即使以大规模并发方式访问数据集,128台计算节点的模拟处理速度仍然不够理想,这样的难题该如何解决?
如果由DDN公司给出答案,那么结果必然是采用闪存缓存构建缓冲区; 当然,亦可尝试选择基于NVMe闪存驱动器的虚拟SAN,而这正是美国宇航局的解决思路。
美国宇航局的先进超级计算(简称NAS)设施位于美国宇航局艾姆斯研究中心之内。其高端计算能力项目(简称HECC)旨在帮助科学家与工程师们利用超大规模建模、模拟、分析与可视化方案确保美国航空局的各太空任务得以成功完成。
作为项目的组成部分,宇航局方面开发出Hyperwall系统,这是一台纵向16列、横向8排的超大显示屏幕,用于显示大规模场景下的可视化模拟结果。其模拟对象包括多个项目,例如涉及大量流场寻路计算的ECCO(即海洋循环与气候评估)。此类模拟任务通常涉及规模庞大且由美国宇航局超级计算机与各类仪器生成的高维数据集。
科学家们能够利用多种不同工具、视点以及参数以显示同样的数据或者数据集,并通过可视化机制检查模拟结果。
目前的问题在于,Excelero的NVMesh存储方案如何以理想速度支撑起Hyperwall庞大的128台显示器与130个计算节点(128台计算节点加2台后备节点)。之所以如此困难,是因为其中涉及庞大的数据集与大量规模较小且极为随机的IO操作。磁盘驱动器采用的Lustre文件系统表现不力,这套理论性能可达每秒80 GB的文件系统在实际数据吞吐量方面仅可提供每秒100多MB的表现。

美国宇航局艾姆斯Hyperwall可视化多屏幕显示器
Hyperwall中各计算节点都配合一块2 TB闪存驱动器。程序员们会将整体数据集拆分为2 TB甚至更小的分块,并将其复制至各计算节点当中。在此之后,整个可视化流程即可确保计算及交互操作利用本地数据进行,但这种作法会显著提升编程复杂度。
场流寻路涉及两项核心技术:
• 利用核内方法处理内存内或者闪存等高速本地介质中的数据。
• 当数据被移动至计算节点之外,即访问时间更长时,使用核外技术进行处理。
缓慢的模拟速度意味着科学家与工程师们只能以较低效率使用Hyperwall可视化方案。正如excelero所言,这正是NVMesh技术的专长所在。

ECCO模拟显示结果
NVMe 虚拟闪存SAN
如果全部128个节点上的2 TB闪存驱动器被整体汇总为单一资源池,即单一256 TB逻辑设备,并作为虚拟闪存SAN供RDMA访问,那么每块闪存驱动器在实质上都将成为各计算节点的本地存储资源。对于计算节点应用而言,直接访问网络设备目标并利用RDMA能够实现良好的并发读取效果。
美国宇航局艾姆斯 研究中心的可视化小组安装了NVMesh方案并借此获得了中央块存储管理能力——包括逻辑分卷、数据保护与故障转移等等——且无需受到传统SAN的性能限制。Excelero公司指出,这将为可视化、分析/模拟以及突发性缓冲区使用等层面的各类用例提供理想的性能、经济性与可行性提升效果。
NVMesh拥有以下三大主要模块:
• 其中存储管理模块为一套集中式基于WebGUI的RESTful API,负责控制系统配置。
• 目标模块可安装在任意主机之上并共享其NVMe驱动器,通过客户端对各驱动器进行初始连接验证,而后保持这条数据路径。
• 客户端块驱动器运行在各需要访问NVMesh逻辑块分卷的主机/镜像之上。
在混合部署场景之下,客户端与目标模块可共存于同一服务器当中。
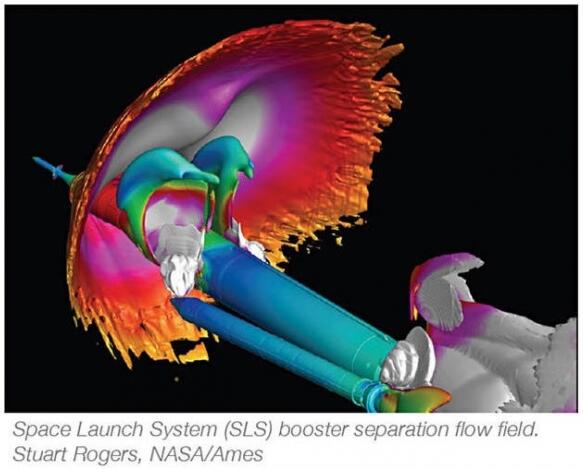
太空发射系统(简称SLS)可视化效果
临时性闪存
Excelero公司指出,在此用例之下,由于模拟数据在主Lustre文件系统内得到严格保护,因此256 TB虚拟设备尽管由非易失性介质构成,但仍可作为临时性存储资源使用。
因此无需对全部128台节点/设备进行RAID-0逻辑分卷串连即可实现数据保护。出于简化要求,该设备被附加至单一节点中,采用XFS文件系统并填充各类数据。该文件系统随后可随意以只读方式挂载及卸载于全部128个计算节点之上。
NVMesh逻辑块分卷可由集群化文件系统利用,亦可在遭遇主机或驱动器故障时受到良好保护。
延迟至关重要
这套NVMesh方案的加入会令数据访问延迟较本地NVMe驱动器延迟提升5微秒,大部分延迟由网络造成。
科学家与工程师不需要在编程层面限制数据位置; 各计算节点上的全部数据访问行为皆以本地方式实现。根据灵活IO测试工具(简称fio)给出的基准测试结果,全部128个节点皆可实现超过3000万随机4K读取IOPS。这一IOPS水平下的平均延迟为199微秒,而***值则为8微秒。1 MB数据块条件下的数据通量则为每秒140 GB。
Excelero公司指出,在利用原生NVMe队列机制时,这种方法能够完全回避目标主机CPU(配备有NVMe驱动器的主机)为应用程序预留处理资源的问题。
这一模拟结果意味着可视化任务的运行将更为顺畅快速,而美国宇航局艾姆斯研究中心的科学家与工程师们则可更加自然地完成交互,从而显著提升工作效率。
了解更多热点新闻,请关注51CTO《科技新闻早报》栏目!