大数据时代,数据挖掘变得越加重要,曾经做了很多,成功有之,失败的却更多,举一些例子,探究其失败原因,也许于大家都有启示吧。
数据缺失总是存在。
为什么数据挖掘的数据准备工作要这么长时间,可以理解成取数时间很长、转换成所需的数据形式和格式时间很长,毕竟只有这样做,才能喂给数据挖掘引擎处理。
但数据准备的真正目的,其实是要从特定业务的角度去获取一个真实的数据世界,数据的获取比处理重要,技巧倒是其次了。
离网预测一直是很多业务领域关注的焦点,特别是电信行业,但这么多年做下来,其构建的离网模型却难言成功,为什么?
因为数据获取太难了。
离网预测希望用客户历史的行为数据来判定未来一段时间离网的可能性,但国内的电信市场并不稳定,不仅资费套餐复杂,大量的促销政策时时轰炸眼球,大家看得是热闹,但对于数据挖掘人员来讲,却是业务理解和数据准备的噩耗了。
因为业务的理解很困难,数据完全被业务扭曲,如果要预测准确,不仅自身业务促销的因素要考虑进去,还要考虑竞争对手策反政策、地域影响等等,你训练时看到的是一个简单的离网结果数据,但诱导因素异常复杂,这类因素相关的数据根本取不到或者难以量化。
比如电信离网很大程度是竞争对手策反、客户迁徙离网等等,你知道竞争对手何时推出的促销政策吗?你知道客户什么时候搬的家吗?你如何用数据来表达这种影响?你的数据能适应市场变化的节奏吗?
因此,如果某个合作伙伴来跟你说,我可以做电信行业的离网模型,那是个伪***,离网模型已经被电信行业做烂了,几乎没有成功的案例,即使一时成功也持续不了多久,只要业务不统一,就不大可能出现一个基本适用的离网模型,你无法想象全国10万个电信资费政策会对预测建模造成怎样的影响。
与互联网大一统的数据相比,其搞的风控模型显然要简单的多了,因为数据的获取难度和稳定度不在一个量级上。
数据挖掘,难就难在要为预测的业务提供跟这个业务相关的数据环境,因此,有时离网模型做不好,并不是模型师的错,也不是算法的问题,而是业务惹的祸,是数据问题。
你让开发出Alphgo的DEEP MIND团队来做离网模型,也是一个死字,这可能也是传统行业数据挖掘很难出效果的一个原因。
阿里的蚂蚁金服,所以能算法取胜,一个原因是它天生具有线上的资金往来数据,如果让它去分析传统银行的线下数据,估计难度也很大。
数据挖掘师特别强调要理解业务,就是希望你基于业务的理解能找到所需的解释数据,外来的和尚所以做不好,也是这个因素,因为打一枪换一个地方的方式,跟扎根理解业务的建模文化背道而驰。
数据准备,不确定性总是存在,因此一定程度上讲,这个世界是不可预测的,预测的能力,跟我们采集数据的能力成一定的正相关关系。
大数据的意义,就在于可以采集到更多的数据,这个决定了我们用机器解释世界的可能程度。
假数据真分析。
还是拿离网的例子,你就知道很多时候,所谓的解释数据,都是假数据,虽然你不是故意的,你还很认真,但因为受限于业务能力,决定了你只能使用假数据,结果可想而知。
以前新手,在做离网预测的时候,总喜欢拿订购成功的数据作为训练的数据,但这个显然是个大谬误。
要知道,大量的业务订购是套餐附带订购的,并不能反映用户的真实意愿,拿这个数据去训练,能训练出什么东西?这就是业务能力不够造成的现象。
现在互联网上估计这个现象很严重,比如刷单,这些假数据严重扰乱了模型,去伪存真是数据挖掘师的一个必修课。
但这个,可惜又跟业务能力相关,依赖于实践和经验,如果让市场部经理转行去做数据挖掘师,估计也很牛逼。
数据挖掘,难就难在这里,其是业务、数据甚至是技术的结合体,在大数据时代,这个趋势会越加明显。
缺乏对于“常理”的感觉。
以下是一个社交网络的案例,场景是需要对于两个通话(或其它)交往圈进行重合度判定,以识别两个手机号码是否属于同一个人。
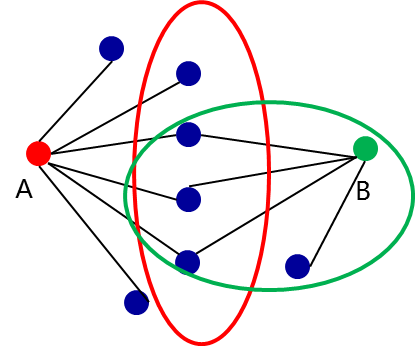
规则似乎很简单,但挖掘出来的结果却不尽如人意,准确率只有12%,百思不得其解。
后来发现判定重合度的阈值是30%,这个也不能说明有问题,但问题出在对于基数的判定上,大量的用户总的交往圈只有3-4个,也就是说,重合1个就可能达到这个阈值,很多新手或者过于迷信技巧的人,往往忽视业务本质的认识。
数据挖掘不仅仅是一门挖掘语言,还要有足够的生活认知和数据感觉,这个很难短期能够提升,依赖于长期实践,甚至认为,这个跟情商相关,有些人就是有感觉,一眼能发现问题。
缺乏迭代的能力。
很多传统企业,数据挖掘效果不好,跟企业的组织、机制、流程等相关,举个例子:
曾经给外呼部门做了一个外呼偏好模型,就是对于所有客户的外呼偏好排个序,在外呼资源有限的条件下,按照这个排序进行外呼,可以提升外呼效率,然后发布到标签库,然后让外呼部门去用,等待反馈的时间总是很长,大家都懂的,然后就石沉大海了。
最近想起来,再去要结果,发现效果很不错,能真正提升10个百分点啊,但已经2个月过去了。
这还算一个较为成功的挖掘,但又有多少模型由于线下流程的原因而被放弃了,谁都知道,数据挖掘靠的是迭代,很难***次就成功,但有多少星星在开始之时,就被掐灭了。
传统企业冗长的线下流程,的确成为了模型优化的大杀器,互联网公司天生的在线性让其算法发挥出巨大的价值,而传统企业的建模,往往还在为获得反馈数据而努力,组织、系统和运营上的差距很大。
推广是永远的痛。
很多传统企业不同地域上的业务差异,不仅仅造成管理难度加大、体验不一致、系统过于复杂、运营成本高昂,也让模型的建设和推广异常困难。
从模型本身的角度,不同地域的数据差异有时很大,在一个地方成功的模型,在另一个地方则完全失败,过拟合现象比比皆是。
从业务理解的角度,建模团队要面对几个甚至十多个做类似业务的团队,各个团队的业务理解上的差异和对于建模的要求各不相同,造成了建模团队的无所适从。
模型推广,成为了建模团队巨大的负担,复制模型,往往变成了重做模型,搜集结果数据也难上加难,数据挖掘,已经不是一项纯粹的活。
提了以上五点,只是为了说明数据挖掘所以难,是综合多种因素的结果,可能不是靠建立一个平台,懂得一些算法,掌握一个工具就能简单解决的,往往具有更深层次的原因。
我们在努力掌握好“器”的同时,也要抬起头来,更全面的看待数据挖掘这个事情,因地制宜的制定适合自己企业特点的数据挖掘机制和流程。
当然,大数据时代的到来,让平台,工具和算法也变得越加重要,这对数据建模师的知识结构也带来了新的冲击。
历史精选文章
- 不忘初心,大数据不是IT的狂欢! 阅读量:2160
- 我如何完成一本企业数据字典的编写! 阅读量:2580
- BI自助取数是怎么炼成的? 阅读量:1835
- 为什么BI取数这么难?阅读量:11500
- 为什么数据管理工作很难成功?阅读量:1900
- 为什么传统BI没前途?阅读量:4093
- 大数据,为什么不是传统BI的简单升级?阅读量:3400
- 数据分析师的自我修养 阅读量:1483
- 唯有数据创新,运营商才能实现大数据变现的突破?阅读量:1236
- 中国移动进军大数据征信,一个具有旅程碑意义的事件 阅读量:2380
- 为什么有些人用3年的时间获得了你12年的数据分析经验?阅读量:1874
- 数学中的“罗辑思维” 阅读量:1090
- 数据说谎的艺术 阅读量:2234
- 看上去很美,谈谈阿里云的大数据平台【数加】 阅读量:1281
- DPI大数据之战:运营商的艰难抉择 阅读量:2342
还有很多...