今天和大家分享一下数据分析的一些基本思想,我给它起了个名字叫做用数据说话。内容都是个人的一些心得,比较肤浅!如有不足之处,希望大家谅解!废话不说了,现在咱正式开始。
用数据说话,就是用真实的数据说真实的话!真实也可以理解为求真务实。那么,数据分析就是不断地求真,进而持续地务实的过程!用一句话表达就是用数据说话,用真实的数据说话,说真话、说实话、说管用的话。
1.用数据说话
数据本不会说话,但是面对不同的人时,就会发出不同的声音。现在我们以《荒岛售鞋》这个老故事为引例,从数据分析的角度来解读,看看能不能开出新花?为防止大家案例疲劳,我尽量用新的表达方式把故事罗嗦一下!
话说郭靖和杨康,被成吉思汗派去美丽的桃花岛进行射雕牌运动鞋的市场拓展。郭靖和杨康一上桃花岛就惊讶地发现这里的居民全部赤脚,没有一个穿鞋的,不论男女还是老少,莫不如此。杨康一看,倒吸了一口凉气,说:唉!完了,没啥市场!郭靖却不这么认为,马上掏出了新买的IPHONE4G给铁木真打了个长途加漫游的汇报电话。
面对桃花岛这个空白的市场,郭靖电话里这么说:“桃花岛人口众多,但信息闭塞。现在全岛居民,全部赤脚。在运动鞋市场上没有任何竞争对手,茫茫蓝海,市场将为我独霸!可喜,可喜啊!”这个时候,咱现场做个调查,假如你是成吉思汗,你会怎么抉择?(投资Y1人,不投资的N1人。)
这个时候杨康听不下去了,马上抢过电话,说到“大汗,别听郭靖瞎嚷嚷!市场虽然没有竞争,但并不就一定是蓝海。在全球化竞争的大背景下,这么轻而易举的就让我们找到了蓝海,您觉得可能吗?难道阿迪、耐克、彪马、锐步这些国际巨头都是棒槌,会发现不了?
我看肯定是岛上几百年不穿鞋的生活习惯,短期内无法改变,所以各路群雄,都只能望而止步!可惜,可惜啊!”听了杨康的论述,铁木真又该如何选择呢?请大家举手表态。(愿意投资Y2人,不愿意投资的N2人。)姜是老的辣!成吉思汗比较理性,他只说了一句:“继续调研,要用数据说话!”就把电话挂了!
一个星期之后,杨康率先给BOSS汇报了。不过他没有选择打电话,而是改发EMAIL。原因有三:
- 一是全球通资费太高了,钱要省着点花;
- 二是杨康有点小人,他担心郭靖听了他的表述后,剽窃他的思想;
- 三是他写了一份详细的调研报告,电话里三言两语说不清。
杨康的调查报告里详细地记录了他与岛内精心选取的200位居民的谈话内容,以及他抽取居民样本时科学合理的甄别条件,最后的结论就是:岛内居民全部(100%)以捕鱼为生,脚一年四季泡在水里,根本就不需要鞋!听到这个消息,成吉思汗怎么办呢?请大家继续举手表态!(愿意投资Y3人,不愿意投资的N3人。)
成吉思汗有自己的想法。这个时候,他没有做决策,而是继续等。等什么呢?等郭靖的结论!又过了两天郭靖终于打来了电话。电话里说了3句话:“这个市场可以做!原因是岛上的居民每周都要上山砍柴,并且十有八九会被划破脚!更可喜的是,这两天他用美男计泡到了岛主的女儿黄蓉,而且黄蓉答应给射雕牌运动鞋作形象代言!”故事发生到这个阶段,我请大家做最后一次表态。(愿意投资Y4人,不愿意投资的N4人。)
好!数据在变,我们的决策也在变。不过,成吉思汗比我们理性的多。回答还是一句话,不过比第一次多了几个字:“继续深入调研,用详实数据论证。”为什么呢?难道这些数据还不够详实吗?是的!因为在成吉思汗脑袋里还存在有很多疑问。
比如:
- 难道竞争对手真的没来过?还是对方论证后真的不可行?
- 山上不会开个伐木厂吧?如果有了伐木厂,居民就不会上山砍柴了,到时候送柴上门,鞋还有个屁用啊!
- 为什么一周才上一次山?该不会主要使用的是太阳能吧?
- 运动鞋的运输成本、营销成本、销售成本是多少?投资收益率有多高?
- ……
听完这个案例,我想问大家一个问题!从数据分析的角度看,你受到了什么启示?请注意这里说的数据分析的角度,如果你得到的启示是:铁木真领导的郭靖与杨康不是1个老男人+2个帅小伙的Gourp,而是教练型的Team。那么,抱歉!这不是我们今天讨论的范围。好,在座的各位谁来表达一下自己的看法呢?
提示性的启示有:
- 面对同一个数据,不同的人会说不同的话。
- 真实的数据并不一定能推导出正确的结论。
- 正确的决策需要有充分的数据去论证。
- ……
这个案例涉及数据的搜集、分析、汇报以及用于决策的整个过程。在这个过程里,无论那个细节出了问题,最终做出的决策都将是致命的!所以说质量是数据的生命,在数据用于决策的整个过程,都必须保证真实有效!
2.用真实的数据说话
所谓用真实的数据说话,就是指在说话之前,先审核数据的真实性!现实生活中,拿着错误的数据还能大言不惭的可以说比比皆是。其中有两位杰出的代表:一个是传说中伟大的中国统计局,另一个就是动不动就要封杀这个封杀那个的CCTV。我不是瞎说,因为有数据支撑!
2010年1月20日,国家统计局公布了2009年全国房地产市场数据,全年房价平均每平方米上涨813元。够雷人吧!雷声还没过,霹雳紧跟着又来了!2月25日国家统计局发布了《2009年国民经济和社会发展统计公报》,数据显示,70个大中城市房屋销售价格上涨1.5%。真可是天雷滚滚!难怪网友把统计局票选成大天朝的娱乐至尊!
此话一出,央视不答应了!真所谓中国统计,娱乐至尊;央视不出,谁与争锋?那我们仔细推敲一下央视的数据。2010年2月15日,CCTV发布了虎年春晚的满意度报告,结果显示满意度为83.6%。几乎同一天,新浪的公布的调查结果是14.55%;后来没几天,腾讯也发布了满意度数据,结果是10.48%。
数据一出,网友们骂声不断,此起彼伏,一浪高过一浪。但是人家央视就是央视,大有敌军围困万千重,我自岿然不动的定力。更夸张的是央视不但能装作视而不见,充耳不闻,而且还继续恬不知耻地在自己家的那几个频道里卖弄数据,自娱自乐。到底央视的数据错在哪里?我们先审视一下央视的调查方法。
央视的调查结果,来自央视——索福瑞媒介研究有限公司。索福瑞号称他们电视观众满意度调查的样本覆盖了全国30个城市,抽样框总人数有30,000人,央视春晚满意度的调查就是从这3万人中随机抽取了2122人进行调查。这样看,严格意义上讲所谓83.6%的满意度只能代表3万人的看法。
当然,如果我拿这个说法与央视理论,对方肯定能拿出3万代表全国的理论证据。
具体就是先从2千推断3万,再用3万推及到30个城市,然后从30个城市推及至全国所有城市,最后再推及至全国。这里用到了简单随机抽样、分层抽样、典型抽样,总起来还是个多阶段抽样,多么冠冕堂皇的理论依据!但是,纵然每一步都能保证90%的可靠程度,四次推及下来理论的可靠程度也只有65%。可遗憾的是,最后一步用城市推及全国的做法在理论上还有一道坎,因为我们不知道如何用45%的城镇居民来代表55%的农村人口?
说完了代表性的问题,我们再看看调查方法。索福瑞采用的是电话调查,而且时段选择在春晚直播的那几个小时内。据说调查是从晚上8:30开始,一直持续到春晚结束。巨汗!8:30貌似90%的节目还没有上演,又怎么能调查到观众对整个春晚的满意度呢?
央视的数据是经不住推敲的!那么,新浪和腾讯的一定对吗?不一定,这两个数据也只能代表新浪用户和腾讯用户的春晚满意度,最多能够代表一下4亿网友,要想替13亿的中国人民表达心声,也恐怕是鞭长莫及。
欣赏了统计局和CCTV送给我们的两个开年笑话之后,我们自己也应该反思,咱们日常工作中,在从数据的搜集、提取、整理到分析、发布、使用的这一连串过程中,数据有没有失真?是不是数据自始自终都很齐全、很准确,而且统计口径与分析目的保持着高度的一致呢?这个问题留到日常工作中供大家思考。
3.说真话说实话
拿着错误的数据,肯定得不出正确的结论。那么面对真实的数据,就一定能得出正确的结论吗?未必!给大家看个小笑话。
问:你只有10平米的蜗居,邻居家从90m2换到190m2,你的居住面积有没有增加?
答:没有。
解:错,你们两家的平均居住面积是100m2,你的居住面积被神不知鬼不觉地增加了!
这个神不知鬼不觉是谁呢?无敌的平均数!仔细想想,这个均值算错了吗?没有!那么,问题出在哪里?单一的统计量存在片面性,所以要想反映数据的真实面貌,就得使用一系列统计量。
我再杜撰一个气候的例子,说明一下在结构严重失衡的情况下,使用平均数的可怕之处。我们的大中国啊,960万平方公里,同一时间里有的刮风,有的下雨,还有的高温酷暑。从去年冬天到今年的春天,北方一直暴雪连天,南方则遭遇百年旱情;而最近这段时间,南方多个省市河水决堤,沿河两岸,村庄沦陷,而北方则是烈日当头,干旱焦人,酷暑难耐。如果我们计算全年或者是全国降雨量的平均值,算出来的结果肯定是神州大地风调雨顺,国泰民安,而实际却是华夏民族饱经风霜,多灾多难!
还好,统计学家不只给了我们平均数,同时还设计了许多其他的统计量,大家看看下面这个表。

衡量数据的集中趋势,基本有三个统计量,均值、中位数和众数。均值是数值平均数,它容易受极端值的影响。也就是说如果数据的跨度或者说是极差不大的话,用均值可以很好的反映真实情况。但是,如果数据的差异比较大,单一使用平均数就会搞出新的笑话了。中位数和众数属于位置平均数,中位数是把数据从小到大排序,正好处于中间位置的那个数,众数是说出现的频次最多的那个数。
数据除了有集中趋势,还有离散趋势。反映离散趋势的统计量主要有方差、标准差、极差、变异系数等。方差就是观测值与均值差的平方和除以自由度,自由度一般是n或n-1。总体数据就用n,抽样数据就用n-1。标准差就是方差的正平方根,它的意义是消除了量纲的影响。极差是最大值与最小值的差,反映的是观测值的跨度范围。还有一个比较重要也是比较常用的就是变异系数,它是标准差与均值的比,目的是消除数量级的影响。
此外,还有一些是描述数据分布的统计量,比如分位数,有四分位、八分位、十分位等等,二分位就是中位数,它们反映一系列数据某几个关键位置的数值。频率分布,就是对数据分组或者是分类后,各组或各类的百分比。偏度是用于衡量分布的不对称程度或偏斜程度,峰度是用于衡量分布的集中程度或分布曲线的尖峭程度的指标。
如果想再深入一些的话,就会用到相关系数、置信水平、统计指数等等。相关系数是反映变量之间线性相关程度的指标,取值范围是【-1,1】,大于0为正相关,小于0为负相关,等于0表示不相关。置信水平是指总体参数值落在样本统计值某一区内的概率。统计指数就是将不能直接比较的一些指标通过同度量因素的作用使得能够比较,常见的物价指数、上证指数等等。
有了这些基本的统计量,我们在实际工作中只要稍微用心选择一下,就可以比较准确的描述数据的真实情况。
4.说管用的话
说管用的话是指深入分析数据的实质,挖掘数据的内涵,而不是停留在数据的表层,说些大话、空话或者套话。这就要求在数据分析时,首先明确分析的目的,其次是选择恰当的方法,最后得出有用的结论。通俗地说,说管用的话,就是不说屁话,少说废话!
4.1明确分析目的
这里我们举个例子。我想这个例子的时候正好是7月7号,N年前的那个时候,正好是在座的各位高考的日子,所以就杜撰了一个高考的数据。
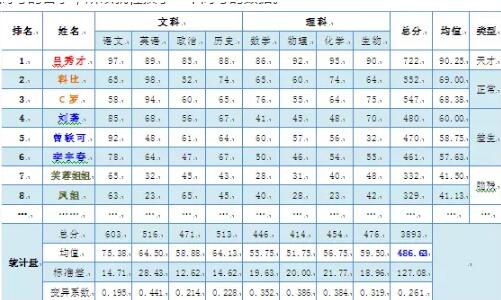
我们这个班级,虽然成绩很烂,800分的总分,平均成绩只有486分,但是人才辈出,名字一个比一个响,人气一个比一个旺。
大家先认识一下,有饱读四书五经,满腹经纶的关东秀才吕轻侯;有篮球场上进攻犀利,防守严密的小飞侠科比;还有足球场上无论是边路传中还是抢点射门都有非常出色的C罗纳尔多;有喜欢烟熏妆、蓝丝袜加高跟鞋出镜的伪娘刘著,有被亿万网友烧香膜拜的春哥党教主李宇春,还有经常抱着吉他哼着绵羊音的90后MM曾轶可;以及自称冰清玉洁、妖媚性感、擅长爆发性舞蹈动作的芙蓉姐姐和非清华北大经济学硕士不嫁、奥巴马也可的重庆籍奇女子罗玉凤!
基于学生的考试成绩,不同的人会关注不同的方面,高考的判卷老师会关心试卷的雷同程度,命题人会测试考卷的信度和效度,研究文理分科的专家会计算文理成绩的相关程度。但是对于普通中学,通常只会关心两个方面。一是学生成绩,计算升学率;二是教学水平,给优秀教师发奖金。如果高中的教学科在这里研究文理相关就属于废话,如果还要把问卷的信效检验也扯出来就是屁话了。
关于学生:
吕秀才:总分722分,班级第一,平均成绩超过90分,如果将其他同学的水平比作三层小楼的话,吕秀才应该是站在赛格顶上!奇才,上清华北大没有问题。
科比和C罗:总分550左右,平均不到70分!属于班级2号、3号人物,但成绩确实不咋地,不过在该班级中也算鹤立鸡群了。
刘著、李宇春、曾轶可:成绩较差,上学肯定不是她们的出路!基于平时性情怪异,男的像女,女的像男,还有一个像绵羊,建议别走高考这条寻常路,还是去湖南卫视选秀吧。
凤姐、芙蓉:这成绩,就是个脑残,估计脑袋不是被门挤过,就是被驴踢过!
关于老师:
衡量教师的优劣需要剔除异常值,吕秀才就是!吕秀才属于成绩异常出众,个人素质极高,所以他的成绩不应该成为衡量老师优劣的样本。
语文均值高,变异系数小!由此看出语文老师真是好老师!该发奖金!
同理,历史老师也不错!也应该适当奖励。至于物理老师,太差,得赶快换掉,绝对不能让他继续误人子弟了!
存在疑问的就是英语老师。英语成绩的均值较高,但变异系数大。这说明数据里可能存在极端值。可能的异常值是科比与C罗。科比美国人,外语自然好!C罗葡萄牙人,但从2003年到2009年一直在英国留学,6年啊,英语好也是应该的!所以,科比与C罗的英语成绩不能算是英语老师的栽培,所以科比和C罗是异常值,应该剔除。那么,剔除异常后就会发现英语的均值只有47分!说明英语老师并不能算做好老师,所以只能与奖金无缘了!
4.2选择恰当的方法
接上面的案例。如果我们是研究高中该不该进行文理分科的有关部门,那么我们该如何分析文理成绩之间的相关性?
举例1:如何计算文理科之间的相关性。
目前基本有三种方法,一是简单相关分析,二是典型相关分析,三是潜变量相关分析。
简单相关分析就是通过加总,分别计算出文科成绩总和、理科成绩总和,然后计算两者的简单相关系数。
典型相关分析主要用于衡量两组变量之间的相关性。它的基本原理是:为了从总体上把握两组指标之间的相关关系,分别在两组变量中提取是的相关系数最大的一系列典型变量,然后通过计算各对典型变量之间的相关性,来反映变量间的相关程度。
潜变量相关就是计算潜变量之间的相关系数。所谓潜变量是相对于显变量或者测量变量而言的。潜变量是实际工作中无法直接测量到的变量,包括比较抽象的概念和由于种种原因不能准确测量的变量。一个潜变量往往可以有多个显变量,潜变量是可以看做是其对应显变量的抽象和概括,显变量则可视为特定潜变量的测量指标。
在文理科相关性的分析中,我们可以将文科、理科看成潜变量,将语文、外语、政治、历史这四个显变量看成文科的测量指标,将数学、物理、化学、生物这四个显变量看成是理科的测量指标,那么求文理成绩之间的相关问题就转化成潜变量之间相关的问题。
那么。我们究竟该选用哪种方法呢?或者假如说我们同时使用了上面三种方法,求出相关系数,该选择哪一个呢?比如我们计算的结果分别是0.35(简单相关)、0.85(最大典型变量)、-0.65(潜变量相关),这个时候我们到底该相信哪个数据呢?
其实,我更愿意相信简单相关计算的结果。原因如下:
- 简单相关,既简单又易理解。
- 典型相关的取值范围是【0,1】,它计算出的结果没有正负,只有大小。与我们实际研究目的有悖。我们想知道学生是否在文理课程上均衡发展,所谓均衡就是正相关,所谓不均衡就是负相关。而典型相关做不到。
- 潜变量相关虽然取值范围是【-1.1】,但是它多数是采用主成分的方法拟合潜变量,而依据方差提取最大主成分的过程与我们的分析貌似不甚吻合。
- 最重要的是,其实简单加总与典型相关、主成分相关拥有同一个思想,就是先把多个变量拟合成一个变量(或几个),然后分析这个拟合出来的变量之间的相关性。其实,在量纲、数量级相同的情况下,而且权重也容易计算的情况下,最简单有效的拟合就是加总!所以我认为简单加总后计算出的相关系数是最有效。而潜变量、典型变量是在量纲或数量级不等的情况下,衡量多个变量之间相关关系的有效方法。
举例2:计算硬币正反概率
最后,再给大家做道选择题。
问题:如果一枚硬币连抛10次都是正面,问第11次出现正面的概率是多少?
选项:A. 接近0%B.50%C.接近100%D. 以上答案都不对
一个硬币连抛10次都出现正面的概率是0.510,绝对的小概率事件。在一次实验中,小概率事件发生,那么我们就应该拒绝原假设。原假设是什么?硬币出现正反的概率是0.5。所以,我们可以大胆地推断,硬币本身就是一个两面都是正面的硬币,所以说第11次出现正面的概率是100%,或者接近100%。大家是不是有异议呢?
树上10只鸟,猎枪一枪打死1只,树上还剩0只的结论大家都应该同意吧。因为我们考虑的是实际问题,不是10-1=?的数学算式。所以大家在幼儿园的时候就知道枪声响过,树上一只鸟都不会剩。试想,你和你的朋友打赌投硬币猜正反,如果10次之后朋友投出来的都是正面,你会怎么想?兄弟你出千了吧,硬币肯定有问题吧!相信用不了10次,你就会提出这样的质疑了。
如果说计算概率,0.5没有错,独立事件发生的概率不因之前的情况而改变。但是,如果用假设检验的思想,100%的结论就更合理了。之所以说0.5的结果不对,不是说你的计算出错了,而是在解决实际问题的时候,你太教条了,太书本了,从而选错方法了。
5.最后总结
分享结束了,大家也听了也笑了,但是笑过之后务必记住我啰嗦了一个小时的这句话:用数据说话就是用真实的数据说话,说真话、说实话、说管用的话!