












2016年12月8-10日,由中国计算机学会(CCF)主办,CCF大数据专家委员会承办,中国科学院计算技术研究所、中科天玑数据科技股份有限公司与CSDN共同协办,以“聚焦行业最佳实践,数据与应用的深度融合”为主题的2016中国大数据技术大会在北京新云南皇冠假日酒店隆重举办。
中国移动苏州研发中心大数据部总经理,高级工程师钱岭在主题演讲《大数据研发历程的回顾和思考》中分享了一个大数据实践者所走过的历程,主要包括三方面内容,(1)对大数据理解的变化;(2)大数据实践历程回顾;(3)大数据发展方向思考。
一路走来,中国移动苏州研发中心对大数据理解在不断深化。2007年,将大数据称为大规模并行计算、云计算。2010年之后,大数据被按照3V~7V来定义。3V,即规模大(Volume)、种类繁多(Variety)、处理速度要求高(Velocity)。而到了2014年前后,开始跳出技术的视角来审视大数据。除了继续关注技术外,开始关注大数据源、大数据工程师/科学家、大数据服务、大数据“众包”、大数据咨询。2016年,则开始以数据为中心来审视大数据,并将数据形象比喻为管道中的水,其汇聚到数据工厂,自动可视化,展示用户希望的信息,告诉用户潜在的规律,甚至智能地完成工作,这也中国移动苏州研发中心大数据平台正在做的工作。至此,中国移动苏州研发中心对大数据有了更全面的认识,用一个公式表示便是:大数据 = 业务 + 数据 + 平台 + 算法,所有大数据工作也将基于这四个方面展开。
伴随着对大数据理解的不断深入,对大数据的实践也在不断前行。2007年,从学习Hadoop入手,进入大数据领域;2008年,深度改造开源软件,目标是商用产品;2009年,跟随开源社区的发布,但是依然深度定制;2010年,以大云1.0为起点,正式开展商用部署;2011~2013年,每年发布新版本,并增加新“产品”;2014年,重新规划大数据产品体系,引入管理平台。而这个过程,也走了很多弯路,大多是因为开源社区、自主研发两大技术路线及技术驱动、需求驱动两大研发方向的选择偏差导致的。当前主要选择了基于开源,技术驱动的研发方式。
以下为演讲实录
各位嘉宾上午好!我来这里也不是一次两次了。刚才两位嘉宾也介绍了一些比较严肃的课题,这些课题可能涉及到精准医学,也涉及到天气预报或者自然灾害的防治,这些问题我想现在可能不一定很好的解决方案,但根据技术的发展和这个业务的进步,一定会找到一个很好的方案的。正如我们自己是怎么样通过这九年以来一点点什么也不会,到能做很多的事情。
我今天的汇报分三部分,一是对大数据理解的变化,为什么讲这个呢?因为这个会直接影响后面的研发方向、工具选择或者研发的思路。二是讲一下到底踩过什么样的坑,取得什么样的经验。后面是什么样的思考和想法。
对大数据理解的变化
这件事,我们开展得很早。2007年初的时候开始关注云计算,但那个时候我们并没有叫大数据,那时候也没有这个词。那时候称为大规模并行计算或者云计算,因为主要的研究对象是跟Hadoop相关的事情,Hadoop本身是云计算的技术,并没有用虚拟化技术,而是用队列和槽位作为逻辑资源来调度任务。那个时候用13台计算机来进行排序或计数,那时候成立了一个小的团队,他们开始阅读Hadoop整个系统的源代码,那时候版本是0.16版本。
就这么过了好多年,Hadoop是研究实验为主,2008年之后发现大数据慢慢成型了,但还是以云计算的名义发展,2010年之后提出三维、四维。我们自己做这个事的时候,考虑了为什么要做这个研究?因为很难说服我们公司里面的直达部门,他们觉得IOE架构也挺好的,但有两件事做不了,一是大数据实时处理计算,那时候云计算虽然不太多,但公认的是数据库做不了。第二,非结构化数据的管理,但后来做了很多的扩展就可以支持了。2013年对大数据的理解也是一塌糊涂,每个人都在做,但都不知道为什么要做大数据,那个时候本质上都在做云计算,其实没有人考虑行业应用的这些问题。
2014年前后我们也开始考虑这个问题,什么是大数据,开始跳出技术的视野,因为以前总是集中在Hadoop这个领域,或者流计算,数据挖掘,始终认识上是片面的。后来我们从数据源、大数据技术和人这几个维度关注大数据到底是什么。数据源就是数据的来源,技术我们也做了很多年,人就是大数据科学家。当时有一些企业把大数据科学家定义为CIO、CEO,此类评级的角色能做很多的事情,能决定企业的发展方向,现在看来也都是泡沫。
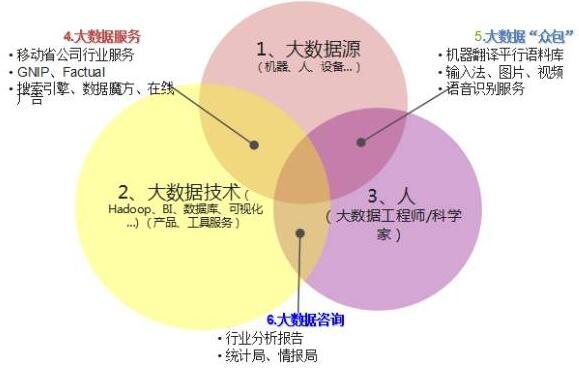
在大数据技术与数据源的交界处(见上图),如果一个企业拥有数据源也有大数据技术,可以做大数据服务,把数据加工一下作为产品卖出去。第二是人和大数据源,可以做大数据众包,像一些图片、视频、语音识别,都是用大数据众包来潜移默化地影响这些产品。如果有大数据技术和人,可以做咨询相关的工作。
这里有三个误区吧,第一个误区是对V的过于强调,大家总是关注数据量大,快速,样子很多也不准确,忽略了高性价比的系统。所以那个时候有一个情况,有点什么小需求很可能就要建一个很大的数据中心集群来满足数据的采集,然后把它做成报告。我算了一下这个报告一年二三十万,可投个集群一两千万的系统设备,当时并没有人考虑这个性价比,所以为了满足独立的应用目标,我们做了点状应用。带来问题是投入比较大,数据不能共享,资源不能共享,造成成本的经济效益都比较差,没法长期的做一件事。在开始泡沫期鼓吹,到真正用的时候用不上。混合部署,我们后续产品的设计或者业务的发展也是以混合部署作为最基本的基线做的。
第二个误区是数据和应用是紧密结合的,这也是我们在找业务的时候发现的重要问题,往往在比较长的时间里,因为大数据充满了神秘感,谁也不知道能干什么事,一想大数据很大,反正也不知道怎么用。问题是数据的需求到数据的挖掘周期特别长,像移动做秋季营销,学生入学需要做营销,如果这个营销两个月前提出需求来,看后端能不能配合,就开始取数据。往往营销活动都结束了,数据还没弄完了,这种情况会造成很大的影响。这样没有一个简单的工具层面的东西,或者平台层面的东西,能满足一线用户的需求,我们认识这个响应速度非常慢,也是一个非常重要的问题。
这一块其实人家定义都很清楚,只是我们理论不够深,是说要有一些创新方法来解决问题,什么是创新的?还是观察一下成功案例。在成功案例里,最终是为最终用户提供了简单易用的自助数据分析工具,我们是给用户提供开发平台,而不是给开发人员使用的。
第三个误区,很多人误以为Hadoop软件免费了,再也不用操心了,其实不是,还需要很多的优化。我们很多的传统行业都是厂家干活儿的,他不关注系统优化,你给我多少钱就走了,就缺乏这个持续优化,确实大数据特别是开源产品,如果缺少这个,那业务无法持续发展。我们做过一个实际比较,优化前是什么效果,总说需要优化,还有一些眼边的数据,全部抓过来,为什么不精简呢?造成系统覆盖很高,需要扩容,全是假象。这给我们另外一个启示,这个东西很多实验表明需要自己干,而是说移动自己的人,比如用户自己需要有这个能力,他去做一些优化、判断,这样能解决很多的问题。
这三个误区进一步的思考,我们到2016年的时候开始做新的思考。大数据到底是什么东西,如果不清楚的话我们也很难推广我们的技术,也不好定位。一是中国移动的大连接战略,这个战略是今年才提出来的,主要目标是不断拓展连接的广度和深度,做大连接的规模,做强连接的应用数量。计划是到2020年的连接数量要超过2015年一倍的水平,那也就意味着连接数量快到头了,那就需要考虑到车的身上,猪、牛、羊的身上,可能不会打电话,但是需要连接,这个连接对移动来说需要做营运,但对做大数据的人来说就是大数据。任正非也提出来,假设数据量的流量会变粗,变的像太平洋一样粗,如果真的这样的话,华为就押对这个宝了。连接,一个是终端的问题,第二个管道的问题,西安提出“云管端”,我们可以预测电信行业、通信领域,包括其它也差不多,在这种强烈的需求驱动下,会把数据量越做越大,大到什么程度?我们认为如果超过一定程度以后,你去分析的数据或者寻找数据的难度越来越大,什么是大数据平台?什么是大数据中心?大数据中心我们认为就像一朵云似的,数据就像管道上的水,汇聚到工厂,自动可视化展现用户需要的讯息,告诉用户潜在规律,甚至智能化的完工作。
对于可视化这部分,现在我们的理解是让业务人员去做可视化报告,工具过于复杂根本不切实际。展现用户需要的数据,你不去做挖掘至少去做统计分析,把信息呈现给用户。告诉用户潜在规律,这个规律你需要做数据挖掘,是数据信息向知识性发展,这里面数据挖掘算法我们做了很多,但发现用户不太会用,这又回到前面误区二了。最后是智能化工作,这样对大数据就慢慢清楚了,把这个再细化一下变成四个东西。
大数据是什么?大数据是业务+数据+平台+算法。
业务:内部有BOM、采购、内审、信安、人力、财务、基建。外部有金融、政务、互联网、旅游、交通。
数据:内部有互联网、政府、交通、政务、电信、联通。外部有BOM、视频、音频、尤其DPI数据。
算法:结构化数据——三大类挖掘算法机器学习;非结构化数据——NLP;多媒体数据:深度学习。
平台:大数据平台,架构——两域四层,采集、计算、存储、能力开放、供给、管理、运维、安全。来源——开源、自研、商业软件。
大数据就是业务+数据+平台+算法,在这之后的事情所有的开发工作或者研究工作都会基于这个思维开展。
大数据实践历程回顾
2007年我们从学习Hadoop入手。我们用的是0.16版本,后半年0.17点版本出现的时候,Hadoop已挺烂了,现在看来谁敢用它做商业版的话,这是吃了熊心豹子胆的。第一,成熟性比较低,第二,资源隔离也比较差,但是解决了可扩展问题,后续开展了大量的实验室测试工作256~1024节点,获得大量经验。
当时规划的几项工作都转了后续产品,但是并不那么一帆风顺,其中大规模计算管理系统孵化成为云计算集群管理系统,成为通用的系统。大数据平台Hadoop、搜索引擎SE、大规模计算管理。
2008年,深度改造开源软件,目标是商用产品。Hadoop-NN HA、HBase-Master HA,SQL over HBase数据挖掘算法并行化等特征性在2008年都是大大超前于社区的,进而形成了自己的发行版和相关产品。
2009年,跟随开源社区的发布,但是依然深度定制。随着社区的成熟,Hive等新开源软件的出现,调整技术路线继续研发大云SQL Over Hadoop、Parallel Data Mining、Search Engine,内部发布0.5版本,并且在上腔、江苏等省公司开展实验试点。效果优于传统的IOE系统。
2010年:以大云1.0为起点,正式开展商用部署。经济试点,定义了四项大数据产品(并未将Hadoop看作独立产品),可以开展点状大数据应用,Huge Table在中国移动第一朵云,“WAP彩信双业务云”获得商用,承载WAP和彩信系统生成的日志数据,用于后端查询分析。
2011~2013年:每年发布新版本,增加新产品。陆续引入了图计算、大数据平、NoSQL数据库,内容分析和知识库等五项产品/原型,并将Hadoop作为独立产品,与若干单位合作Hadoop开源社区,支撑盘古搜索上线,在福建、辽宁等省公司获得点状应用,一直到大云2.5版本。
2014年,重新规划大数据产品规划体系,引入管理平台。孵化成立苏州研发中心,重新定制跟随开源社区的技术路线,规划两域四层的产品体系,针对性开展研发,启动大数据管理中心(BC-BDOC)产品,整合现有各种点状应用,并提供更多的能力开发能力,同时开展围绕数据的开发。
这些年我们也走了很多弯路,主要有几个方面引起的,一是技术路线选择上出现了偏差(是开源还是自主研发),我坚信一点,这一走过的坑在人工智能和区块链一样会出现,只不过是深浅的问题。在技术路线上的选择,最终建议跟随开源社区的方案来做这个事情,所以我们也看到很多的缺点,第一,跟随开源社区,投入少,启用快,只要一个小组研究它的代码就好了,很快就可以把这个系统全整明白了,具有很快的交付能力。出现问题的话,因为它开源也可以独立解决,如果实在搞不定也可以找社区解决。缺点,开源软件很大的问题是质量良莠不齐,要做很大的测量工作。还有一个问题,掌控需求和研发计划能力非常弱,虽然社区里有一个里程碑,但里面是这些开源企业自己开户需求的里程碑,并不是我的客户的需求里程碑,研发计划也是照它的来的,所以有时候不得不用其他的需求解决这个问题。接口上也有很大的问题。
自主研发优点是容易控制节奏、需求,但缺点是投入很大,启动也很慢,至少做半年到一年才可以做出一个好的东西来,还有相关的配套等一些东西。
技术驱动就是解决某一个问题的,很容易立项,但那个跟其他产品界限也非常清楚。缺点可能不是业务需求,不能落地。所以我们早期是自主研发驱动的,后期是业务驱动来孵化这个产品。
大数据发展方向思考
最后讲一下思考吧,有的未必是很成熟的思考。第一是商业模式的思考,讲了半天大数据怎么挣钱,我们发现大数据的商业模式逐步清晰,一般在生态圈里为了扩展自己数据的维度,提升价值,一个单位通常既是生产者也是消费者。所以我们现在也开始跟一些有优质数据的客户开始交流,看看能不能交换数据或者采购数据,来弥补我们数据的不足。这样的话就会在六种商业链之外形成很多复杂的商业模式组合,一开始是工具和服务提供商,运营在线大数据工具服务,提供API或者DAAS服务,运营免费大数据服务+后向广告,运营收费大数据服务,像舆情分析;运营大数据交易市场。
下面是我们对大数据系统的演进历程的判断。
- (1)数据:种类不断增加,集群数据接口大幅度增加,希望最终形成多数据管理、上下游关系;
- (2)集群功能不断增强,最终会从点状应用整合为统一大数据平台,从离线转向实时;
- (3)数据规模不断增加,集群扩容能力不足,最终形成多集群统一管理的架构。
我们对大数据产品体系和解决方案总揽,目标是构建健壮、可扩展、开放的,功能丰富的大数据平台,基于开源、MPP等软件,面向公司内外提供DaaS、PaaS和SaaS服务。
说一些相当重要,但是不太成熟的大数据技术举例。
数据安全:大数据安全需要哪些特征,如何与大数据整合在一起,如何提高效率,如何解决真实的业务需求。
人工智能,人工智能算法目前应用领域还集中在互联网领域,点状系统,成本也较高,如何形成统一的大数据能力,和与海量数据结合,如何为业务服务。
可视化:如何在现有图表呈现之上,艺术设计之下的空间中寻找合适的可视化技术,便于算法结果的呈现。
很高兴和大家一起关注大数据过山车的起起伏伏,谢谢大家。
















