
那么如何能够做到自我验证的呢?这里有个前提条件就是我们需要对编译器进行相应的改造。
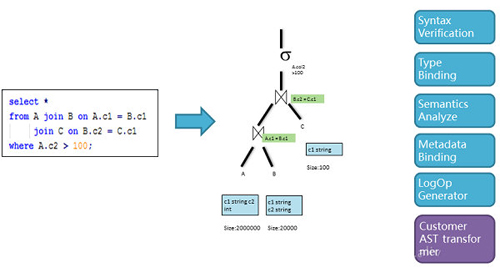
使得编译器符合基于AST的Visitor模型,经过编译变成一个AST的语法树,然后我们会一遍一遍的去遍历这个树,给这个树的节点绑定信息或者进行变换。在正常的编译过程中,我们要进行语法的分析,类型绑定,语义分析, 元数据统计数据绑定,然后生成逻辑计划交给优化器进行优化。这个是一个非常标准的编译器的模型。通过这种模式我们可以非常方便加入我们自定义的插件,使得可以我们在编译的过程去收集一些信息,这些信息可以用做后面进一步展开的统计分析。
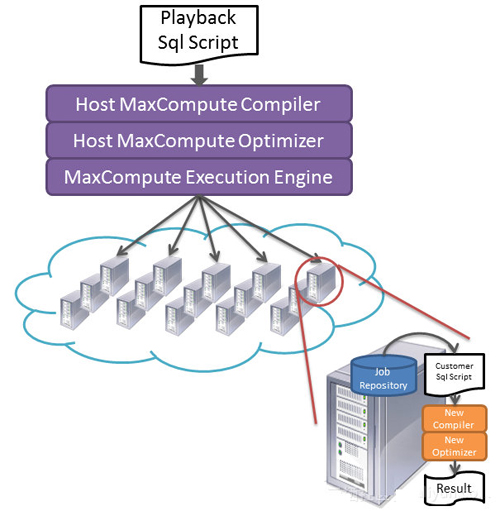
上图是具体自我验证的过程
利用MaxCompute本身灵活数据处理语言来构造分析任务;
利用MaxCompute本身超大规模计算能力来并行分析海量用户任务;
利用MaxCompute灵活的UDF支持且良好的隔离方案,在UDF中拉起待测的编译器进行编译,之后再进行详细的结果分析;
整个过程都在MaxCompute完善的安全体系保护下,保障用户的知识产权不会泄露给开发同学。
那么,我们日常做了什么事情呢?
非常简单,我们会进行新版本的验证,job有些会编译不过;我们也会精确制导找到触发新的优化规则的query,验证其查询优化是否符合预期;***我们会在语义层面做整体的数据分析,比如说我们会发现有一个API,这个API我们想下线掉,怎么知道这个业务有多少人在用,我们对相应的用户发warning推动用户下线过时的语法,我们需要你们用新的更好的一个API改造原有的任务,而且,可以对query整体进行分析来确定下一步开发的重点,还有评估在这个查询优化下面的优化提高程度等等,有了这个系统,任何我们的开发,在去验证这么大规模的时候,利用的就是我们背后大数据的分析能力。
MaxCompute Flighting
MaxCompute Playback解决了对于大量job在优化和编译的时候,我们能够快速的进行验证和比对。那么,如何保证MaxCompute优化器和运行器是正确执行的,如何避免在快速迭代中的正确性问题,从而避免重大的事故,同时需要保证数据的安全性?
传统的方式是线下搭建一个对等测试集群来验证,在我们的大数据下面是行不通的。原因在于:***,我们是一个大数据的场景,要测试集群调度或者scalability等方面的改进往往需要建立一个相同规模的测试集群,浪费巨大;第二,测试集群没有相应的任务负载,在测试集群中可以跑一个测试用例,但是想把生产集群里面水位线达到非常高,将几万台机器上跑的任务复制到集群里面,根本就做不了,因为消耗的资源是非常惊人的,没有办法复制全部的负载,只能一个一个任务去看,无法构造对应测试场景;***,数据安全问题,我们需要脱敏的方式从生产集群拖数据到测试集群里测,脱敏处理很容易人为疏忽,造成数据泄露风险,同时脱敏数据不等于用户数据,可能违背用户程序的期望,从而造成用户程序崩溃,从而达不到测试的目的,同时整个测试过程冗长,把数据拷贝过来再搭环境做测试,这样严重影响了整个开发的效率,所以是不理想的一种方式。
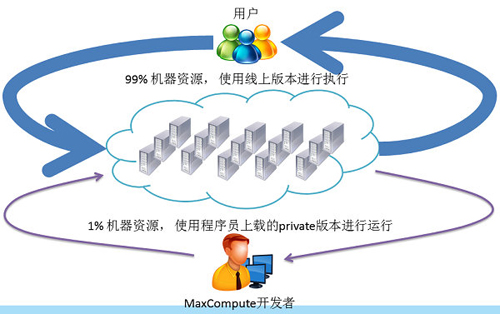
我们采取线上验证测试,我们把99%的资源去跑线上的作业,把原来用于测试的机器并入到生产集群里面,通过调度器的能力,把1%的机器资源提供给程序员可以自己提交一个私有版本,把这1%的资源用于测试任务。
那么,线上进行测试和验证的前提条件是什么?
资源隔离。我们需要做到很好的资源隔离,因为我们不希望线上的测试影响到线上生产作业的可靠性。我们在系统资源隔离上做了很多的工作,在CPU、内存上,我们加强cgroup实现,能够支撑更多更灵活资源控制;在磁盘上统一的管理下面的磁盘,并且提供存储上优先级控制;在Network万兆网上,我们加强流量的控制等等。当然这里1%其实是个弹性的,假设我们没有测试任务,1%的资源也会用于线上的任务,从而能够充分利用我们的资源。
安全性,我们需要完善多租户支持,和用户数据安全管理,使得提交测试任务的系统开发者不能触碰到用户的数据。并且我们这些测试任务的结果也会落盘,而是直接对接后面的MD5等自动化验证手段进行结果对比,确保任务正确性。
通过这种方式,相比传统方式我们能够更加保护用户的数据,因为不需要人工干预进行数据脱敏,从而避免人为犯错的可能同时这种方式***程度复制真实场景,能够可靠地进行执行性能等分析,因为所有的背景噪音是一模一样的,能够很好的验证我们在调度上,规模上各种改进的效果。
调度器优化
在线调试新的调度算法会造成环境改变,从而难以评估。往往在分布式场景里面,我们会有以下的几个经验:
不可测性。在线上改了一个算法,拿新的任务调到线上,就改变了负载,因为和老的不一样,在对比的时候,新的调度算法已经改了负载均衡,会有一系列的影响,***会发现要观察这个行为已经影响去观察的东西的本身,这是调度的不可测性。
少数者光环。我们往往会发现一种现象,当新的调度器渐渐成为主流,优化性能越来越差,这往往是性能提高主要因为新的优化器对比老优化器具有不公平竞争的关系。
那么如何验证新的调度算法。在分布式场景里面怎么做到新算法的调优,将线上workload记录下来进行模拟器进行模拟,因为workload是线上用老的方法记录下来,再跑新的算法的时候,所有的workload都是有先后关系的,变化前面一个就会变成后面一个,这个偏差误差就会越来越宽,甚至有时候方向性的判断都不能给你。所以我们也是采用flighting的方式在线上进行验证,但是为了避免少数者光环这个问题,我们需要先把新的调度器调整参数使得其和老调度器能够公平的使用资源,然后在进行验证。等到新的优化器成为主体后在来调整剩下这些。
MaxCompute灰度上线、细粒度回滚
上面我们谈了怎么运用并行分析能力验证查询器和优化器,以及怎么用flighting的工具去验证线上执行,执行时候怎么能保证产生正确结果和怎么去验证调度器的算法。这些步骤都做完,我们就要发布了,为了控制上线风险,我们支持非常细粒的灰度发布,当发现危险在不用人工干预的情况下迅速回滚。我们先把任务里面按照重要程度进行分级,然后通过一定的比例去用新版本,如果中间出现了任何问题迅速回零。
有了这几个技术,整体的开发流程分为开发、回归和上线。所有的开发工程师可以自己进行线上的认证,自己提交私有版本,也不会影响线上的版本,利用1%的线上资源可以做这个flighting。验证完就可以做回归测试,我们的发布过程中会用灰度发布来控制上线的风险,开发人员可以等上个版本的回归发布时,开始下一个版本的研发,这样才能迅速的做到快速迭代,使得大数据的分布式平台,做到持续的发布和演化。