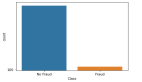
在机器学习中,不平衡数据是常见场景。不平衡数据一般指正样本数量远远小于负样本数量。如果数据不平衡,那么分类器总是预测比例较大的类别,就能使得准确率达到很高的水平。比如正样本的比例为 1%,负样本的比例为 99%。这时候分类器不需要经过训练,直接预测所有样本为负样本,准确率能够达到 99%。经过训练的分类器反而可能没有办法达到99%。
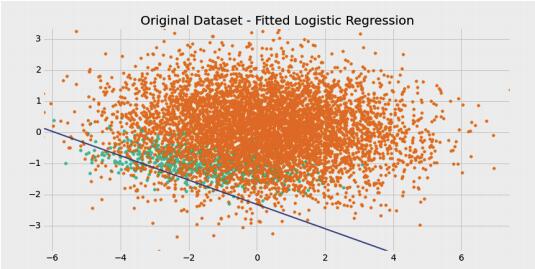
对于不平衡数据的分类,为了解决上述准确率失真的问题,我们要换用 F 值取代准确率作为评价指标。用不平衡数据训练,召回率很低导致 F 值也很低。这时候有两种不同的方法。***种方法是修改训练算法,使之能够适应不平衡数据。著名的代价敏感学习就是这种方法。另一种方法是操作数据,人为改变正负样本的比率。本文主要介绍数据操作方法。
1. 欠抽样方法
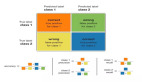
欠抽样方法是针对多数的负样本,减少负样本的数量,反而提高整体 F 值。最简单的欠抽样方法是随机地删掉一些负样本。欠抽样的缺点很明显,就是会丢失负样本的一些重要信息,不能够充分利用已有的信息。
2. 过抽样方法
欠抽样方法是针对少数的正样本,减少正样本的数量,从而提高整体 F 值。最简单的过抽样方法是简单地复制一些正样本。过抽样的缺点是没有给正样本增加任何新的信息。过抽样方法对 SVM 算法是无效的。因为 SVM 算法是找支持向量,复制正样本并不能改变数据的支持向量。
改进的过抽样方法则采用加入随机高斯噪声或产生新的合成样本等方法。根据不同的数据类型,我们可以设计很巧妙的过抽样方法。有 博客 在识别交通信号问题上就提出了一个新颖的方法。交通信号处理识别是输入交通信号的图片,输出交通信号。我们可以通过变换交通信号图片的角度等方法,生成新的交通信号图片,如下所示。

3. SMOTE
Synthetic Minority Over-sampling Technique (SMOTE) 算法是一个最有名的过抽样的改进。SMOTE 是为了解决针对原始过抽样方法不能给正样本增加新信息的问题。算法的思想是合成新的少数类样本,合成的策略是对每个少数类样本a,从它的最近邻中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本。

4. 总结
从理论上来说,SMOTE 方法要优于过抽样方法,过抽样方法要优于欠抽样方法。但是很多工业界场景,我们反而采用欠抽样方法。工业界数据量大,即使正样本占比小,数据量也足够训练出一个模型。这时候我们采用欠抽样方法的主要目的是提高模型训练效率。总之一句话就是,有数据任性。。