












工作需要用到C++中的正则表达式,所以就研究了以上三种正则。
1、C regex
/* write by xingming * time:2012年10月19日15:51:53 * for: test regex * */
#include <regex.h>
#include <iostream>
#include <sys/types.h>
#include <stdio.h>
#include <cstring>
#include <sys/time.h>
using namespace std;
const int times = 1000000;
int main(int argc,char** argv) {
char pattern[512]="finance\.sina\.cn|stock1\.sina\.cn|3g\.sina\.com\.cn.*(channel=finance|_finance$|ch=stock|/stock/)|dp.sina.cn/.*ch=9&";
const size_t nmatch = 10;
regmatch_t pm[10];
int z ;
regex_t reg;
char lbuf[256]="set",rbuf[256];
char buf[3][256] = {"finance.sina.cn/google.com/baidu.com.google.sina.cndddddddddddddddddddddda.sdfasdfeoasdfnahsfonadsdf",
"3g.com.sina.cn.google.com.dddddddddddddddddddddddddddddddddddddddddddddddddddddbaidu.com.sina.egooooooooo",
"http://3g.sina.com.cn/google.baiduchannel=financegogo.sjdfaposif;lasdjf.asdofjas;dfjaiel.sdfaosidfj"};
printf("input strings:\n");
timeval end,start;
gettimeofday(&start,NULL);
regcomp(®,pattern,REG_EXTENDED|REG_NOSUB);
for(int i = 0 ; i < times; ++i)
{
for(int j = 0 ; j < 3; ++j)
{
z = regexec(®,buf[j],nmatch,pm,REG_NOTBOL);
/* if(z==REG_NOMATCH) printf("no match\n"); else printf("ok\n"); */
}
}
gettimeofday(&end,NULL);
uint time = (end.tv_sec-start.tv_sec)*1000000 + end.tv_usec - start.tv_usec;
cout<<time/1000000<<" s and "<<time%1000000<<" us."<<endl;
return 0 ;
}
使用正则表达式可简单的分成几步:
- 1.编译正则表达式
- 2.执行匹配
- 3.释放内存
首先,编译正则表达式
int regcomp(regex_t *preg, const char *regex, int cflags);
reqcomp()函数用于把正则表达式编译成某种格式,可以使后面的匹配更有效。
preg: regex_t结构体用于存放编译后的正则表达式;
regex: 指向正则表达式指针;
cflags:编译模式
共有如下四种编译模式:
REG_EXTENDED:使用功能更强大的扩展正则表达式
REG_ICASE:忽略大小写
REG_NOSUB:不用存储匹配后的结果
REG_NEWLINE:识别换行符,这样‘$’就可以从行尾开始匹配,‘^’就可以从行的开头开始匹配。否则忽略换行符,把整个文本串当做一个字符串处理。
其次,执行匹配
int regexec(const regex_t *preg, const char *string, size_t nmatch, regmatch_t pmatch[], int eflags);
preg: 已编译的正则表达式指针;
string:目标字符串;
nmatch:pmatch数组的长度;
pmatch:结构体数组,存放匹配文本串的位置信息;
eflags:匹配模式
共两种匹配模式:
REG_NOTBOL:The match-beginning-of-line operator always fails to match (but see the compilation flag REG_NEWLINE above). This flag may be used when different portions of a string are passed to regexec and the beginning of the string should not be interpreted as the beginning of the line.
REG_NOTEOL:The match-end-of-line operator always fails to match (but see the compilation flag REG_NEWLINE above)
***,释放内存
void regfree(regex_t *preg);
当使用完编译好的正则表达式后,或者需要重新编译其他正则表达式时,一定要使用这个函数清空该变量。
其他,处理错误
size_t regerror(int errcode, const regex_t *preg, char *errbuf, size_t errbuf_size);
当执行regcomp 或者regexec 产生错误的时候,就可以调用这个函数而返回一个包含错误信息的字符串。
errcode: 由regcomp 和 regexec 函数返回的错误代号。
preg: 已经用regcomp函数编译好的正则表达式,这个值可以为NULL。
errbuf: 指向用来存放错误信息的字符串的内存空间。
errbuf_size: 指明buffer的长度,如果这个错误信息的长度大于这个值,则regerror 函数会自动截断超出的字符串,但他仍然会返回完整的字符串的长度。所以我们可以用如下的方法先得到错误字符串的长度。
当然我在测试的时候用到的也比较简单,所以就直接用了,速度一会再说!
2、C++ regex
/* write by xingming * time:2012年10月19日15:51:53 * for: test regex * */
#include <regex>
#include <iostream>
#include <stdio.h>
#include <string>
using namespace std;
int main(int argc,char** argv) {
regex pattern("[[:digit:]]",regex_constants::extended);
printf("input strings:\n");
string buf;
while(cin>>buf)
{
printf("*******\n%s\n********\n",buf.c_str());
if(buf == "quit")
{
printf("quit just now!\n");
break;
}
match_results<string::const_iterator> result;
printf("run compare now! '%s'\n", buf.c_str());
bool valid = regex_match(buf,result,pattern);
printf("compare over now! '%s'\n", buf.c_str());
if(!valid)
printf("no match!\n");
else
printf("ok\n");
}
return 0 ;
}
C++这个真心不想多说它,测试过程中发现 字符匹配的时候 ‘a’ 是可以匹配的,a+也是可以的,[[:w:]]也可以匹配任意字符,但[[:w:]]+就只能匹配一个字符,+号貌似不起作用了。所以后来就干脆放弃了这伟大的C++正则,如果有大牛知道这里面我错在哪里了,真心感谢你告诉我一下,谢谢。
3、boost regex
/* write by xingming
* for:test boost regex
* time:2012年10月23日11:35:33
* */ #include <iostream> #include <string> #include <sys/time.h>
#include "boost/regex.hpp"
using namespace std;
using namespace boost;
const int times = 10000000;
int main()
{
regex pattern("finance\\.sina\\.cn|stock1\\.sina\\.cn|3g\\.sina\\.com\\.cn.*(channel=finance|_finance$|ch=stock|/stock/)|dp\\.s ina\\.cn/.*ch=9&");
cout<<"input strings:"<<endl;
timeval start,end;
gettimeofday(&start,NULL);
string input[] = {"finance.sina.cn/google.com/baidu.com.google.sina.cn",
"3g.com.sina.cn.google.com.baidu.com.sina.egooooooooo",
"http://3g.sina.com.cn/google.baiduchannel=financegogo"};
for(int i = 0 ;i < times; ++ i)
{
for(int j = 0 ; j < 3;++j)
{
//if(input=="quit")
// break;
//cout<<"string:'"<<input<<'\''<<endl;
cmatch what;
if(regex_search(input[j].c_str(),what,pattern)) ;
// cout<<"OK!"<<endl;
else ;
// cout<<"error!"<<endl;
}
}
gettimeofday(&end,NULL);
uint time = (end.tv_sec-start.tv_sec)*1000000 + end.tv_usec - start.tv_usec;
cout<<time/1000000<<" s and "<<time%1000000<<" us."<<endl;
return 0 ;
}
boost正则不用多说了,要是出去问,C++正则怎么用啊?那90%的人会推荐你用boost正则,他实现起来方便,正则库也很强大,资料可以找到很多,所以我也不在阐述了。
4、对比情况
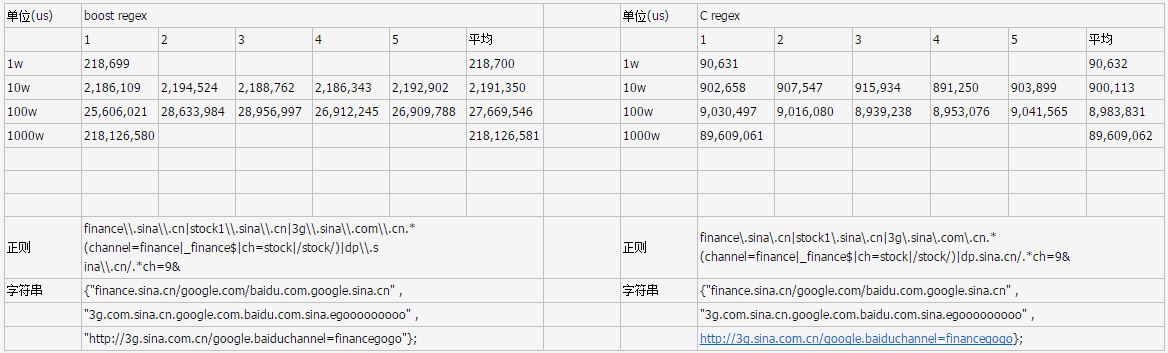
总结:
C regex的速度让我吃惊啊,相比boost的速度,C regex的速度几乎要快上3倍,看来正则引擎的选取上应该有着落了!
上面的表格中我用到的正则和字符串是一样的(在代码中C regex的被我加长了),速度相差几乎有3倍,C的速度大约在30+w/s , 而boost的速度基本在15-w/s ,所以对比就出来了!
在这里Cregex的速度很让我吃惊了已经,但随后我的测试更让我吃惊。
我以前在.net正则方面接触的比较多,就写了一个.net版本的作为对比
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Text.RegularExpressions;
namespace 平常测试
{
class Program
{
static int times = 1000000;
static void Main(string[] args) {
Regex reg = new Regex(@"(?>finance\.sina\.cn|stock1\.sina\.cn|3g\.sina\.com\.cn.*(?:channel=finance|_finance$|ch=stock|/stock/)|dp.sina.cn/.*ch=9&)",RegexOptions.Compiled);
string[] str = new string[]{@"finance.sina.cn/google.com/baidu.com.google.sina.cn",
@"3g.com.sina.cn.google.com.baidu.com.sina.egooooooooo",
@"http://3g.sina.com.cn/google.baiduchannel=financegogo"};
int tt = 0;
DateTime start = DateTime.Now;
for (int i = 0; i < times; ++i)
{
for (int j = 0; j < 3; ++j)
{
if (reg.IsMatch(str[j])) ;
//Console.WriteLine("OK!");
//else
//Console.WriteLine("Error!");
}
}
DateTime end = DateTime.Now;
Console.WriteLine((end - start).TotalMilliseconds);
Console.WriteLine(tt);
Console.ReadKey();
}
}
}
结果发现,正则在不进行RegexOptions.Compiled 的时候,速度和C regex的基本一样,在编译只会,速度会比C regex快上一倍,这不由得让我对微软的那群人的敬畏之情油然而生啊。
但随后我去查看了一下该博客上面C regex的描述,发现我可以再申明正则的时候加入编译模式,随后我加入了上面代码里的 REG_NOSUB(在先前测试的时候是没有加入的),结果让我心理面很激动的速度出来了,C regex 匹配速度竟然达到了 300+w/s,也就是比原来的(不加入REG_NOSUB)的代码快了将近10倍。
之后我变换了匹配的字符串,将其长度生了一倍,达到每个100字符左右(代码里面所示),匹配速度就下来了,但是也能达到 100w/s左右,这肯定满足我们现在的需求了。
结果很显然,当然会选择C regex了。
















