前言
Use-After-Free是一种众所周知的漏洞类型,经常被现代的攻击代码所利用(参见Pwn2own 2016)。在研究项目AnaStaSec中,AMOSSYS提供了许多关于如何静态检测二进制代码中的此类漏洞的介绍。在这篇博文中,我们将向读者阐述学术界在如何检测这种类型的漏洞方面提出的各种建议。当然,他们当前的目标是定义一种通用方法,这样的话,我们就可以根据自己的需求来构建相应的概念验证工具了。
关于Use-After-Free(UAF)漏洞
UAF的原理很容易理解。当程序尝试访问先前已被释放的内存区时,就会出现“Use-After-Free”漏洞。在这种情况下创建的悬空指针将指向内存中已经释放的对象。
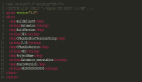
举个例子,下面的代码将导致一个UAF漏洞。如果下面的代码在运行过程中执行了if分支语句的话,由于指针ptr指向无效的存储器区,所以可能发生不确定的行为。
- char * ptr = malloc(SIZE);
- …
- if (error){
- free(ptr);
- }
- …
- printf("%s", ptr);
图 1:Use-After-Free示例代码
换句话说,如果发生如下所示的3个步骤,就会出现UAF漏洞:
(1)分配一个内存区并且让一个指针指向它。
(2)内存区被释放,但原来的指针仍然可用。
(3)使用该指针访问先前释放的内存区。
大多数时候,UAF漏洞会只会导致信息泄漏,但有的时候,它还可能导致代码执行——攻击者对这种情况更感兴趣。导致代码执行通常发生在下列情况下:
- 程序分配了内存块A,后来将其释放了。
- 攻击者分配了内存块B,并且该内存块使用的就是之前分配给内存块A的那片内存。
- 攻击者将数据写入内存块B。
- 程序使用之前释放的内存块A,访问攻击者留下的数据。
在C++中,当类A被释放后,攻击者立刻在原来A所在的内存区上建立一个类B的时候,就经常出现这种漏洞。这样的话,当调用类A的方法的时候,实际上执行的是攻击者加载到类B中的代码。
现在我们已经掌握了UAF的概念,接下来我们将考察安全社区是如何检测这种漏洞的。
静态和动态分析的优缺点
二进制代码的分析方法主要有两种:静态分析和动态分析。就目前来说,动态地分析整个代码是非常困难的,因为要想生成可以覆盖所有二进制代码执行路径的输入的话,绝不是一件容易的事情。因此,当我们专注于代码覆盖问题时,静态分析方法似乎更为适用。
然而,根据论文[Lee15]和[Cab12]的介绍,与Use-After-Free漏洞检测有关的大多数学术论文仍然集中在动态分析方面。这主要是因为。动态分析方法易于检测同一指针的副本,也称为别名。换句话说,使用动态分析方法时,我们可以直接访问内存中的值,这种能力对于代码分析来说是非常重要的。如果使用动态分析的话,我们能够获得更高的准确性,但同时也会失去一些完整性。
然而,本文将专注于静态分析方法。在学术界看来,这种方法仍然面临两大困难:
1) 最大的困难是如何管理程序中的循环。实际上,当计算循环中待处理的变量的所有可能值时,需要知道循环将被执行多少次。这个问题通常被称为停机问题。在可计算性理论中,所谓停机问题就是去判断程序会最终停下来,还是一直运行下去。不幸的是,这个问题已经被证明是无解的。换句话说,没有通用算法可以在给出所有可能输入的情况下解决所有可能程序的停止问题,即不存在一个判定一切程序的程序,因为这个程序本身也是程序。在这种情况下,为了解决这个问题,只好借助于静态分析工具来进行相应的简化了。
2) 另一个困难在于内存的表示方式。一个简单的解决方案是维护一个大数组,其中保存指针的内存值。然而,这不是看起来那么简单。例如,一个内存地址可以具有多个可能的值,或者一些变量可以具有多个可能的地址。此外,如果有太多可能取值,那么将所有的值都单独保存的话是不合理的。因此,必须对这种内存表示进行一些简化。
为了降低静态分析的复杂性,一些论文像[Ye14]或像Polyspace或Frama-C这样的工具,都是在C源代码级别来分析问题的,因为这个级别包含了最大程度的信息。但是,人们在分析应用程序的时候,通常是无法访问源代码的。
从二进制代码到中间表示
当我们进行二进制分析的时候,第一步是建立相关的控制流图(CFG)。控制流图是一种有向图,用来表示程序在执行期间可能经过的所有路径。CFG的每个节点代表一条指令。由一条边连接的两个节点表示可以连续执行的两个指令。如果一个节点具有两个延伸到其他节点的边,这表明该节点是一个条件跳转指令。因此,通过CFG我们可以将一个二进制代码组织成一个指令的逻辑序列。在为可执行文件建立CFG的时候,最常见的方法是使用反汇编程序IDA Pro。
当处理二进制代码方面,学术论文好像都是用相同的方式来处理UAF漏洞的。论文[Gol10]和[Fei14]给出了具体的处理步骤:
事实表明循环似乎对Use-After-Free的存在没有很大的影响。因此,在着手处理二进制代码时,一个强制性的步骤就是利用第一次迭代展开循环。就像我们前面刚刚解释的那样,这个步骤可以避免停机问题。第一次迭代
为了简化前面提到的内存表示问题,我们可以使用中间表示形式(IR),因为这种表示形式可以独立于具体的处理器架构。例如,x86汇编代码就过于复杂,因为它有太多的指令。一个解决办法是对小型的指令集进行分析。使用中间表示形式的时候,每个指令都被转换为几个原子指令。至于选择哪种中间表示形式,则取决于分析的类型。在大多数情况下,我们都会选择逆向工程中间语言(REIL),但是在一些学术文献中也有使用其他IR的,例如BAP([Bru11])或Bincoa([Bar11])等。
REIL IR只有17种不同的指令,并且每个指令最多有一个结果值。我们可以使用像BinNavi这样的工具将本机x86汇编代码转换为REIL代码,BinNavi是由Google(以前是Zynamics)开发的一个开源工具。BinNavi可以将IDA Pro的数据库文件作为输入,这一特性给我们带来了极大的便利。
符号执行与抽象解释
一旦将二进制代码转换为中间表示形式,我们就可以通过两种方法来分析这些二进制代码的行为了,即抽象解释([Gol10]和[Fei14])或符号执行([Ye14])。
符号执行使用符号值作为程序的输入,将程序的执行转变为相应符号表达式的操作,通过系统地遍历程序的路径空间,实现对程序行为的精确分析。因此,符号执行不会使用输入的实际值,而是采用抽象化符号的形式来表示程序中的表达式和变量。因此,这种分析方法不是跟踪变量的值,而是用代表变量值的符号来生成算术表达式,这些表达式可以用于检查条件分支等。
另一方面,抽象解释是基于这样的思想的——程序的分析可以在一定抽象级别上进行。因此,不需要跟踪每个变量的精确值,并且语义可以替换为描述指令对变量的影响的抽象语义。例如,变量可以由它们的符号来定义。对于加法指令来说,可以通过检查操作数的符号来设置结果的符号。因此,如果操作数的符号是+,那么结果的符号也是+,但是永远不会计算变量的确切值。除符号之外,我们还可以定义其他各种抽象域。例如,可以通过一个内存位置(全局,堆和栈)上的值区间来跟踪变量的值。值集分析(VSA)就是一种基于这种表示方法的分析技术。
举例来说,monoREIL框架就是一个基于REIL IR的VSA引擎。它极大地简化了VSA算法的开发工作,使开发人员能够在自己的抽象域上执行VSA。
分析中间表示形式
下一个问题是如何通过CFG时实现分析算法。同样,这里也有两种方式:
- 过程内分析,限于当前函数的范围
- 过程间分析,能够进入子函数
不用说,程序内分析要比程序间分析简单得多。然而,当一个人想要检测UAF漏洞时,他必须能够一直跟踪内存块:从这些内存块的分配到释放...,所以,有时候会涉及多个函数。
这就是为什么论文[Gol10]提出首先进行过程内分析,然后将其扩展到全局的过程间分析的原因。如图2所示,对于每个函数,都创建一个相应的方框。这些方框用来总结函数的行为,连接它们的输出与输入。因此,当将分析扩展到过程间分析时,每个函数调用都会被这个函数的过程内分析的结果代替。这种方法的主要优点是函数只需要分析一次即可,即使它们被调用了很多次也是如此。此外,在进行过程内分析时,即使非常小的代码块也不会放过,因此这种方法是非常精确的。
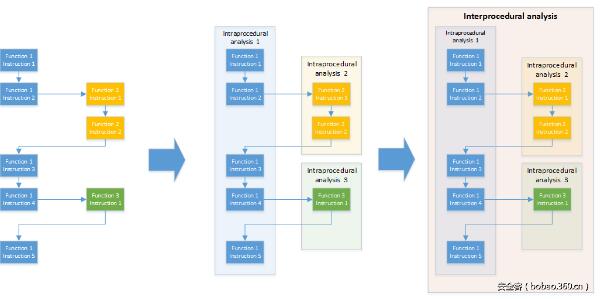
图2:由诸多过程内分析合并而成的过程间分析
此外,在论文[Fei14]中还提出了另一种解决方案。第二种方法(如图3所示)会将被调用函数内联到调用函数中。因此,函数调用不再是一个问题。虽然该解决方案更加容易实现,但是它有一个缺点,即如果一个函数被调用两次的话,则该函数将被分析两次。因此,该方法更加耗时,对内存的需求也更大。
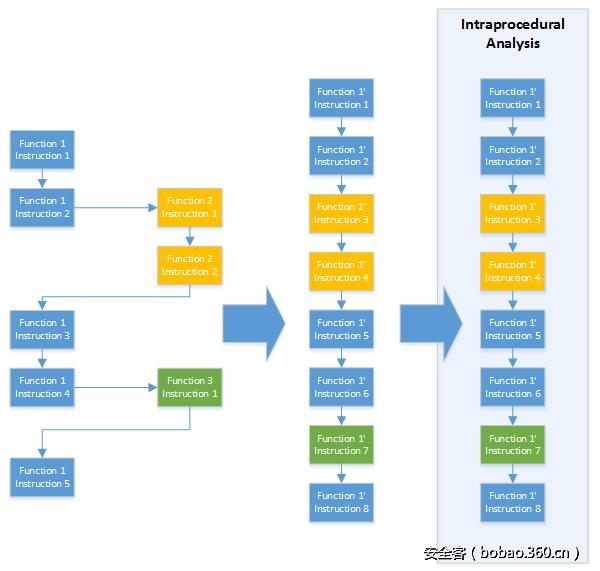
图3:通过将函数内联到单一函数中的过程间分析
检测UAF漏洞
在上文中,我们介绍了分析二进制代码语义的不同方法,以及遍历控制流图的各种方法。下面,我们开始介绍如何检测UAF模式。首先让我们UAF的定义,我们知道UAF是通过两个不同的事件来进行刻画的:
- 创建一个悬空指针,
- 访问该指针指向的内存。
为了检测这种模式,论文[Fei14]跟踪所有已经释放的内存堆区域,并且在每次使用指针时都会检查它是否指向这些已经释放的内存区。
下面,让我们拿下面的伪代码为例进行说明。注意,为了简单起见,该示例没有提供复杂的CFG。事实上,CFG的处理方法取决于所选择的分析方法及其实现...这个例子的目的,只是展示一种通过分析代码检测Use-After-Free的方法。
1. malloc(A);
2. malloc(B);
3. use(A);
4. free(A);
5. use(A);
上面的伪代码分配了两个内存块,并且可以通过名称A和B来引用这两个内存块。然后,访问(Use(A))了一次内存块A之后,接着释放(Free(A))该内存块。之后,又再次访问了该内存块。
通过定义两个域(一组分配的堆元素和一组释放的堆元素),可以在每个指令处更新这些集合,并检查它访问的内存是否属于已分配的内存块集合,具体如图4所示。
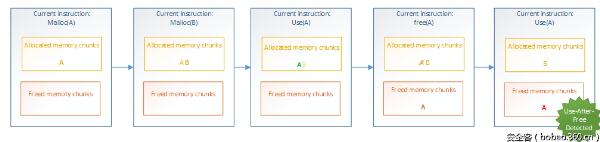
图 4:通过域检测机制挖掘Use-After-Free漏洞
当内存块A被再次访问时,它已经在上一步中被注册为已释放的内存块,因此分析程序就会发出警报:检测到Use-After-Free漏洞。
在论文[Ye14]中,它提出的另一种检测目标模式的方法,但是它使用的是简单状态机。该方法的思路是,在分配内存之后,指向该内存块的指针被设置为“分配”状态,并且该状态在相应的内存块未被释放之前保持不变。当内存块被释放时,它们就会转换为“释放”状态。当处于释放状态的指针被使用的时候,就会导致“Use-After-Free”状态。然而,如果指针及其别名被删除并且不再引用内存块的话,则它们就是无害的,这时就会进入“结束”状态。这个简单的状态机如图5所示。

图5:用于检测Use-After-Free漏洞的简单状态机
此外,在论文[Gol10]中也提出一个不同的解决方案,但是它使用的工具是图论。在这篇论文中,作者会对使用指针的语句进行检查,看看它是在释放内存的语句之后还是之前。如果是之后的话,就检测出了UAF漏洞。
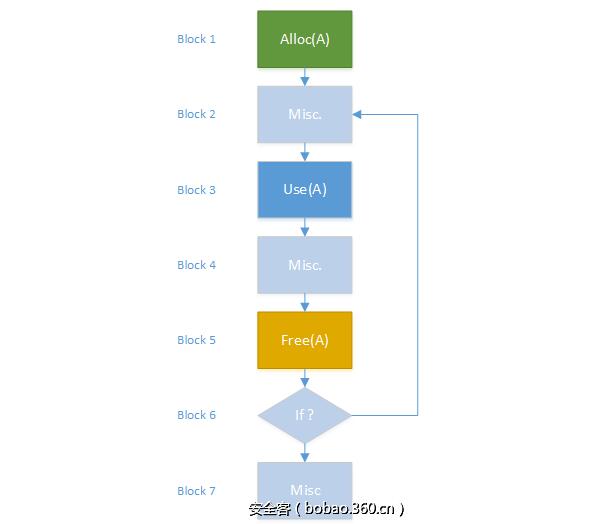
图6:具有潜在Use-After-Free漏洞的图
在任何情况下,只要检测到悬空指针,分析的最后阶段必须通过提取导致该指针的子图来表征UAF漏洞。这个子图必须包含所有必要的元素,来让人类手动检查,以避免真阳性。
总结
我们在这里介绍了几种通过基于静态分析的二进制代码Use-After-Free漏洞检测方法。同时,我们也对这种分析触发器的不同问题进行了详细的介绍,阅读之后您就不难理解为什么在检测这种bug的时候没有简单的解决方案了。
我们在开展这项工作中还发现,只有少数研究人员将其成果作为开源项目发布。Veribag团队的Josselin Feist开发的GUEB项目就是其中之一。如果对这个课题感兴趣的话,我们鼓励你访问他的Github。