Spark SQL与传统DBMS的查询优化器+执行器的架构较为类似,只不过其执行器是在分布式环境中实现,并采用Spark作为执行引擎。
Spark SQL的查询优化是Catalyst,其基于Scala语言开发,可以灵活利用Scala原生的语言特性方便地扩展功能,奠定了Spark SQL的发展空间。
- Catalyst将SQL翻译成最终的执行计划,并在这个过程中进行查询优化。
- 这里和传统不太一样的地方就在于,SQL经过查询优化器最终转换为可执行的查询计划,传统DB就可以执行这个查询计划了,但spark不同。
- Spark SQL***执行还是会在Spark内将执行计划转换为Spark的有向无环图DAG再执行。
Catalyst的整体架构
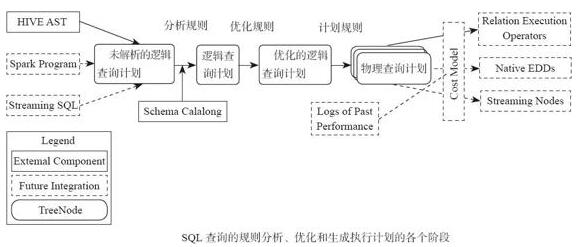
从图8-2中可以看到整个Catalyst是Spark SQL的调度核心,遵循传统数据库的查询解析步骤,对SQL进行解析,转换为逻辑查询计划和物理查询计划,最终转换为Spark的DAG执行
Catalyst的执行流程
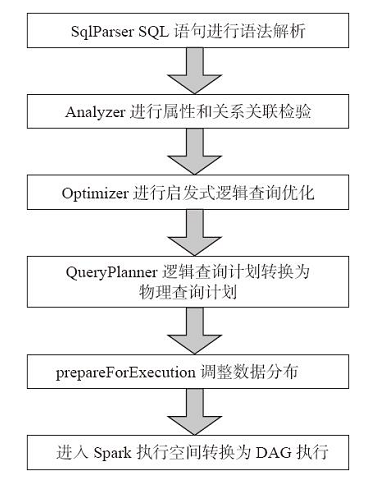
- SqlParser将SQL语句转换为逻辑查询计划
- Analyzer对逻辑查询计划进行属性和关系关联检验
- 之后Optimizer通过逻辑查询优化将逻辑查询计划转换为优化的逻辑查询计划
- QueryPlanner将优化的逻辑查询计划转换为物理查询计划
- prepareForExecution调整数据分布
- ***将物理查询计划转换为执行计划进入Spark执行任务。
【本文为51CTO专栏作者“王森丰”的原创稿件,转载请注明出处】