随着Uber业务规模不断增长,我们的系统也在持续不断地产生更多的事件、服务间的消息和日志。这些数据在得到处理之前需要经过Kafka。那么我们的平台是如何实时地对这些数据进行审计的呢?
为了监控Kafka数据管道的健康状况并对流经Kafka的每个消息进行审计,我们完全依赖我们的审计系统Chaperone。Chaperone自2016年1月成为Uber的跨数据中心基础设施以来,每天处理万亿的消息量。下面我们会介绍它的工作原理,并说明我们为什么会构建Chaperone。
Uber的Kafka数据管道概览
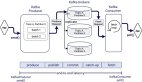
Uber的服务以双活的模式运行在多个数据中心。Apache Kafka和uReplicator是连接Uber生态系统各个部分的消息总线。
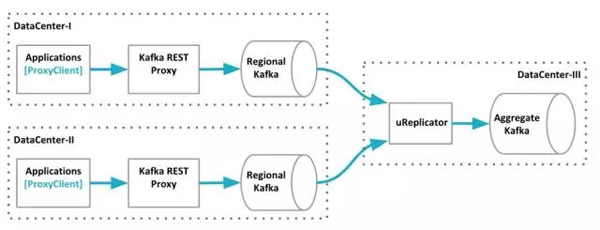
截止2016年11月份,Uber的Kafka数据管道概览。数据从两个数据中心聚合到一个Kafka集群上。
要让Uber的Kafka对下游的消费者做出即时响应是很困难的。为了保证吞吐量,我们尽可能地使用批次,并严重依赖异步处理。服务使用自家的客户端把消息发布到Kafka代理,代理把这些消息分批转发到本地的Kafka集群上。有些Kafka的主题会被本地集群直接消费,而剩下的大部分会跟来自其他数据中心的数据一起被组合到一个聚合Kafka集群上,我们使用uReplicator来完成这种面向大规模流或批处理的工作。
Uber的Kafka数据管道可以分为四层,它们跨越了多个数据中心。Kafka代理和它的客户端分别是第二层和***层。它们被作为消息进入第三层的网关,也就是每个数据中心的本地Kafka集群。本地集群的部分数据会被复制到聚合集群,也就是数据管道的***一层。
Kafka数据管道的数据都会经过分批和确认(发送确认):

Kafka数据管道的数据流经的路径概览。
Uber的数据从代理客户端流向Kafka需要经过几个阶段:
- 应用程序通过调用代理客户端的produce方法向代理客户端发送消息。
- 代理客户端把收到的消息放到客户端的缓冲区中,并让方法调用返回。
- 代理客户端把缓冲区里的消息进行分批并发送到代理服务器端。
- 代理服务器把消息放到生产者缓冲区并对代理客户端进行确认。这时,消息批次已经被分好区,并根据不同的主题名称放在了相应的缓冲区里。
- 代理服务器对缓冲区里的消息进行分批并发送到本地Kafka服务器上。
- 本地Kafka服务器把消息追加到本地日志并对代理服务器进行确认(acks=1)。
- uReplicator从本地Kafka服务器获取消息并发送到聚合服务器上。
- 聚合服务器把消息追加到本地日志并对uReplicator进行确认(acks=1)。
我们为了让Kafka支持高吞吐量,做出了一些权衡。数以千计的微服务使用Kafka来处理成百上千的并发业务流量(而且还在持续增长)会带来潜在的问题。Chaperone的目标是在数据流经数据管道的每个阶段,能够抓住每个消息,统计一定时间段内的数据量,并尽早准确地检测出数据的丢失、延迟和重复情况。
Chaperone概览
Chaperone由四个组件组成:AuditLibrary、ChaperoneService、ChaperoneCollector和WebService。
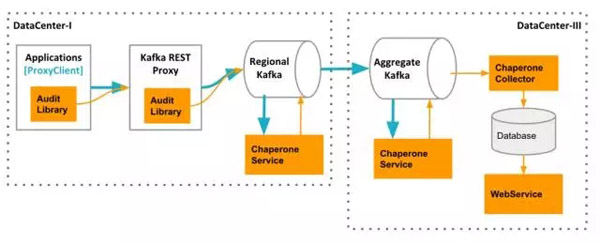
Chaperone架构:AuditLibrary、ChaperoneService、ChaperoneCollector和WebService,它们会收集数据,并进行相关计算,自动检测出丢失和延迟的数据,并展示审计结果。
AuditLibrary实现了审计算法,它会定时收集并打印统计时间窗。这个库被其它三个组件所依赖。它的输出模块是可插拔的(可以使用Kafka、HTTP等)。在代理客户端,审计度量指标被发送到Kafka代理。而在其它层,度量指标直接被发送到专门的Kafka主题上。
审计算法是AuditLibrary的核心,Chaperone使用10分钟的滚动时间窗来持续不断地从每个主题收集消息。消息里的事件时间戳被用来决定该消息应该被放到哪个时间窗里。对于同一个时间窗内的消息,Chaperone会计算它们的数量和p99延迟。Chaperone会定时把每个时间窗的统计信息包装成审计消息发送到可插拔的后端,它们可能是Kafka代理或者之前提到的Kafka服务器。
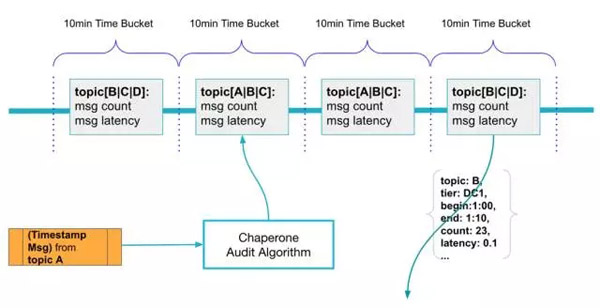
Chaperone根据消息的事件时间戳把消息聚合到滚动时间窗内。
审计消息里的tier字段很重要,通过它可以知道审计是在哪里发生的,也可以知道消息是否到达了某一个地方。通过比较一定时间段内不同层之间的消息数量,我们可以知道这段时间内所生成的消息是否被成功送达。
ChaperoneService是工作负载***的一个组件,而且总是处在饥饿的状态。它消费Kafka的每一个消息并记录时间戳。ChaperoneService是基于uReplicator的HelixKafkaConsumer构建的,这个消费者组件已经被证明比Kafka自带的消费者组件(Kafka 0.8.2)更可靠,也更好用。ChaperoneService通过定时向特定的Kafka主题生成审计消息来记录状态。
ChaperoneCollector监听特定的Kafka主题,并获取所有的审计消息,然后把它们存到数据库。同时,它还会生产多个仪表盘:
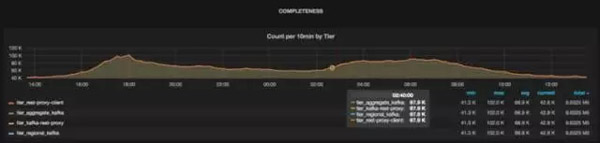
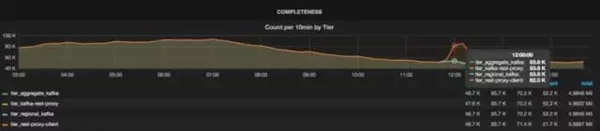
Chaperone创建的仪表盘,从上面我们看出数据的丢失情况。
从上图可以看出每个层的主题消息总量,它们是通过聚合所有数据中心的消息得出的。如果没有数据丢失,所有的线会***地重合起来。如果层之间有数据丢失,那么线与线之间会出现裂缝。例如,从下图可以看出,Kafka代理丢掉了一些消息,不过在之后的层里没有消息丢失。从仪表盘可以很容易地看出数据丢失的时间窗,从而可以采取相应的行动。
从仪表盘上还能看出消息的延迟情况,借此我们就能够知道消息的及时性以及它们是否在某些层发生了传输延迟。用户可以直接从这一个仪表盘上看出主题的健康状况,而无需去查看Kafka服务器或uReplicator的仪表盘:
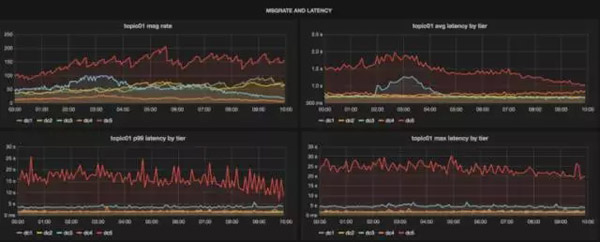
Chaperone提供一站式的仪表盘来查看每个数据中心的主题状态。
***,WebService提供了REST接口来查询Chaperone收集到的度量指标。通过这些接口,我们可以准确地计算出数据丢失的数量。在知道了数据丢失的时间窗后,我们可以从Chaperone查到确切的数量:
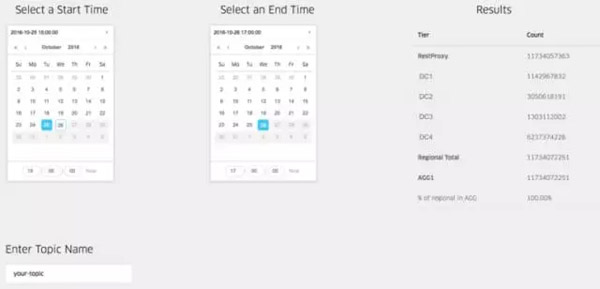
Chaperone的Web界面。
Chaperone的两个设计目标
在设计Chaperone时,为了能够做到准确的审计,我们把注意力集中在两个必须完成的任务上:
1)每个消息只被审计一次
为了确保每个消息只被审计一次,ChaperoneService使用了预写式日志(WAL)。ChaperoneService每次在触发Kafka审计消息时,会往审计消息里添加一个UUID。这个带有相关偏移量的消息在发送到Kafka之前被保存在WAL里。在得到Kafka的确认之后,WAL里的消息被标记为已完成。如果ChaperoneService崩溃,在重启后它可以重新发送WAL里未被标记的审计消息,并定位到最近一次的审计偏移量,然后继续消费。WAL确保了每个Kafka消息只被审计一次,而且每个审计消息至少会被发送一次。
接下来,ChaperoneCollector使用ChaperoneService之前添加过的UUID来移除重复消息。有了UUID和WAL,我们可以确保审计的一次性。在代理客户端和服务器端难以实现一次性保证,因为这样会给它们带来额外的开销。我们依赖它们的优雅关闭操作,这样它们的状态才会被冲刷出去。
2)在层间使用一致性的时间戳
因为Chaperone可以在多个层里看到相同的Kafka消息,所以为消息内嵌时间戳是很有必要的。如果没有这些时间戳,在计数时会发生时间错位。在Uber,大部分发送到Kafka的数据要么使用avro风格的schema编码,要么使用JSON格式。对于使用schema编码的消息,可以直接获取时间戳。而对于JSON格式的消息,需要对JSON数据进行解码才能拿到时间戳。为了加快这个过程,我们实现了一个基于流的JSON消息解析器,这个解析器无需预先解码整个消息就可以扫描到时间戳。这个解析器用在ChaperoneService里是很高效的,不过对代理客户端和服务器来说仍然需要付出很高代价。所以在这两个层里,我们使用的是消息的处理时间戳。因为时间戳的不一致造成的层间计数差异可能会触发错误的数据丢失警告。我们正在着手解决时间戳不一致问题,之后也会把解决方案公布出来。
Chaperone在Uber的两大用途
1. 检测数据丢失
在Chaperone之前,数据丢失的***个征兆来自数据消费者,他们会出来抱怨数据的丢失情况。但是等他们出来抱怨已经为时已晚,而且我们无法知道是数据管道的哪一部分出现了问题。有了Chaperone之后,我们创建了一个用于检测丢失数据的作业,它会定时地从Chaperone拉取度量指标,并在层间的消息数量出现不一致时发出告警。告警包含了Kafka数据管道端到端的信息,从中可以看出那些管道组件的度量指标无法告诉我们的问题。检测作业会自动地发现新主题,并且你可以根据数据的重要性配置不同的告警规则和阈值。数据丢失的通知会通过多种通道发送出去,比如页式调度系统、企业聊天系统或者邮件系统,总之会很快地通知到你。
2. 在Kafka里通过偏移量之外的方式读取数据
我们生产环境的大部分集群仍然在使用Kafka 0.8.x,这一版本的Kafka对从时间戳到偏移量的索引没有提供原生支持。于是我们在Chaperone里自己构建了这样的索引。这种索引可以用来做基于时间区间的查询,所以我们不仅限于使用Kafka的偏移量来读取数据,我们可以使用Chaperone提供的时间戳来读取数据。
Kafka对数据的保留是有期限的,不过我们对消息进行了备份,并把消息的偏移量也原封不动地保存起来。借助Chaperone提供的索引,用户可以基于时间区间读取这些备份数据,而不是仅仅局限于Kafka现存的数据,而且使用的访问接口跟Kafka是一样的。有了这个特性,Kafka用户可以通过检查任意时间段里的消息来对他们的服务进行问题诊断,在必要时可以回填消息。当下游系统的审计结果跟Chaperone出现不一致,我们可以把一些特定的消息导出来进行比较,以便定位问题的根源。
总结
我们构建了Chaperone来解决以下问题:
- 是否有数据丢失?如果是,那么丢失了多少数据?它们是在数据管道的哪个地方丢失的?
- 端到端的延迟是多少?如果有消息延迟,是从哪里开始的?
- 是否有数据重复?
Chaperone不仅仅告诉我们系统的健康情况,它还告诉我们是否有数据丢失。例如,在Kafka服务器返回非预期的错误时,uReplicator会出现死循环,而此时uReplicator和Kafka都不会触发任何告警,不过我们的检测作业会很快地把问题暴露出来。
如果你想更多地了解Chaperone,可以自己去探究。我们已经把Chaperone开源,它的源代码放在Github上。