要正确的优化SQL,必须能快速定位性能瓶颈点,或者说快速找到SQL主要的开销所在。最慢的设备通常是瓶颈点的成因,如文件下载时的瓶颈点可能是网络速度,本地文件复制时的瓶颈点可能在于硬盘性能。
为了快速找到SQL的性能瓶颈点,首先需要读者对各种设备的性能数据有一些基本的认识,如千兆网络带宽是1000Mbps,硬盘转速为每分钟7200/10000转等。
下图数据给出了一些当前主流的计算机性能指标。
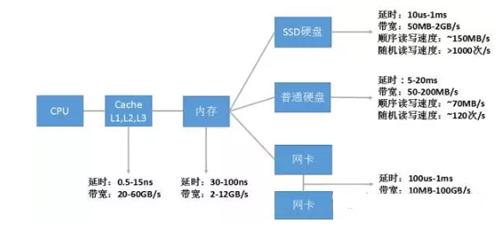
图1 I/O各层次硬件性能汇总
如上图所示,每种设备基本上都有两个重要指标:
- 延时(响应时间):反映硬件的突发处理能力。
- 带宽(吞吐量):反映硬件持续处理能力。
通过比较这两种指标,可以发现计算机各系统硬件性能从高到低依次为:CPU→Cache(L1-L2-L3)→内存→SSD硬盘→网络→硬盘。
比较性能之后,我们再看一下每种硬件在Hadoop系统进行SQL运算时负责的主要工作:
CPU及内存:缓存数据访问、比较、排序、事务检测、SQL解析、函数或逻辑运算、JOIN、数据加解密、加解压等;
网络:结果或者Shuffle数据的传输、SQL请求、远程数据访问等;
硬盘:数据访问、数据写入、日志记录、外排序、Shuffle等。
将以上陈列的各硬件性能指标及其工作内容结合考虑,在Hadoop集群中提升SQL的执行性能就是要尽量做到以下四点:
- 减少数据访问(减少磁盘访问)
- 减少中间结果量(减少网络传输或磁盘访问)
- 减少交互次数(减少网络传输、减少调度开销)
- 改进算法,减少服务器CPU开销(减少CPU及内存开销)
注:实际优化时,除了以上四点还应注意任务分配要均匀且大小适中。
总而言之,优化的基本思想就是反复迭代,合理利用资源,综合平衡各种开销,以求达到***效果。下面将简单介绍这四种优化思路,以及分别可采用的方法。
1. 减少数据访问
传统关系型数据库例如MySQL、Oracle等,通常通过提供索引来实现减少数据访问、提升访问速度,但是由于Hadoop不维护键(Key)的特性,因而SQL on Hadoop引擎一般不提供对传统索引的支持,或者功能不像传统索引一样完备。
为了达到和索引相似的优化目的,即加快过滤扫描,SQL on Hadoop产品通常提供其他功能用以弥补。以星环科技的Inceptor为例,其本身并没有可用于控制的传统意义上的索引,但是提供了分区、分桶,以及MinMaxFilter、BloomFilter以及RowFilter等用于批量过滤数据的过滤器。这些功能的原理通常是通过把相似、相关或者相等的数据进行归类以减少查询搜索的范围,或者建立基于列式存储的扫描方式尽可能的减少无关数据的读取。使用者需要结合实际语句,把这些功能进行高效组合,合理运用在刀刃上。
2. 返回更少的数据
返回更少的数据就是要求在构造SQL语句时,只SELECT需要的列。因为每个字段的提取都是一个复杂的解析过程,且占用内存,所以为了减少不必要的查询时间,请读者***仅返回需要的字段。比如减少“SELECT *”的使用,因为大多数情况是不需要所有字段的数据的。
【例1】如果某用户提交了这样的语句,但是实际需要的只有id、name两个字段:
- SELECT * FROM product WHERE company_id = 456723
- LIMIT 100;
为了加快执行速度,建议将语句写为:
- SELECT id, name FROM product
- WHERE company_id = 456723
- LIMIT 10;
另外若SELECT的结果是用于判断某些条件是否成立,例如EXISTS操作,就更加没必要返回所有数据:
【例2】某个包含关联的语句,在优化调整前,EXISTS内部返回了满足条件的所有字段值:
- SELECT … FROM table_name_2 WHERE
- … EXISTS (
- SELECT * FROM table_name_1
- WHERE table_name_1.col1 = table_name_2.col1
- );
但是EXISTS的返回仅用于判断满足条件的记录存在与否,所以EXISTS内部无需返回所有字段。因此可以将EXISTS子句中的“SELECT *”优化为“SELECT 1”:
- SELECT … FROM table_name_2 WHERE
- … EXISTS (
- SELECT 1 FROM table_name_1
- WHERE table_name_1.col1 = table_name_2.col1
- );
3. 减少交互次数
减少交互次数就是减少网络通信的交互次数。这里分享与此相关的三种优化情况。
Batch DML
批量方式处理DML可以大幅度减少和服务器的交互次数。Inceptor数据库访问框架提供了批量提交的接口以服务于大量插入数据。当用户一次性往一个表中插入1000万条数据时,试想如果采用普通的Insert,将和服务器发生1000万次交互,按每秒钟向数据库服务器提交10000次估算,完成所有工作需要消耗1000秒。但是如果采用批量提交模式,每1000条提交一次,和服务器的交互次数就减少至1万次,交互次数大大减少,耗时缩短为原来的千分之一。
采用Batch操作虽然不会大量减少数据库服务器的物理I/O,但是会大幅减少客户端与服务端的交互次数,从而降低多次发起的网络延时开销,以及数据库的CPU开销。
In List
进行数据扫描时,有时会遇到这样的情况:到手多个ID,需要查询与这些ID相关的记录。有两种方式实现:单条提交或者批量提交。
单条处理就是采用一个ID发一个请求的方式传送给数据库:
- for: var in ids[] do begin
- SELECT * FROM table_name WHERE id=:var;
- end;
这种方法会增加与服务器的交互次数,显然和减少交互次数的思想背道而驰,固然是不推荐的。建议用ID InList的方式批量提交,可以把多次交互压缩在一次访问中完成,加速查询:
- SELECT * FROM table_name
- WHERE id IN ids[];
使用存储过程
Inceptor支持存储过程,合理的利用存储过程有助于提高系统性能。存储过程是由SQL语句组成的完成特定功能的代码块。每个代码块在创建时都需要命名,用户通过访问对应名称调用它们。存储过程中的代码都是已经编译过的,所以调用的时候可以跳过编译阶段直接执行,而且由于其直接存储在数据库中,可以避免SQL语句的重复传输。
总体而言使用存储过程有以下两方面的好处:
减少编译次数提高了执行效率。
在网络交互中代替了大量的SQL语句,使用者只需传递一些必要参数,帮助减少网络通信量,提升通信效率。
4. 减少数据库服务器
CPU运算SQL中会包含各种各样的操作和计算要求CPU参与运算,其中有一些计算并非必须,可以人为避免。例如,进行对比运算时,对于不匹配的类型,系统要对操作数进行类型转换,导致加重CPU负担。所以,对于数字和日期类型,建议用户在执行计算前先进行类型转换,使各操作数的类型匹配,或者建表时尽可能的把字段规划成相同的数据类型。
另外,对于SQL中的逻辑运算符,Inceptor通常对普通比较运算符(如等于、不等)有较好的表现,但是对于服务器CPU需求量很高的操作,需要用户保持警惕。如LIKE操作,该模糊查询对CPU的要求一般较高,特别是检查的记录有上万条及以上时,系统表现比较糟糕。建议用户根据业务语义尽量用In-List实现LIKE,在In-List中包含LIKE所有可能的匹配选项。
【例3】如下所示模糊查询语句:
- SELECT * FROM table_name
- WHERE column_name LIKE ‘%abc%’;
若已知该列字段值仅有三种取值‘cabc’、‘abce’、‘cabe’,上面的语句可以等价为这样的表达方式:
- SELECT * FROM table_name
- WHERE column_name IN (‘cabc’, ‘abce’, ‘cabe’);
【例4】如果In-List数据可用一条SELECT语句查询得到,***让一张中间小表作为In列表内部数据,然后采用内外查询关联的方式进行检索:
- SELECT * FROM table_name
- WHERE column_name IN (
- SELECT col_name FROM tbl WHERE gender = ‘f’
- );
总结本文分享了四种在Hadoop平台中常用的SQL优化思路,实际上每种思路在具体应用时都可以引申出很多不同的方法,介绍这些思路的目的在于为用户在选择SQL优化手段时提供一些明确方向。
***大致总结一下这些优化思路的适用场合:
- 在过滤扫描阶段考虑如何减少数据访问;
- 构造SELECT子句时应思考应该如何减少返回数据;
- 当执行涉及向服务器发起交互请求的操作时,应当选择减少交互次数的合适方法;
- 必要时进行人工处理以减少不必要的CPU计算。
如果用户能够考虑并兼顾这四个方面,相信由此构造的SQL语句会在Hadoop平台中有更好的执行性能。