作者 | 毛丽 魏子敏
星际探索中,一切成就变得格外伟大而浪漫。在无数太空任务中,一类任务特别激动人心——寻找外星生命。
封面图来自NASA
天文学家搜寻外星人的每一点进展都让全人类沸腾。而除了天文学知识和仪器的进展,鉴于天文研究涉及的数据量级异常巨大,数据处理的精进、机器学习、云计算等在数据科学领域的新成就也会为这项事业带来新的意义。
本月早些时间,在东伦敦举办的高性能计算年度研讨会中(Centre for High Performance Computing Workshop),IBM南非研究实验室的Francois Luus博士主持了一场长达三小时的研讨,探索关于深度学习计算环境和无监督学习的相关话题。Francois Luus博士介绍了一项由IBM和SETI研究院合作展开的有趣项目,希望利用Spark和机器学习技术找出数据异常,寻找太空中的外星文明信号。
IBM研究实验室的Francois Luus博士介绍相关项目(图片来自IBM博客)
如果假设我们的外星邻居们在试图与我们接触,我们也应该寻找他们。
目前我们已经启动了若干个计划,用来搜索在宇宙中的其他地方存在着生命的证据。这些计划总称为“SETI(the Search for Extra-Terrestrial Intelligence)”。
SETI致力于用射电望远镜等先进设备接收从宇宙中传来的电磁波,从中分析有规律的信息数据,希望借此发现外星文明。
过去数十年,SETI为了收集外星生命存在的迹象,构建了“艾伦望远镜阵列”(Allen Telescope Array,www.seti.org/ata)。这项工程由微软联合创始人保罗艾伦资助,目标是通过构建一个小型望远镜阵列,在降低成本的同时,达到巨型天文望远镜的探测效果。艾伦望远镜阵列也被称为“世界上用于搜寻银河系中其他文明的最有力的工具”。
艾伦望远镜阵列每小时产生的数据量级高达4.5TB,探测数据中又夹杂大量由自然界和人类产生的干扰数据。
如何处理如此巨大的数据流量?如何通过机器学习算法排除其中的干扰数据,找出真正令人感兴趣的“外太空信号“?这是SETI亟待解决的技术难题。
IBM目前正使用Spark技术和机器学习算法协助NASA下属的非盈利科研机构SETI (致力于研究人类起源和外星文明的科研机构)来搜寻外星文明。
本次研讨会上,Francois Luus博士向十几位与会者介绍了IBM Bluemix Spark这一技术,并汇报了***进展。艾伦望远镜阵列被用于以厘米波段寻找外星智慧存在的蛛丝马迹,至今已产生600万个信号样本。而IBM Bluemix Spark将用来分析取自这些样本的压缩数据集。Francois Luus博士的团队目标是利用Spark和机器学习技术找出数据异常,进而发现外星生命。
Francois Luus博士表示,这些数据量级太大,SETI团队说不定会漏掉某些外星人的信号。因此,团队公开了数据库,并提供了数据处理工具,还给出了一些入门的Ipython notebook格式的代码。这些资源可以从GitHub上下载到。感兴趣的同学可以下载下来,说不定可以发现外星文明的信息!
GitHub相关数据集链接:https://github.com/ibm-cds-labs/seti_at_ibm
参与研讨会的学生会在导师指导下,从数据集中寻找与外星人相关的异常值(图片来自IBM博客)
关于SETI数据集和数据获取、处理流程
图片来自NASA
SETI利用艾伦望远镜阵列(ATA)来收集太阳系外的辐射信号。几乎每个夜晚,ATA都会收集来自于天空中各个角落的、频率在1-10 GHz的辐射信号。
信号观测的结果储存于下面的数据中:
- 两个原始数据文件,可能是两个CompAmp或两个archive-CompAmp文件,这取决于信号分类的结果。
- 实时信号分析结果,在SignalDB 中储存为一行数据。
对于每一个ATA望远镜,辐射信号的水平分量和垂直分量是分别测量的。对于每一个偏振方向,全体ATA阵列的原始时序信号会被数字化,并组合成一个数据文件。
另外,时序信号经过带通滤波,因此数据中信号的频率只有很小的范围,也就是带宽是比较小的。确切的频率范围可以从原始数据文件的开头获取信息,并解析出来。团队提供了一个python包,ibmseti,可以帮我们解析这个信息。它还可以读取数据文件,进行一些必要的信号处理。
获取数据的一个典型的流程如下:
- 找到天空中感兴趣的区域,并记录它的坐标。
- 确定这些点或者区域的数据是可以获取到的。
- 获取此区域的一行SignalDB 数据,和一个原始原始文件信息。
- 获取原始数据文件的一个临时URL。
- 下载和存储数据。
假如我们要使用的特征是“标准差”。可以计算每个轴的标准差,考虑N个频率段(通常为6144)和M个时间段(通常为129)的频谱图。
首先计算沿时间轴的标准差std_time,然后为每个时间段计算沿频率轴的标准差std_freq。如图所示:
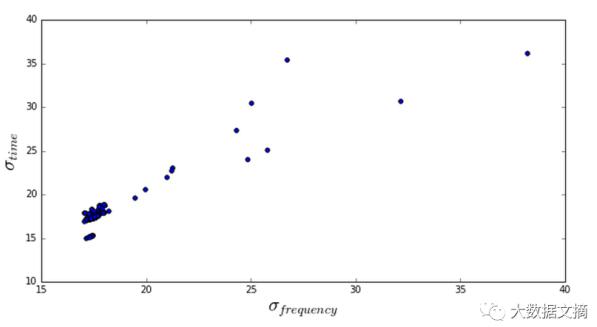
对于典型的窄带信号,std_freq将相对较大。这是因为在M个时间间隔中的每一个时间段,在所有频率上的值的集合将包含大量的小噪声值和大量的大信号值 - 因此,数字的分布范围较广。沿着时间轴,std_time将相对较小,因为对于大多数频段,在零之上的小范围的值中将仅存在噪声。当然,如果信号通过该频率,可能存在少数具有大带宽的信号。但绝大多数会是噪音,导致一个小的std_time。
相反,在宽频率范围内,但是仅在短持续时间内看到的信号将具有小的std_freq和大的std_time。
那么,我们要找的外星文明信号是什么样的呢?嗯,简单说,“谁都不知道”。我们在寻找潜在信号时,也会注意尽量减少假设和限制条件。
不过,我们还是可以推断,外星文明的信号是有这样的特征的:
- 持续。在天空中相同区域重复发现同样的信号。
- 独特。在天空中其他位置,不会同时发现这个信号。
- 可复现。发现一个信号之后,需要另一个独立的观测来确认它。
- 稳定的非零多普勒漂移。所有漂移频率为零的信号都可能是本地射频干扰(RFI)。
- 不是本地射频干扰(RFI)。在SETI内部,有一个RFI信号数据库,用来在信号分类之前进行比对。此项目提供的数据都通过了这个比对。
- 存在智能的迹象。信号看起来是经过编码的,或表现出统计特征(非噪音)。
图片来自NASA
你也可以参与其中
如果你是天文小白,又想为寻找外星人的人类伟大事业做贡献,除了从GitHub上下载相关数据集寻找外星文明的信息,SETI@home项目也为你提供了一些可能。
SETI@home项目是一项利用全球联网的计算机共同搜寻地外文明的科学实验计划。志愿者可以通过运行一个免费程序下载并分析从射电望远镜传来的数据来加入这个项目。它会利用电脑空闲时间开始运算,并贡献运算的结果。
目前存在的绝大多数SETI程序,包括在加州伯克利大学(UC Berkeley)大楼里大型计算机上运行的程序,都在实时的对从天文望远镜收集来的数据进行分析。这些计算机都没有对这些微弱的信号进行深入的分析,也没有试图搜索更多种类的信号(关于信号的类型,将在后面讨论)。之所以没有这样做的原因是用来进行分析的计算机的处理能力是有限的。
要想从大量的极其微弱的信号中发现什么的话,必须需要极其大量的计算机的处理能力,因此需要一台超级计算机来完成这个工作。SETI计划根本不可能也没有能力建造或者购买这样的计算机,因此他们采取了另一种平衡的方法。那就是用比较小的计算机而花更多的时间来完成这个工作。
SETI@home希望你能够允许在你不使用计算机的时候,借用它来帮助“寻找新的生命形式,寻找新的文明”的计划。SETI@home将利用运行在你的计算机上的屏幕保护程序来完成这个工作,它能够通过互联网从我们的服务器上获得一个数据包,分析它并将结果返回给我们。当你需要用你的计算机工作的时候,屏幕保护程序会立即退出,只有在你完成工作而不使用计算机的时候才开始继续进行分析的工作。
SETI@home早期的服务器已经停止,现在加入了BONIC平台,成为了其中的一部分。可以下载客户端,选择SETI@home参与到发现外星人的工作中。当然,BONIC平台还有一些其它有意思的项目,比如上个月,通过全球计算机的共同努力,它发现了一个新的质数10223*231172165+1。
【本文是51CTO专栏机构大数据文摘的原创文章,微信公众号“大数据文摘( id: BigDataDigest)”】