核心内容:
1、Hadoop开发过程中常见问题即解决方案
在Hadoop开发的过程中,我们总是遇到各种各样的问题,今天就整理总结一下:
***的解决方案:6个检查+具体日志
在Hadoop开发的过程中如果遇到各种异常,首先使用jps命令查看节点的启动是否正常,然后在去查看相关的日志文件,但是在查看相关日志之前,你可以先检查一下面几点:
1、防火墙原因:检查各个节点的防火墙是否关闭成功。(重点是检查NameNode)

2、检查IP地址与主机名的映射关系是否绑定成功

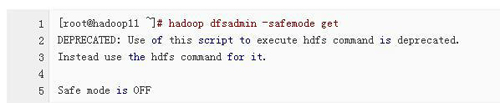
3、检查NameNode是否处于安全模式
4、检查NameNode是否已经进行了格式化处理
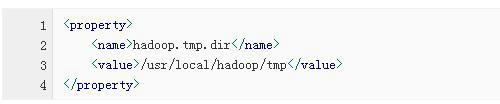
5、检查配置文件的配置是否成功
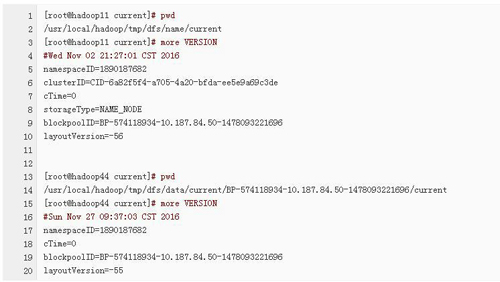
6、检查NameNode节点和DataNode节点中存放的namespaceID的版本号是否相同
好的,当我们查看完上述6点之后如果还没有解决问题,那我们再去查看相关的日志文件即可。
OK,到现在为止我在给大家介绍一下在开发过程中经常遇到的几个异常问题:
1、启动hadoop时没有NameNode的可能原因
这个问题对于Hadoop的初学者是经常遇到的,之所以出现这个问题,可能有3点原因:
1)、NameNode没有进行格式化处理(6个检查以包括)
先删除hadoop.tmp.dir所对应的目录(即logs和tmp),然后对NameNode进行格式化处理
2)、检查IP地址与主机名的映射关系是否绑定成功(6个检查以包括)
3)、检查配置文件的配置是否成功(6个检查以包括),重点是hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml和slaves。
2、Name node is in safe mode.
例如:

原因:NameNode在刚开始启动的时候会进入到安全模式,倒计时30s后退出,在安全模式下会不能进行增、删、改操作,只能进行查看操作。但是如果数据节点DataNode丢失的block块达到一定比例的话则系统一直处于安全模式,即只读状态。
解决方法:
1)、在HDFS的配置文件hdfs-site.xml中,修改dfs.safemode.threshold.pct所对应的数值,将其数值改成一个较小的数值,默认的数值是0.999f。

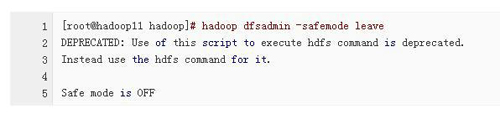
2)、执行命令 hadoop dfsadmin -safemode leave 强制NameNode离开安全模式。(6个检查以包括)
3)、could only be replicatied to 0 nodes, instead of 1.
例如:


这个异常可能出现的现象:执行命令jps显示的进程都很正常,但是用web界面查看的话,显示的live nodes为0,这说明数据节点DataNode没有正常启动,但是数据节点DataNode又正常启动了。
这个问题可能出现的原因:
1)、防火墙原因,检查所有节点的防火墙是否关闭成功。(6个检查以包括)
2)、磁盘空间原因:执行命令df -al 查看磁盘空间的使用情况,如果是磁盘空间不足的话,则调整磁盘空间。
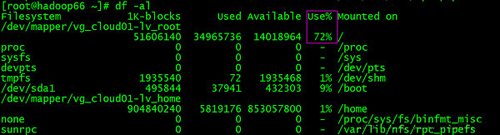
如果是磁盘空间不足的话,具体进行下面的步骤在进行查看:
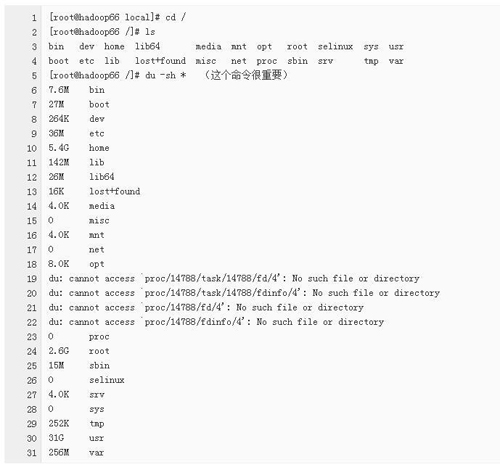
3、如果上述方法都不行的话,可用以下方法进行处理(但是该方法会造成数据的丢失,所以慎用!)
先删除hadoop.tmp.dir所对应的目录,然后对NameNode重新进行格式化处理。(6个检查以包括)
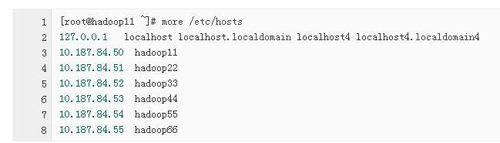
4、启动时报错 java.net.UnknownHostException
原因:集群中的主机名没有映射到相应的IP地址(6个检查以包括)
解决方法:在/etc/hosts文件中添加所有节点的主机名与IP地址的映射关系。
5、TaskTracker进程启动了,但是DataNode进程没有启动
解决方法:先删除hadoop.tmp.dir所对应的文件夹,然后对NameNode重新进行格式化处理。

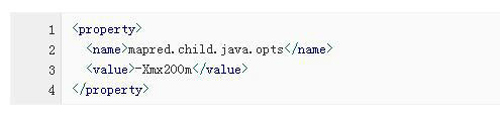
6、java.lang.OutOfMemoryError
原因分析:出现这个异常,明显是JVM内存不足的原因,要修改所有数据节点DataNode所对应的JVM内存大小。
方法:在MapReduce的配置文件mapred-site.xml中,修改mapred.child.java.opts所对应的数值。
注意:一般JVM的***内存使用应该为总内存大小的一半,例如我们的服务器的内存大小为4G,则设置为2048m,但是这个值可能依旧不是***的数值。其中
-Xms 表示内存初始化的大小,-Xmx表示能够使用的***内存。
在linux 下查看服务器内存的硬件信息:

7、Incompatible namespaceIDs in
原因分析:每次对NameNode格式化之后都会产生一个新的namespaceID,如果多次对NameNode格式化的话可能导致NameNode节点和DataNode节点中存放的版本号不一致。
解决方法:
1)、在NameNode节点和DataNode节点中检查namespaceID的版本号是否相同,如果不相同的话,修改为相同的值后然后重新启动该节点。(6个检查以包括)
2)、先删除hadoop.tmp.dir所对应的目录,然后对NameNode重新进行格式化处理。(6个检查以包括)
上面这些就是我在开发过程中经常遇到的一些问题,希望对大家有所帮助。